Ángulo de Anderson
¿Por qué los ataques de imágenes adversarias no son una broma?
Atacar sistemas de reconocimiento de imágenes con imágenes adversarias cuidadosamente elaboradas ha sido considerado un concepto de prueba divertido pero trivial durante los últimos cinco años. Sin embargo, una nueva investigación de Australia sugiere que el uso casual de conjuntos de datos de imágenes muy populares para proyectos de inteligencia artificial comerciales podría crear un nuevo problema de seguridad duradero.
Hace un par de años, un grupo de académicos de la Universidad de Adelaide ha estado tratando de explicar algo muy importante sobre el futuro de los sistemas de reconocimiento de imágenes basados en inteligencia artificial.
Es algo que sería difícil (y muy costoso) solucionar ahora mismo, y que sería inconscientemente costoso de solucionar una vez que las tendencias actuales en la investigación de reconocimiento de imágenes se hayan desarrollado completamente en despliegues comercializados e industrializados en 5-10 años.
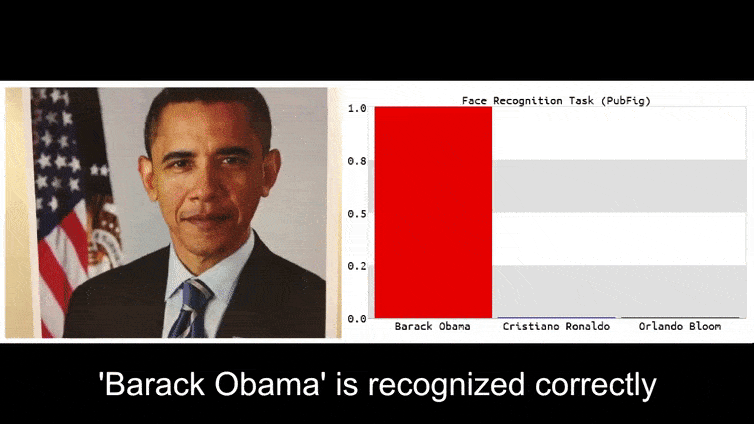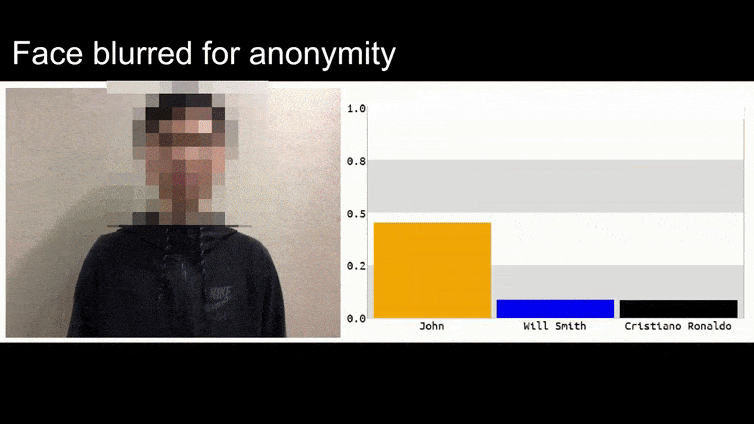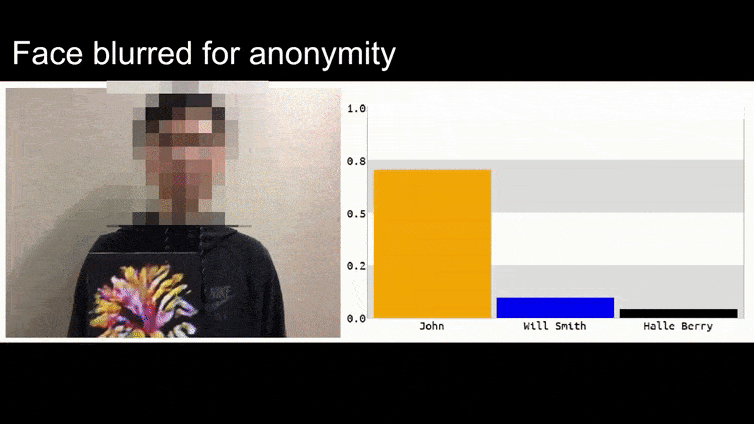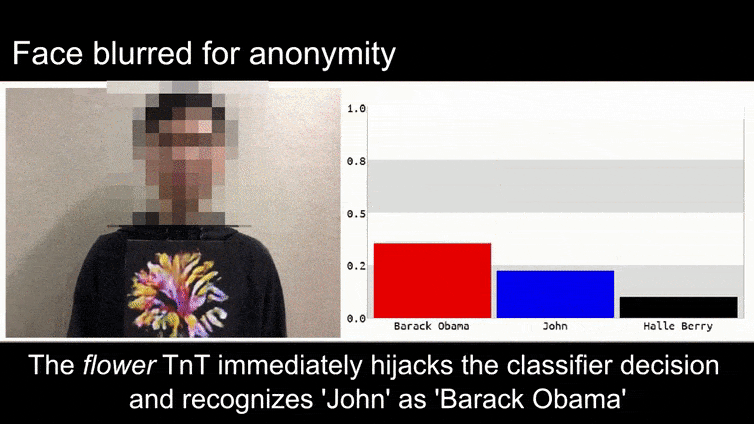
Antes de entrar en ello, veamos una flor que se clasifica como el presidente Barack Obama, de uno de los seis videos que el equipo ha publicado en la página del proyecto:
Fuente: https://www.youtube.com/watch?v=Klepca1Ny3c
En la imagen anterior, un sistema de reconocimiento facial que claramente sabe reconocer a Barack Obama es engañado con una certeza del 80% de que un hombre anónimo que sostiene una imagen adversaria impresa de una flor también es Barack Obama. El sistema ni siquiera se preocupa de que la “cara falsa” esté en el pecho del sujeto, en lugar de en sus hombros.
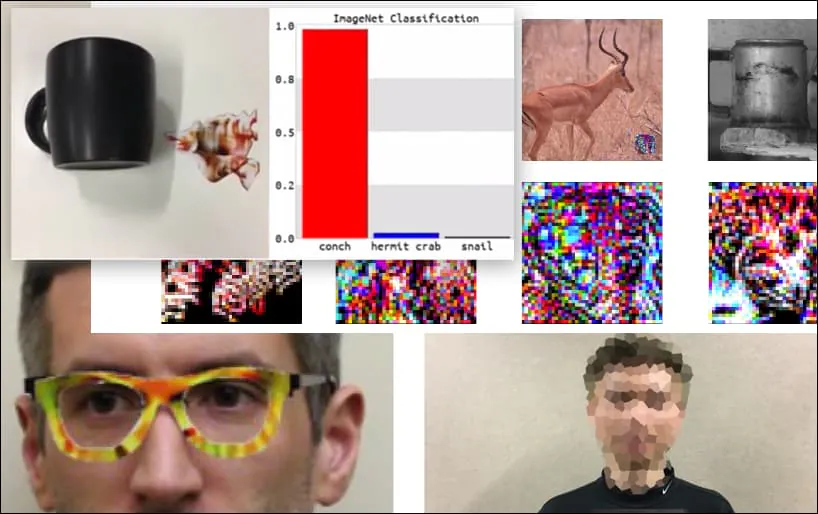
Aunque es impresionante que los investigadores hayan podido lograr este tipo de captura de identidad generando una imagen coherente (una flor) en lugar de solo ruido aleatorio, parece que este tipo de explotaciones tontas surgen con bastante frecuencia en la investigación de seguridad sobre visión por computadora. Por ejemplo, aquellos extraños anteojos con patrones que podían engañar el reconocimiento facial en 2016, o imágenes adversarias especialmente elaboradas que intentan reescribir señales de tráfico.
Si está interesado, el modelo de Red Neuronal Convolucional (CNN) que se ataca en el ejemplo anterior es VGGFace (VGG-16), entrenado en el conjunto de datos PubFig de la Universidad de Columbia. Otros ejemplos de ataques desarrollados por los investigadores utilizaron diferentes recursos en diferentes combinaciones.

Un teclado es reclasificado como un caracol, en un modelo WideResNet50 en ImageNet. Los investigadores también han asegurado que el modelo no tiene sesgo hacia los caracoles. Ver el video completo para demostraciones extendidas y adicionales en https://www.youtube.com/watch?v=dhTTjjrxIcU
El reconocimiento de imágenes como un vector de ataque emergente
Los muchos ataques impresionantes que los investigadores esbozan y ilustran no son críticas a conjuntos de datos individuales o arquitecturas de aprendizaje automático específicas que los utilizan. Tampoco pueden ser defendidos fácilmente cambiando conjuntos de datos o modelos, volviendo a entrenar modelos, o cualquier otro “remedio simple” que cause que los practicantes de aprendizaje automático se burlen de demostraciones esporádicas de este tipo de trucos.
Rather, los exploits del equipo de Adelaide ejemplifican una debilidad central en la arquitectura actual de desarrollo de inteligencia artificial de reconocimiento de imágenes; una debilidad que podría exponer a muchos sistemas de reconocimiento de imágenes futuros a una manipulación fácil por parte de atacantes, y poner a cualquier medida defensiva posterior en desventaja.
Imagínese que las últimas imágenes de ataques adversarios (como la flor anterior) se agregan como “exploits de día cero” a los sistemas de seguridad del futuro, al igual que los marcos de antivirus y antimalware actualizan sus definiciones de virus todos los días.
El potencial para nuevos ataques de imágenes adversarias sería inagotable, porque la arquitectura fundamental del sistema no anticipó problemas downstream, como ocurrió con Internet, el error del milenio y la torre inclinada de Pisa.
¿De qué manera, entonces, estamos preparando el escenario para esto?
Obteniendo los datos para un ataque
Las imágenes adversarias, como el ejemplo de la “flor” anterior, se generan teniendo acceso a los conjuntos de datos que entrenaron los modelos de computadora. No necesitas acceso “privilegiado” a los datos de entrenamiento (o arquitecturas de modelo), ya que los conjuntos de datos más populares (y muchos modelos entrenados) están ampliamente disponibles en una escena de torrents robusta y constantemente actualizada.
Por ejemplo, el gigante de los conjuntos de datos de visión por computadora, ImageNet, está disponible en torrent en todas sus muchas iteraciones, evitando sus restricciones habituales restricciones, y poniendo a disposición elementos secundarios cruciales, como conjuntos de validación.

Fuente: https://academictorrents.com
Si tienes los datos, puedes (como observan los investigadores de Adelaide) “reinvertir” cualquier conjunto de datos popular, como CityScapes o CIFAR.
En el caso de PubFig, el conjunto de datos que permitió la “flor de Obama” en el ejemplo anterior, la Universidad de Columbia ha abordado una tendencia creciente en problemas de derechos de autor alrededor de la redistribución de conjuntos de datos de imágenes, instruyendo a los investigadores sobre cómo reproducir el conjunto de datos a través de enlaces curados, en lugar de hacer la compilación directamente disponible, observando ‘Esto parece ser la forma en que otras bases de datos en línea grandes están evolucionando’.
En la mayoría de los casos, no es necesario: Kaggle estima que los diez conjuntos de datos de imágenes más populares en visión por computadora son: CIFAR-10 y CIFAR-100 (ambos directamente descargables); CALTECH-101 y 256 (ambos disponibles, y ambos actualmente disponibles como torrents); MNIST (oficialmente disponible, también en torrents); ImageNet (ver arriba); Pascal VOC (disponible, también en torrents); MS COCO (disponible, y en torrents); Sports-1M (disponible); y YouTube-8M (disponible).
Esta disponibilidad también es representativa de la gama más amplia de conjuntos de datos de visión por computadora disponibles, ya que la oscuridad es la muerte en una cultura de desarrollo de código abierto “publicar o perecer”.
En cualquier caso, la escasez de nuevos conjuntos de datos manejables, el alto costo del desarrollo de conjuntos de imágenes, la dependencia de “favoritos antiguos” y la tendencia a adaptar simplemente conjuntos de datos antiguos todos exacerbaban el problema esbozado en el nuevo artículo de Adelaide.
Críticas típicas de los métodos de ataque de imágenes adversarias
La crítica más frecuente y persistente de los ingenieros de aprendizaje automático contra la efectividad de la última técnica de ataque de imágenes adversarias es que el ataque es específico de un conjunto de datos particular, un modelo particular o ambos; que no es “generalizable” a otros sistemas; y, en consecuencia, representa solo una amenaza trivial.
La segunda crítica más frecuente es que el ataque de imágenes adversarias es ‘caja blanca’, lo que significa que necesitarías acceso directo al entorno de entrenamiento o a los datos. Esto es de hecho un escenario poco probable, en la mayoría de los casos – por ejemplo, si quisieras explotar el proceso de entrenamiento para los sistemas de reconocimiento facial de la policía metropolitana de Londres, tendrías que infiltrarte en NEC, ya sea con una consola o un hacha.
El ‘ADN’ a largo plazo de los conjuntos de datos de visión por computadora populares
En cuanto a la primera crítica, debemos considerar no solo que un puñado de conjuntos de datos de visión por computadora dominan la industria por sector año tras año (es decir, ImageNet para múltiples tipos de objetos, CityScapes para escenas de conducción y FFHQ para reconocimiento facial); sino también que, como datos de imágenes anotados simples, son “independientes de la plataforma” y altamente transferibles.
Dependiendo de sus capacidades, cualquier arquitectura de entrenamiento de visión por computadora encontrará algunas características de objetos y clases en el conjunto de datos ImageNet. Algunas arquitecturas pueden encontrar más características que otras, o hacer conexiones más útiles que otras, pero todas deben encontrar al menos las características de nivel más alto:

Datos de ImageNet, con el número mínimo viable de identificaciones correctas – características de ‘nivel alto’.
Esas características de “nivel alto” que distinguen y “fingerprint” a un conjunto de datos, y que son los “ganchos” confiables en los que se puede colgar una metodología de ataque de imágenes adversarias a largo plazo que puede abarcar diferentes sistemas, y crecer en tandem con el conjunto de datos “antiguo” a medida que se perpetúa en nuevos productos y investigaciones.
Una arquitectura más sofisticada producirá identificaciones más precisas y granulares, características y clases:

Sin embargo, cuanto más dependa un generador de ataques de imágenes adversarias de estas características de nivel más bajo (es decir, “hombre caucásico joven” en lugar de “cara”), menos efectivo será en sistemas de arquitectura posterior que utilicen versiones diferentes del conjunto de datos original – como un subconjunto o un conjunto de datos filtrado, donde muchas de las imágenes originales del conjunto de datos completo no están presentes:

Ataques adversarios en modelos preentrenados ‘zeroeados’
¿Qué pasa con los casos en los que simplemente descargas un modelo preentrenado que se entrenó originalmente en un conjunto de datos muy popular, y se le da datos completamente nuevos?
El modelo ya ha sido entrenado en (por ejemplo) ImageNet, y todo lo que queda son los pesos, que pueden haber tardado semanas o meses en entrenar, y que ahora están listos para ayudar a identificar objetos similares a los que existían en los datos originales (ahora ausentes).

Con los datos originales eliminados de la arquitectura de entrenamiento, lo que queda es la ‘predisposición’ del modelo para clasificar objetos de la manera en que originalmente aprendió a hacerlo, lo que esencialmente hará que muchas de las ‘firmas’ originales se reformen y se vuelvan vulnerables nuevamente a los mismos métodos de ataque de imágenes adversarias.
Esos pesos son valiosos. Sin los datos o los pesos, básicamente tienes una arquitectura vacía sin datos. Tendrás que entrenarla desde cero, a un gran costo de tiempo y recursos de computación, al igual que los autores originales lo hicieron (probablemente en hardware más potente y con un presupuesto más alto que el que tienes disponible).
El problema es que los pesos ya están bastante bien formados y resistentes. Aunque se adaptarán un poco en el entrenamiento, se comportarán de manera similar en tus nuevos datos como lo hicieron en los datos originales, produciendo características de firma que un sistema de ataque de imágenes adversarias puede utilizar.
A largo plazo, esto también preserva el ‘ADN’ de los conjuntos de datos de visión por computadora que tienen doce o más años, y que pueden haber pasado por una notable evolución desde esfuerzos de código abierto hasta despliegues comercializados – incluso cuando los datos de entrenamiento originales se eliminaron al comienzo del proyecto. Algunos de estos despliegues comercializados pueden no ocurrir hasta dentro de varios años.
No se necesita una caja blanca
En cuanto a la segunda crítica común de los sistemas de ataque de imágenes adversarias, los autores del nuevo artículo han encontrado que su capacidad para engañar a los sistemas de reconocimiento con imágenes elaboradas es altamente transferible a través de varias arquitecturas.
Al observar que su método “Universal NaTuralistic adversarial paTches” (TnT) es el primero en utilizar imágenes reconocibles (en lugar de ruido de perturbación aleatorio) para engañar a los sistemas de reconocimiento de imágenes, los autores también afirman:
‘[TnTs] son efectivos contra múltiples clasificadores de estado del arte que van desde el ampliamente utilizado WideResNet50 en la tarea de reconocimiento visual a gran escala de ImageNet dataset a VGG-face models en la tarea de reconocimiento facial de PubFig dataset en ambos ataques dirigidos y no dirigidos.
‘TnTs pueden poseer: i) la naturalidad que se puede lograr [con] desencadenantes utilizados en métodos de ataque de troyanos; y ii) la generalización y transferibilidad de ejemplos adversarios a otras redes.
‘Esto plantea preocupaciones de seguridad y seguridad con respecto a los DNN ya desplegados, así como a los despliegues de DNN futuros, donde los atacantes pueden utilizar parches de objetos naturales poco conspicuos para desviar sistemas de redes neuronales sin manipular el modelo y arriesgarse a ser descubiertos.’
Los autores sugieren que las contramedidas convencionales, como degradar la Precisión de un sistema, podrían proporcionar teóricamente alguna defensa contra los parches TnT, pero que ‘TnTs aún pueden bypassar esta defensa SOTA con la mayoría de los sistemas defensores que logran 0% de robustez’.
Posibles soluciones adicionales incluyen aprendizaje federado, donde la procedencia de las imágenes contribuyentes está protegida, y nuevos enfoques que podrían “encriptar” directamente los datos en el momento del entrenamiento, como uno recientemente sugerido por la Universidad de Aeronáutica y Astronáutica de Nanjing.
Incluso en esos casos, sería importante entrenar con datos de imágenes nuevos – ahora las imágenes y las anotaciones asociadas en el pequeño grupo de los conjuntos de datos de visión por computadora más populares están tan arraigadas en los ciclos de desarrollo en todo el mundo como para parecerse más a software que a datos; software que a menudo no ha sido notablemente actualizado en años.
Conclusión
Los ataques de imágenes adversarias están siendo posibles no solo por las prácticas de aprendizaje automático de código abierto, sino también por una cultura de desarrollo de inteligencia artificial empresarial que está motivada para reutilizar conjuntos de datos de visión por computadora bien establecidos por varias razones: ya han demostrado ser efectivos; son mucho más baratos que “empezar desde cero”; y están mantenidos y actualizados por mentes y organizaciones vanguardistas en academia e industria, a niveles de financiación y personal que serían difíciles de replicar para una sola empresa.
Además, en muchos casos donde los datos no son originales (a diferencia de CityScapes), las imágenes se recopilaron antes de las controversias recientes sobre prácticas de privacidad y recopilación de datos, lo que deja a estos conjuntos de datos antiguos en una especie de purgatorio semi-legal que puede parecerse a un “puerto seguro” desde la perspectiva de una empresa.
TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems es coautor por Bao Gia Doan, Minhui Xue, Ehsan Abbasnejad, Damith C. Ranasinghe de la Universidad de Adelaide, junto con Shiqing Ma del Departamento de Ciencias de la Computación de la Universidad de Rutgers.
Actualizado el 1 de diciembre de 2021, 7:06 a. m. GMT+2 – corregido error tipográfico.












