Inteligencia Artificial
Fidelidad versus realismo en videos deepfake

No todos los practicantes de deepfake comparten el mismo objetivo: el ímpetu del sector de investigación de síntesis de imágenes, respaldado por defensores influyentes como Adobe, NVIDIA y Facebook – es avanzar en el estado del arte para que las técnicas de aprendizaje automático puedan eventualmente recrear o sintetizar la actividad humana en alta resolución y en las condiciones más desafiantes (fidelidad).
En cambio, el objetivo de quienes desean usar tecnologías deepfake para difundir desinformación es crear simulaciones plausibles de personas reales mediante métodos que van más allá de la mera veracidad de los rostros deepfakeados. En este escenario, factores complementarios como el contexto y la plausibilidad son casi equivalentes al potencial de un video para simular rostros. (realismo).
Este enfoque de "juego de manos" se extiende a la degradación de la calidad de la imagen final de un video deepfake, de modo que todo el video (y no solo la parte engañosa representada por una cara deepfake) tenga una "apariencia" cohesiva que sea precisa a la calidad esperada para el medio.
«Cohesivo» no tiene por qué ser sinónimo de «bueno»; basta con que la calidad sea consistente tanto en el contenido original como en el contenido adulterado insertado, y que cumpla con las expectativas. En cuanto a la salida de streaming VOIP en plataformas como Skype y Zoom, el listón puede ser notablemente bajo, con imágenes entrecortadas y entrecortadas, y una amplia gama de posibles artefactos de compresión, así como algoritmos de «suavizado» diseñados para reducir sus efectos, lo que en sí mismo constituye una serie adicional de efectos «no auténticos» que hemos aceptado como corolarios de las limitaciones y excentricidades de la transmisión en directo.
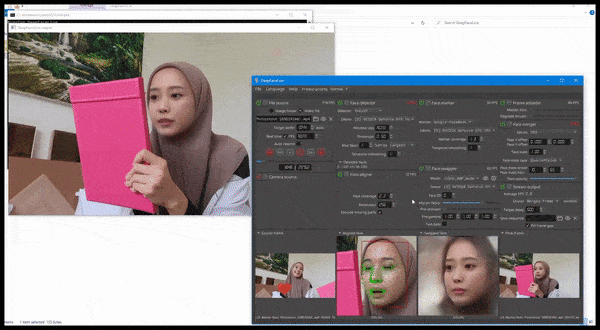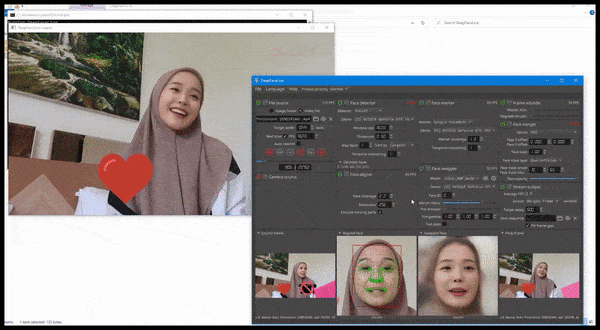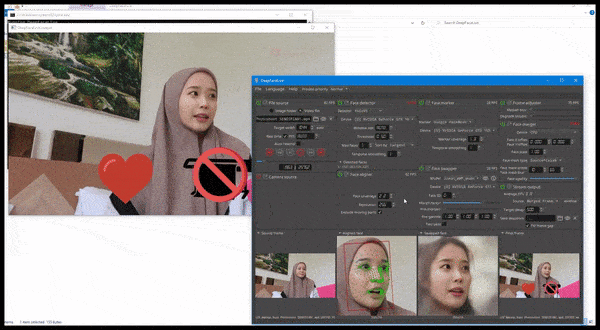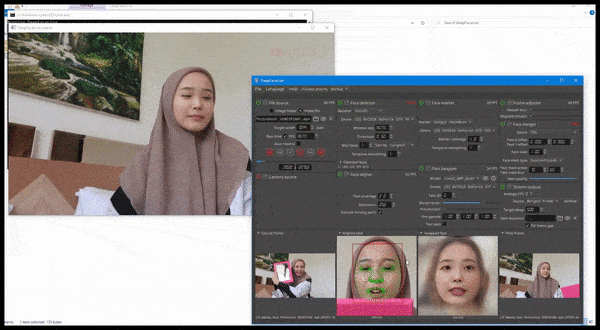
DeepFaceLive en acción: esta versión de transmisión del principal software de falsificación profunda DeepFaceLab puede proporcionar realismo contextual al presentar falsificaciones en el contexto de una calidad de video limitada, con problemas de reproducción y otros artefactos de conexión recurrentes. Fuente: https://www.youtube.com/watch?v=IL517EgYH8U
Degradación incorporada
De hecho, los dos paquetes deepfake más populares (ambos derivados del controvertido código fuente de 2017) contienen componentes destinados a integrar el rostro deepfake en el contexto de un video "histórico" o de menor calidad al degradar el rostro generado. ProfundoFaceLab, potencia_degradada_bicúbica parámetro logra esto, y en Intercambio caraLa configuración de 'grano' en Ffmpeg también ayuda a integrar la cara falsa al preservar el grano durante la codificación*.

La configuración de "grano" en FaceSwap facilita una integración auténtica con contenido de video que no es HQ y con contenido heredado que puede presentar efectos de grano de película que son relativamente raros en estos días.
A menudo, en lugar de un video deepfake completo e integrado, los deepfakers generarán una serie aislada de archivos PNG con canales alfa, cada imagen que muestra solo la salida de la cara sintética, de modo que el flujo de imágenes se pueda convertir en video en plataformas más sofisticadas.capacidades de efectos 'degradadores', como Adobe After Effects, antes de unir los elementos falsos y reales para el video final.
Además de estas degradaciones intencionales, el contenido del trabajo deepfake se recomprime con frecuencia, ya sea algorítmicamente (donde las plataformas de redes sociales buscan ahorrar ancho de banda al producir versiones más livianas de las cargas de los usuarios) en plataformas como YouTube y Facebook, o mediante el reprocesamiento del trabajo original en GIF animados, secciones de detalles u otros flujos de trabajo con diversas motivaciones que tratan el lanzamiento original como un punto de partida y, posteriormente, introducen una compresión adicional.
Contextos realistas de detección de falsificaciones profundas
Con esto en mente, un nuevo artículo de Suiza ha propuesto una renovación de la metodología detrás de los enfoques de detección de deepfake, al enseñar a los sistemas de detección a aprender las características del contenido de deepfake cuando se presenta en contextos degradados deliberadamente.

Aumento de datos estocásticos aplicado a uno de los conjuntos de datos utilizados en el nuevo documento, que presenta ruido gaussiano, corrección gamma y desenfoque gaussiano, así como artefactos de la compresión JPEG. Fuente: https://arxiv.org/pdf/2203.11807.pdf
En el nuevo artículo, los investigadores sostienen que los paquetes de detección de deepfakes de vanguardia se basan en condiciones de referencia poco realistas para el contexto de las métricas que aplican, y que los resultados de deepfakes "degradados" pueden caer por debajo del umbral de calidad mínimo para la detección, aunque su contenido "sucio" de manera realista probablemente engañe a los espectadores debido a una atención correcta al contexto.
Los investigadores han implementado un novedoso proceso de degradación de datos del mundo real que mejora la generalización de los principales detectores de deepfakes, con una pérdida mínima de precisión en las tasas de detección originales obtenidas con datos limpios. Además, ofrecen un nuevo marco de evaluación que permite evaluar la robustez de los detectores de deepfakes en condiciones reales, con el respaldo de amplios estudios de ablación.
La se titula Un nuevo enfoque para mejorar la detección de falsificaciones profundas basada en el aprendizaje en condiciones realistas, y proviene de investigadores del Multimedia Signal Processing Group (MMSPG) y la Ecole Polytechnique Federale de Lausanne (EPFL), ambos con sede en Lausana.
Confusión útil
Los esfuerzos anteriores para incorporar la salida degradada en los enfoques de detección de deepfake incluyen el Red neuronal mixta, una oferta de 2018 de MIT y FAIR, y AgoMix, una colaboración de 2020 entre DeepMind y Google, ambos métodos de aumento de datos que intentan "enturbiar" el material de capacitación de una manera que tiende a ayudar a la generalización.
Los investigadores del nuevo trabajo también señalan antes estudios que aplicó ruido gaussiano y artefactos de compresión a los datos de entrenamiento para establecer los límites de la relación entre una característica derivada y el ruido en el que está incrustada.
El nuevo estudio ofrece un proceso que simula las condiciones comprometidas tanto del proceso de adquisición de imágenes como de la compresión, y diversos algoritmos que pueden degradar aún más la salida de imágenes durante el proceso de distribución. Al incorporar este flujo de trabajo real en un marco de evaluación, es posible generar datos de entrenamiento para detectores de deepfakes más resistentes a los artefactos.

La lógica conceptual y el flujo de trabajo para el nuevo enfoque.
El proceso de degradación se aplicó a dos conjuntos de datos populares y exitosos utilizados para la detección de falsificaciones profundas: CaraForense++ y Celeb-DFv2. Además, los principales marcos de detectores de falsificaciones profundas Cápsula-forense y XceptionNet fueron entrenados en las versiones adulteradas de los dos conjuntos de datos.
Los detectores fueron entrenados con el optimizador Adam para 25 y 10 épocas respectivamente. Para la transformación del conjunto de datos, se tomaron muestras aleatorias de 100 cuadros de cada video de entrenamiento, con 32 cuadros extraídos para la prueba, antes de agregar los procesos de degradación.
Las distorsiones consideradas para el flujo de trabajo fueron ruido, donde se aplicó ruido gaussiano de media cero en seis niveles diferentes; cambio de tamaño, para simular la resolución reducida de las típicas tomas al aire libre, que pueden suelen afectar detectores; compresión, donde se aplicaron varios niveles de compresión JPEG a los datos; suavizar, donde se evalúan tres filtros de suavizado típicos utilizados para la 'eliminación de ruido' para el marco; Estrategias orientadas, donde se ajustaron el contraste y el brillo; y combinaciones, donde cualquier combinación de tres de los métodos antes mencionados se aplicó simultáneamente a una sola imagen.
Pruebas y resultados
Al probar los datos, los investigadores adoptaron tres métricas: Precisión (ACC); Área bajo la curva característica de funcionamiento del receptor (AUC); y Puntuación F1.
Los investigadores probaron las versiones estándar entrenadas de los dos detectores de falsificación profunda contra los datos adulterados y encontraron que carecían de ellos:
En general, la mayoría de las distorsiones y el procesamiento realistas son extremadamente perjudiciales para los detectores de deepfakes basados en aprendizaje y entrenados con normalidad. Por ejemplo, el método Capsule-Forensics muestra puntuaciones de AUC muy altas tanto en el conjunto de prueba FFpp sin comprimir como en el de Celeb-DFv2 tras el entrenamiento con los respectivos conjuntos de datos, pero luego sufre una drástica caída de rendimiento con los datos modificados de nuestro marco de evaluación. Se han observado tendencias similares con el detector XceptionNet.
Por el contrario, el rendimiento de los dos detectores mejoró notablemente al ser entrenados en los datos transformados, con cada detector ahora más capaz de detectar medios engañosos invisibles.
'El esquema de aumento de datos mejora significativamente la robustez de los dos detectores y mientras tanto aún mantienen un alto rendimiento en datos originales inalterados.'

Comparaciones de rendimiento entre los conjuntos de datos sin procesar y aumentados utilizados en los dos detectores de falsificación profunda evaluados en el estudio.
El artículo concluye:
'Los métodos de detección actuales están diseñados para lograr el mayor rendimiento posible en puntos de referencia específicos. Esto a menudo resulta en sacrificar la capacidad de generalización a escenarios más realistas. En este artículo, se propone un esquema de aumento de datos cuidadosamente concebido basado en el proceso natural de degradación de imágenes.
'Experimentos extensos muestran que esta técnica simple pero efectiva mejora significativamente la robustez del modelo frente a diversas distorsiones realistas y operaciones de procesamiento en flujos de trabajo de imágenes típicos'.
* Hacer coincidir el grano en la cara generada es una función de la transferencia de estilo durante el proceso de conversión.
Publicado por primera vez el 29 de marzo de 2022. Actualizado a las 8:33 p. m. EST para aclarar el uso de granos en Ffmpeg.












