IA 101
¿Qué son RNNs y LSTMs en Deep Learning?
Muchos de los avances más impresionantes en el procesamiento del lenguaje natural y los chatbots de IA están impulsados por Redes Neuronales Recurrentes (RNNs) y Redes de Memoria a Corto Plazo (LSTM). Las RNNs y las LSTMs son arquitecturas de redes neuronales especiales que pueden procesar datos secuenciales, es decir, datos donde el orden cronológico es importante. Las LSTMs son esencialmente versiones mejoradas de las RNNs, capaces de interpretar secuencias de datos más largas. Veamos cómo están estructuradas las RNNs y las LSTMs y cómo permiten la creación de sistemas de procesamiento de lenguaje natural sofisticados.
¿Qué son las Redes Neuronales Feed-Forward?
Antes de hablar sobre cómo funcionan las Redes de Memoria a Corto Plazo (LSTM) y las Redes Neuronales Convolucionales (CNN), debemos discutir el formato de una red neuronal en general.
Una red neuronal está diseñada para examinar los datos y aprender patrones relevantes, para que estos patrones puedan ser aplicados a otros datos y nuevos datos puedan ser clasificados. Las redes neuronales se dividen en tres secciones: una capa de entrada, una capa oculta (o varias capas ocultas) y una capa de salida.
La capa de entrada es la que recibe los datos en la red neuronal, mientras que las capas ocultas son las que aprenden los patrones en los datos. Las capas ocultas en el conjunto de datos están conectadas a las capas de entrada y salida mediante “pesos” y “sesgos” que son solo suposiciones de cómo los puntos de datos están relacionados entre sí. Estos pesos se ajustan durante el entrenamiento. A medida que la red se entrena, las suposiciones del modelo sobre los datos de entrenamiento (los valores de salida) se comparan con las etiquetas de entrenamiento reales. Durante el curso del entrenamiento, la red debería (esperemos) volverse más precisa al predecir relaciones entre los puntos de datos, para que pueda clasificar nuevos puntos de datos con precisión. Las redes neuronales profundas son redes que tienen más capas en el medio/más capas ocultas. Cuantas más capas ocultas y más neuronas/nodos tenga el modelo, mejor podrá reconocer patrones en los datos.
Las redes neuronales feed-forward regulares, como las que he descrito anteriormente, a menudo se llaman “redes neuronales densas”. Estas redes neuronales densas se combinan con diferentes arquitecturas de red que se especializan en interpretar diferentes tipos de datos.
¿Qué son las RNNs (Redes Neuronales Recurrentes)?

Las Redes Neuronales Recurrentes toman el principio general de las redes neuronales feed-forward y les permiten manejar datos secuenciales dándoles al modelo una memoria interna. La parte “recurrente” del nombre de las RNNs proviene del hecho de que las entradas y salidas forman un bucle. Una vez que se produce la salida de la red, la salida se copia y se devuelve a la red como entrada. Al tomar una decisión, no solo se analizan la entrada y la salida actuales, sino que también se considera la entrada anterior. En otras palabras, si la entrada inicial para la red es X y la salida es H, tanto H como X1 (la siguiente entrada en la secuencia de datos) se alimentan a la red para la siguiente ronda de aprendizaje. De esta manera, se conserva el contexto de los datos (las entradas anteriores) a medida que la red se entrena.
El resultado de esta arquitectura es que las RNNs son capaces de manejar datos secuenciales. Sin embargo, las RNNs sufren de un par de problemas. Las RNNs sufren de los problemas de gradiente desvaneciente y gradiente explosivo.
La longitud de las secuencias que una RNN puede interpretar es bastante limitada, especialmente en comparación con las LSTMs.
¿Qué son las LSTMs (Redes de Memoria a Corto Plazo)?
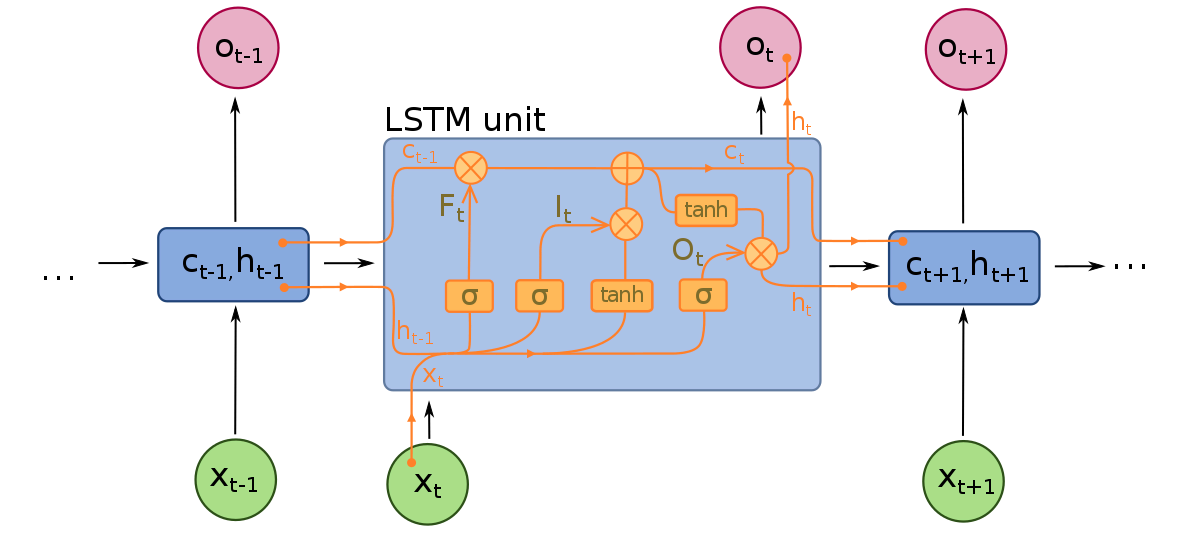
Las Redes de Memoria a Corto Plazo pueden considerarse extensiones de las RNNs, aplicando nuevamente el concepto de preservar el contexto de las entradas. Sin embargo, las LSTMs han sido modificadas de varias maneras importantes que les permiten interpretar datos pasados con métodos superiores. Las modificaciones hechas a las LSTMs tratan el problema del gradiente desvaneciente y permiten que las LSTMs consideren secuencias de entrada mucho más largas.

Los modelos LSTMs están compuestos por tres componentes diferentes, o compuertas. Hay una compuerta de entrada, una compuerta de salida y una compuerta de olvido. Al igual que las RNNs, las LSTMs toman en cuenta las entradas del tiempo de muestreo anterior al modificar la memoria del modelo y los pesos de entrada. La compuerta de entrada toma decisiones sobre qué valores son importantes y deben ser permitidos en el modelo. Se utiliza una función sigmoide en la compuerta de entrada, que toma decisiones sobre qué valores pasar a la red recurrente. Cero descarta el valor, mientras que 1 lo conserva. Se utiliza una función TanH aquí también, que decide cuán importante es el valor de entrada para el modelo, que va desde -1 a 1.
Después de que se tienen en cuenta las entradas y el estado de memoria actuales, la compuerta de salida decide qué valores pasar al siguiente tiempo de muestreo. En la compuerta de salida, los valores se analizan y se les asigna una importancia que va desde -1 a 1. Esto regula los datos antes de que se lleven a la siguiente calculación de tiempo de muestreo. Finalmente, el trabajo de la compuerta de olvido es descartar la información que el modelo considera innecesaria para tomar una decisión sobre la naturaleza de los valores de entrada. La compuerta de olvido utiliza una función sigmoide en los valores, que produce números entre 0 (olvidar esto) y 1 (conservar esto).
Una red neuronal LSTM está compuesta por capas LSTM especiales que pueden interpretar datos de palabras secuenciales y capas densamente conectadas como las descritas anteriormente. Una vez que los datos pasan por las capas LSTM, proceden a las capas densamente conectadas.








