AI 101
Kuinka kuvaluokittelu toimii?
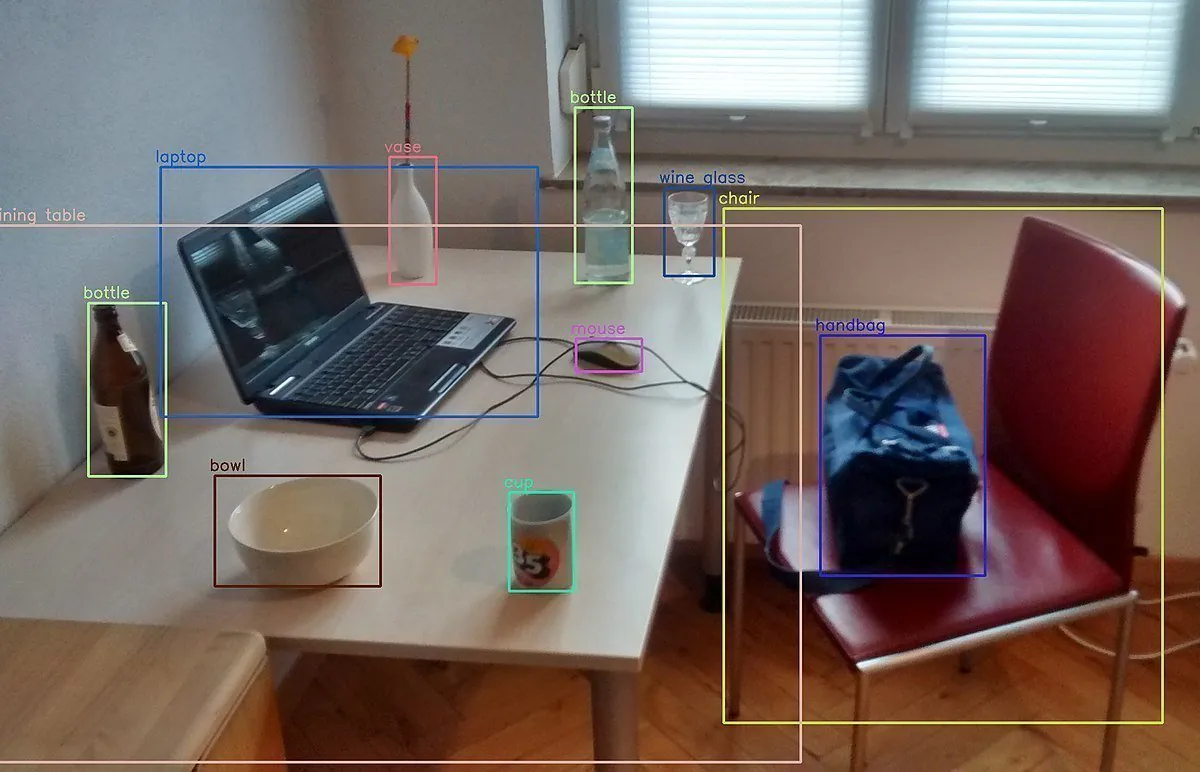
Miten puhelimesi voi määrittää, mikä objekti on, kun se ottaa valokuvan siitä? Miten sosiaalisen median sivustot voivat automaattisesti merkitä henkilöitä valokuvissa? Tämä on mahdollista tekoälypohjaisen kuvatunnistuksen ja luokittelun ansiosta.
Kuvien tunnistaminen ja luokittelu mahdollistaa monia tekoälyn vaikuttavimpia saavutuksia. Mutta miten tietokoneet oppivat havaitsemaan ja luokittelemaan kuvia? Tässä artikkelissa käsittelemme yleisiä menetelmiä, joita tietokoneet käyttävät kuvien tulkintaan ja havaitsemiseen, ja tarkastelemme joitain suosituimpia menetelmiä kuvien luokitteluun.
Pikselitaso vs. objektipohjainen luokittelu
Kuvaluokittelu voidaan jakaa kahteen eri kategoriaan: pikselipohjainen luokittelu ja objektipohjainen luokittelu.
Pikselit ovat kuvan perusyksikkö, ja pikselien analyysi on ensisijainen tapa, jolla kuvien luokittelu tehdään. Kuvien luokittelu algoritmit voivat kuitenkin käyttää joko pelkästään spektrinformatiota yksittäisistä pikseleistä luokitteluun tai tarkastella myös tilastotietoa (lähellä olevia pikseleitä) spektrinformaation lisäksi. Pikselipohjaiset luokittelu menetelmät käyttävät vain spektrinformatiota (pikselin intensiteetti), kun taas objektipohjaiset luokittelu menetelmät ottaa huomioon sekä pikselin spektrinformaation että tilastotiedon.
Pikselipohjaisessa luokittelussa on eri luokittelu menetelmiä. Nämä sisältävät etäisyyden keskiarvoon, todennäköisyyden maksimoinnin ja Mahalanobis-etäisyyden minimoinnin. Nämä menetelmät edellyttävät, että luokkien keskiarvot ja varianssit ovat tiedossa, ja ne toimivat tarkastelemalla “etäisyyttä” luokkien keskiarvojen ja kohdepikselien välillä.
Pikselipohjaiset luokittelu menetelmät ovat rajoittuneita siinä, että ne eivät voi käyttää tietoa muista lähellä olevista pikseleistä. Sen sijaan objektipohjaiset luokittelu menetelmät voivat sisältää muita pikseleitä ja siten käyttää tilastotietoa luokittelussa. Huomaa, että “objekti” viittaa vain yhtenäisiin pikseliryhmiin ja ei siihen, onko kohdeobjekti kyseisessä pikseliryhmässä.
Kuvien esikäsittely objektitunnistusta varten
Uusimmat ja luotettavimmat kuvien luokittelu järjestelmät käyttävät pääasiassa objektipohjaisia luokittelu menetelmiä, ja näissä lähestymistavoissa kuvadata on valmisteltava tietyllä tavalla. Objektit/alueet on valittava ja esikäsiteltävä.
Ennen kuin kuva ja sen sisältämät objektit/alueet voidaan luokitella, kuvan muodostavat tiedot on tulkittava tietokoneella. Kuvat on esikäsiteltävä ja valmisteltava luokittelu algoritmin syötteeksi, ja tämä tehdään objektitunnistuksen avulla. Tämä on tärkeä osa datan valmistelua ja kuvien valmistelua koneoppimisen luokittelijan koulutukseen.
Objektitunnistus tehdään erilaisin menetelmin ja tekniikoin. Aluksi vaikuttaa siihen, onko kiinnostuksen kohteena yksi vai useampi objekti, miten kuvan esikäsittelyä käsitellään. Jos on vain yksi objekti, josta on kiinnostusta, kuva käy läpi kuvan lokalisaation. Kuvan muodostavien pikselien numeeriset arvot tulkitaan tietokoneella ja käytetään näytön oikean värin ja sävyn näyttämiseen. Objekti, jota kutsutaan rajauslaatikoksi, piirretään objektiin, josta on kiinnostusta, mikä auttaa tietokonetta ymmärtämään, mikä osa kuvasta on tärkeää ja mitkä pikseliarvot määrittävät objektin. Jos kuvassa on useampi objekti, josta on kiinnostusta, käytetään objektitunnistusmenetelmää, jotta voidaan soveltaa näitä rajauslaatikoita kaikkiin kuvan objekteihin.

Kuva: Adrian Rosebrock via Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Intersection_over_Union_-_object_detection_bounding_boxes.jpg)
Toinen esikäsittelymenetelmä on kuvien segmentointi. Kuvien segmentointi toimii jakamalla koko kuvan segmentteihin, jotka perustuvat samankaltaisiin piirteisiin. Kuvan eri alueet ovat samankaltaisia pikseliarvoja verrattuna muihin kuvan alueisiin, joten nämä pikselit ryhmitellään yhteen kuvamaskien kanssa, jotka vastaavat objektien muotoa ja rajoja kuvassa. Kuvien segmentointi auttaa tietokonetta erottamaan kuvan piirteet, jotka auttavat luokittelussa, samoin kuin rajauslaatikot, mutta ne tarjoavat tarkemmat, pikselitasoiset merkinnät.
Kun objektitunnistus tai kuvien segmentointi on valmis, merkitään kyseisiin alueisiin. Nämä merkit ja pikseleistä muodostuvat arvot syötetään koneoppimisalgoritmeihin, jotka oppivat kuviin liittyvät mallit.
Koneoppimisalgoritmit
Kun data on valmisteltu ja merkitty, se syötetään koneoppimisalgoritmiin, joka koulutetaan datalla. Käsittelemme joitain yleisimpiä kuvien luokitteluun käytettäviä koneoppimisalgoritmeja alla.
K-Nearest Neighbors
K-Nearest Neighbors on luokittelu algoritmi, joka tarkastelee lähimmät koulutus esimerkit ja tarkastelee niiden merkitteitä, jotta voidaan määrittää todennäköisin merkki kohde esimerkille. Kuvien luokitteluun KNN: n kanssa koulutus kuvien ominaisuusvektorit ja merkit tallennetaan, ja vain ominaisuusvektori syötetään algoritmiin testauksen aikana. Koulutus- ja testaus ominaisuusvektorit verrataan toisiinsa samankaltaisuuden perusteella.
KNN-pohjaiset luokittelu algoritmit ovat erittäin yksinkertaisia, ja ne käsittelevät useita luokkia helposti. Kuitenkin KNN laskee samankaltaisuuden kaikkien ominaisuuksien perusteella. Tämä tarkoittaa, että se voi olla altis virheelliselle luokitteluun, kun se saa kuvia, joissa vain osa ominaisuuksista on tärkeää kuvan luokitteluun.
Tukeva vektori kone
Tukeva vektori kone on luokittelu menetelmä, joka asettaa pisteet avaruuteen ja piirtää jakavia viivoja pisteiden välille, asettaen objektit eri luokkiin sen mukaan, mille puolelle jakoviiva piste sijaitsee. Tukeva vektori kone pystyy tekemään epälineaarisia luokitteluja käyttämällä tekniikkaa, jota kutsutaan ydin temppuna. Vaikka SVM-luokittelijat ovat usein erittäin tarkkoja, niiden merkittävä haitta on, että ne ovat rajoittuneita sekä koossa että nopeudessa, ja nopeus kärsii, kun koko kasvaa.
Monikerroksiset perkatronit (neuraaliverkot)
Monikerroksiset perkatronit, joita kutsutaan myös neuraaliverkkomalleiksi, ovat koneoppimisalgoritmeja, jotka ovat inspiroituja ihmisaivoista. Monikerroksiset perkatronit koostuvat useista kerroksista, jotka ovat liitettynä toisiinsa, samoin kuin ihmisaivojen hermosolut ovat toisiinsa liitettynä. Neuraaliverkot tekevät oletuksia siitä, miten syöte ominaisuudet liittyvät datan luokkiin, ja nämä oletukset mukautuvat koulutuksen aikana. Yksinkertaiset neuraaliverkkomallit, kuten monikerroksinen perkatroni, pystyvät oppimaan epälineaarisia suhteita, ja tämän seurauksena ne voivat olla paljon tarkempia kuin muut mallit. Kuitenkin MLP-mallit kärsivät joistakin merkittävistä ongelmista, kuten epäkonveksien häviöfunktioiden läsnäolosta.
Syväoppimisalgoritmit (CNN:t)

Kuva: APhex34 via Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Typical_cnn.png)
Yleisin kuvien luokitteluun käytetty algoritmi nykyään on konvoluutio neuroverkko (CNN). CNN:t ovat mukautettuja versioita neuraaliverkoista, jotka yhdistävät monikerroksiset neuraaliverkot erityisiin kerroksiin, jotka pystyvät erottamaan kuvien tärkeimmät piirteet. CNN:t voivat automaattisesti löytää, luoda ja oppia kuvien piirteitä. Tämä vähentää tarvetta manuaaliseen kuvien merkintään ja segmentointiin koneoppimisalgoritmeja varten. Ne myös tarjoavat etua MLP-verkkoihin nähden, koska ne voivat käsitellä epäkonvekseja häviöfunktiota.
Convolutional Neuroverkot saavat nimensä siitä, että ne luovat “konvoluutioita”. CNN:t toimivat siirtämällä suotimen yli kuvaa. Voit ajatella tätä kuin maiseman katsomista siirrettävän ikkunan kautta, keskittyen vain niihin piirteisiin, jotka ovat näkyvissä ikkunassa kerran. Suodin sisältää numeerisia arvoja, jotka kerrotaan pikselien arvojen kanssa. Tuloksena on uusi kehys, tai matriisi, täynnä numeroita, jotka edustavat alkuperäistä kuvaa. Tämä prosessi toistetaan valitun määrän suotimien osalta, ja sitten kehykset yhdistetään yhteen uudeksi kuvaksi, joka on hieman pienempi ja yksinkertaisempi kuin alkuperäinen kuva. Tekniikkaa, jota kutsutaan poolingiksi, käytetään valitsemaan kuvan tärkeimmät arvot, ja convolutional kerrosten tavoitteena on lopulta erottaa kuvan merkittävimmät osat, jotka auttavat neuroverkkoa tunnistamaan kuvissa olevat objektit.
Convolutional Neuroverkot koostuvat kahteen eri osaan. Convolutional kerrokset ovat vastuussa kuvien piirteiden erottamisesta ja muuttamisesta formaatiksi, jota neuroverkon kerrokset voivat tulkita ja oppia. Varhaiset convolutional kerrokset ovat vastuussa kuvan perustavanlaatuisimpien elementtien erottamisesta, kuten yksinkertaisista viivoista ja rajoista. Keskitason convolutional kerrokset alkavat erottaa monimutkaisempia muotoja, kuten yksinkertaisia kaarteita ja kulmia. Myöhemmät, syvemmät convolutional kerrokset erottavat kuvan korkean tason piirteet, jotka syötetään neuroverkon osaan CNN: ssä, ja ne ovat se, mitä luokittelija oppii.












