Τεχνητή νοημοσύνη 101
Τι είναι το Overfitting;
Τι είναι το Overfitting;
Όταν εκπαιδεύετε ένα νευρωνικό δίκτυο, πρέπει να αποφύγετε το overfitting. Το overfitting είναι ένα ζήτημα μέσα στην μηχανική μάθηση και στα στατιστικά όπου ένα μοντέλο μαθαίνει τα πρότυπα ενός συνόλου δεδομένων εκπαίδευσης πολύ καλά, εξηγώντας τέλεια το σύνολο δεδομένων εκπαίδευσης αλλά αποτυγχάνει να γενικεύσει τη προβλεπτική του δύναμη σε άλλα σύνολα δεδομένων.
Για να το πούμε με άλλη τρόπο, στην περίπτωση ενός μοντέλου overfitting, συχνά εμφανίζει εξαιρετικά υψηλή ακρίβεια στο σύνολο δεδομένων εκπαίδευσης αλλά χαμηλή ακρίβεια στα δεδομένα που συλλέγονται και εκτελούνται στο μοντέλο στο μέλλον. Αυτό είναι μια γρήγορη ορισμό του overfitting, αλλά ας εξετάσουμε την έννοια του overfitting σε περισσότερες λεπτομέρειες. Ας δούμε πώς συμβαίνει το overfitting και πώς μπορεί να αποφευχθεί.
Κατανόηση του “Fit” και του Underfitting
Είναι χρήσιμο να εξετάσουμε την έννοια του underfitting και του “fit” γενικά όταν συζητάμε το overfitting. Όταν εκπαιδεύουμε ένα μοντέλο, προσπαθούμε να αναπτύξουμε ένα πλαίσιο που είναι ικανό να προβλέψει τη φύση ή την κατηγορία των στοιχείων σε ένα σύνολο δεδομένων, με βάση τα χαρακτηριστικά που περιγράφουν αυτά τα στοιχεία. Ένα μοντέλο πρέπει να είναι σε θέση να εξηγήσει ένα πρότυπο σε ένα σύνολο δεδομένων και να προβλέψει τις κατηγορίες των μελλοντικών σημείων δεδομένων με βάση αυτό το πρότυπο. Όσο το μοντέλο εξηγήσει καλύτερα τη σχέση μεταξύ των χαρακτηριστικών του συνόλου εκπαίδευσης, τόσο πιο “fit” είναι το μοντέλο μας.

Η μπλε γραμμή αντιπροσωπεύει τις προβλέψεις ενός μοντέλου που underfitting, ενώ η πράσινη γραμμή αντιπροσωπεύει ένα καλύτερο fit μοντέλο. Φωτογραφία: Pep Roca μέσω Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Ένα μοντέλο που εξηγήσει κακώς τη σχέση μεταξύ των χαρακτηριστικών των δεδομένων εκπαίδευσης και έτσι αποτυγχάνει να ταξινομήσει με ακρίβεια τα μελλοντικά παραδείγματα δεδομένων είναι underfitting τα δεδομένα εκπαίδευσης. Αν ήταν να γραφτεί η προβλεπόμενη σχέση ενός μοντέλου underfitting ενάντια στην πραγματική τομή των χαρακτηριστικών και των ετικετών, οι προβλέψεις θα απομακρύνθηκαν από το σημείο. Αν είχαμε ένα γράφημα με τις πραγματικές τιμές ενός συνόλου εκπαίδευσης με ετικέτες, ένα σοβαρά underfitting μοντέλο θα χάσει δραστικά τα περισσότερα από τα σημεία δεδομένων. Ένα μοντέλο με καλύτερο fit μπορεί να περάσει από το κέντρο των σημείων δεδομένων, με τα μεμονωμένα σημεία δεδομένων να είναι μακριά από τις προβλεπόμενες τιμές μόνο λίγο.
Το underfitting μπορεί συχνά να συμβεί όταν δεν υπάρχει επαρκής δεδομένα για να δημιουργηθεί ένα ακριβές μοντέλο, ή όταν προσπαθούμε να σχεδιάσουμε ένα γραμμικό μοντέλο με μη γραμμικά δεδομένα. Περισσότερα δεδομένα εκπαίδευσης ή περισσότερα χαρακτηριστικά θα μειώσουν συχνά το underfitting.
Γιατί δεν θα δημιουργήσουμε einfach ένα μοντέλο που εξηγήσει κάθε σημείο στο σύνολο δεδομένων εκπαίδευσης τέλεια; Βέβαια, η τέλεια ακρίβεια είναι επιθυμητή; Η δημιουργία ενός μοντέλου που έχει μάθει τα πρότυπα του συνόλου δεδομένων εκπαίδευσης πολύ καλά είναι αυτό που προκαλεί το overfitting. Το σύνολο δεδομένων εκπαίδευσης και άλλα, μελλοντικά σύνολα δεδομένων που θα εκτελεστούν στο μοντέλο δεν θα είναι ακριβώς τα ίδια. Θα είναι πιθανότατα πολύ παρόμοια σε πολλά аспектs, αλλά θα διαφέρουν και σε βασικούς τρόπους. Έτσι, η σχεδίαση ενός μοντέλου που εξηγήσει το σύνολο δεδομένων εκπαίδευσης τέλεια σημαίνει ότι θα λάβετε μια θεωρία για τη σχέση μεταξύ των χαρακτηριστικών που δεν γενικεύεται καλά σε άλλα σύνολα δεδομένων.
Κατανόηση του Overfitting
Το overfitting συμβαίνει όταν ένα μοντέλο μαθαίνει τις λεπτομέρειες μέσα στο σύνολο δεδομένων εκπαίδευσης πολύ καλά, προκαλώντας στο μοντέλο να υποφέρει όταν γίνονται προβλέψεις σε εξωτερικά δεδομένα. Αυτό μπορεί να συμβεί όταν το μοντέλο όχι μόνο μαθαίνει τα χαρακτηριστικά του συνόλου δεδομένων, αλλά και μαθαίνει τυχαίες διακυμάνσεις ή θόρυβο μέσα στο σύνολο δεδομένων, δίνοντας σημασία σε αυτές τις τυχαίες/μη σημαντικές εμφανίσεις.
Το overfitting είναι πιο πιθανό να συμβεί όταν χρησιμοποιούνται μη γραμμικά μοντέλα, καθώς είναι πιο ευέλικτα όταν μαθαίνουν τα χαρακτηριστικά των δεδομένων. Μη παραμετρικά αλγόριθμοι μηχανικής μάθησης συχνά έχουν διάφορους παραμέτρους και τεχνικές που μπορούν να εφαρμοστούν για να περιορίσουν την ευαισθησία του μοντέλου στα δεδομένα και έτσι να μειώσουν το overfitting. Για παράδειγμα, μοντέλα δέντρου αποφάσεων είναι εξαιρετικά ευαίσθητα στο overfitting, αλλά μια τεχνική που ονομάζεται pruning μπορεί να χρησιμοποιηθεί για να αφαιρέσει τυχαία κάποια από τα λεπτομέρειες που έχει μάθει το μοντέλο.
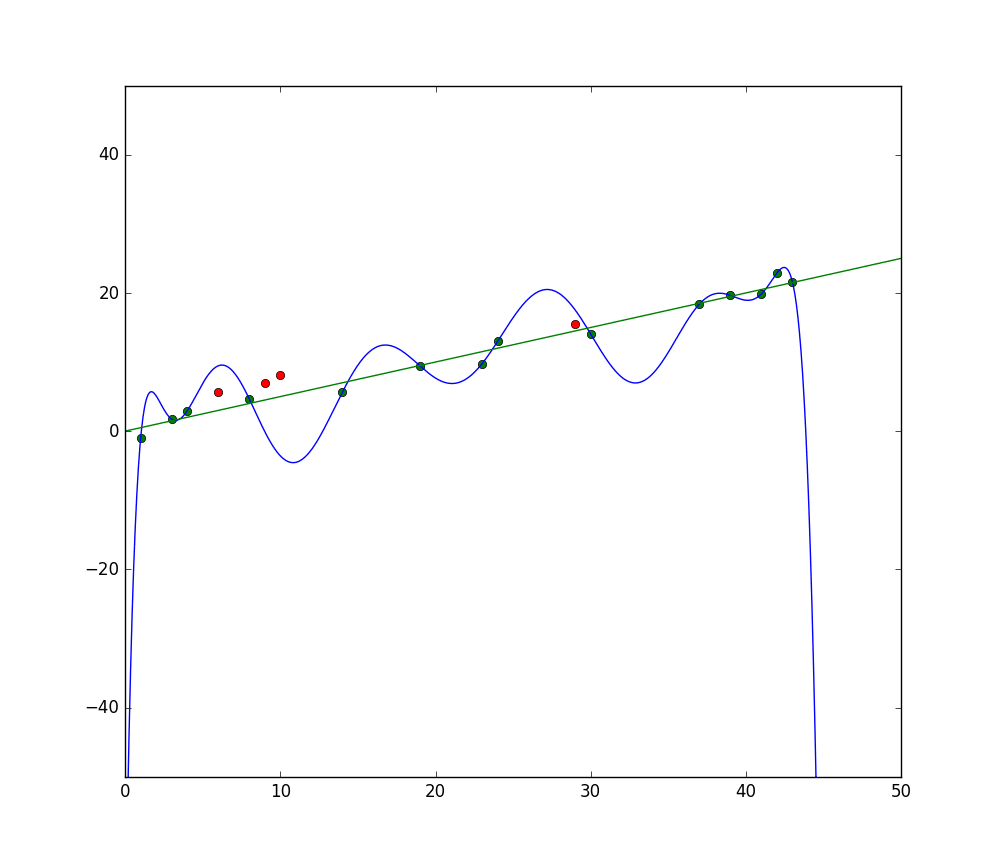
Αν ήταν να γράψουμε τις προβλέψεις του μοντέλου σε άξονες X και Y, θα είχαμε μια γραμμή προβλέψεων που zigzags πίσω και μπροστά, που αντικατοπτρίζει το γεγονός ότι το μοντέλο έχει προσπαθήσει πολύ για να ταιριάξει όλα τα σημεία στο σύνολο δεδομένων στην εξήγησή του.
Έλεγχος του Overfitting
Όταν εκπαιδεύουμε ένα μοντέλο, ιδανικά θέλουμε το μοντέλο να μην κάνει κανένα λάθος. Όταν η απόδοση του μοντέλου συγκλίνει προς την πραγματοποίηση σωστών προβλέψεων σε όλα τα σημεία δεδομένων στο σύνολο εκπαίδευσης, το fit γίνεται καλύτερο. Ένα μοντέλο με καλό fit είναι σε θέση να εξηγήσει σχεδόν όλα τα σύνολο δεδομένων εκπαίδευσης χωρίς overfitting.
Καθώς το μοντέλο εκπαιδεύεται, η απόδοσή του βελτιώνεται με τον καιρό. Το ποσοστό λάθους του μοντέλου θα μειωθεί καθώς περνά ο καιρός εκπαίδευσης, αλλά μειώνεται μόνο μέχρι ένα σημείο. Το σημείο στο οποίο η απόδοση του μοντέλου στο σύνολο δοκιμής αρχίζει να αυξάνεται και πάλι είναι συνήθως το σημείο στο οποίο συμβαίνει το overfitting. Για να πάρουμε το καλύτερο fit για ένα μοντέλο, θέλουμε να σταματήσουμε την εκπαίδευση του μοντέλου στο σημείο του χαμηλότερου λάθους στο σύνολο εκπαίδευσης, πριν αρχίσει να αυξάνεται και πάλι το λάθος. Το βέλτιστο σημείο διακοπής μπορεί να καθοριστεί με τη γραφική απεικόνιση της απόδοσης του μοντέλου καθ’ όλη τη διάρκεια της εκπαίδευσης και τη διακοπή της εκπαίδευσης όταν το λάθος είναι το χαμηλότερο. Ωστόσο, ένα ρίσκο με αυτή τη μέθοδο ελέγχου του overfitting είναι ότι η καθορισμός του τελικού σημείου της εκπαίδευσης με βάση την απόδοση δοκιμής σημαίνει ότι τα δεδομένα δοκιμής γίνονται κάπως μέρος της διαδικασίας εκπαίδευσης και χάνουν την κατάστασή τους ως “ακατάπαυστα” δεδομένα.
Υπάρχουν μερικοί διαφορετικοί τρόποι με τους οποίους μπορείτε να καταπολεμήσετε το overfitting. Ένας τρόπος μείωσης του overfitting είναι να χρησιμοποιήσετε μια τακτική επανειλημμένων δειγμάτων, η οποία λειτουργεί με την εκτίμηση της ακρίβειας του μοντέλου. Μπορείτε επίσης να χρησιμοποιήσετε ένα σύνολο επικύρωσης εκτός από το σύνολο δοκιμής και να σχεδιάσετε την ακρίβεια εκπαίδευσης ενάντια στο σύνολο επικύρωσης αντί του συνόλου δοκιμής. Αυτό διατηρεί το σύνολο δοκιμής σας αόρατο. Μια δημοφιλής μέθοδος επανειλημμένων δειγμάτων είναι η διασταύρωση K-fold. Αυτή η τεχνική σας επιτρέπει να διαιρέσετε τα δεδομένα σας σε υποσύνολα στα οποία το μοντέλο εκπαιδεύεται και στη συνέχεια η απόδοση του μοντέλου στα υποσύνολα αναλύεται για να εκτιμηθεί πώς θα εκτελεστεί το μοντέλο σε εξωτερικά δεδομένα.
Η χρήση της διασταύρωσης είναι ένας από τους καλύτερους τρόπους για να εκτιμήσετε την ακρίβεια του μοντέλου σας σε αόρατα δεδομένα και όταν συνδυαστεί με ένα σύνολο επικύρωσης, το overfitting μπορεί συχνά να giữται στο ελάχιστο.








