Künstliche Intelligenz
So trainieren und verwenden Sie Hunyuan Video-LoRA-Modelle

Dieser Artikel zeigt Ihnen, wie Sie Windows-basierte Software installieren und verwenden, die trainieren kann Hunyuan-Video-LoRA-Modelle, sodass der Benutzer benutzerdefinierte Persönlichkeiten im Hunyuan Video-Grundmodell generieren kann:
Anklicken um abzuspielen. Beispiele aus der jüngsten Explosion prominenter Hunyuan-LoRAs aus der civit.ai-Community.
Derzeit sind die beiden beliebtesten Möglichkeiten zur lokalen Generierung von Hunyuan-LoRA-Modellen:
1) Die diffusion-pipe-ui Docker-basiertes Framework, die sich darauf stützt Windows-Subsystem für Linux (WSL), um einige der Prozesse abzuwickeln.
2) Musubi-Tuner, eine neue Ergänzung zu den beliebten Kohya ss Diffusionstrainingsarchitektur. Musubi Tuner erfordert kein Docker und ist nicht von WSL oder anderen Linux-basierten Proxys abhängig – es kann jedoch schwierig sein, ihn unter Windows zum Laufen zu bringen.
Daher liegt der Schwerpunkt dieses Durchlaufs auf Musubi Tuner und auf der Bereitstellung einer vollständig lokalen Lösung für das Training und die Generierung von Hunyuan LoRA ohne die Verwendung von API-gesteuerten Websites oder kommerziellen GPU-Mietprozessen wie Runpod.
Anklicken um abzuspielen. Beispiele aus dem LoRA-Training auf Musubi Tuner für diesen Artikel. Alle Berechtigungen wurden von der abgebildeten Person zum Zwecke der Illustration dieses Artikels erteilt.
VORAUSSETZUNGEN
Für die Installation ist mindestens ein Windows 10-PC mit einer NVIDIA-Karte der 30+/40+-Serie erforderlich, die mindestens 12 GB VRAM hat (16 GB werden jedoch empfohlen). Die für diesen Artikel verwendete Installation wurde auf einem Computer mit 64 GB getestet. System RAM und eine NVIDIA 3090-Grafikkarte mit 24 GB VRAM. Es wurde auf einem dedizierten Testsystem mit einer Neuinstallation von Windows 10 Professional auf einer Partition mit über 600 GB freiem Festplattenspeicher getestet.
WARNUNG
Die Installation von Musubi Tuner und seinen Voraussetzungen erfordert auch die Installation von entwicklerorientierter Software und Paketen direkt auf der Haupt-Windows-Installation eines PCs. Unter Berücksichtigung der Installation von ComfyUI für die Endphasen wird dieses Projekt etwa 400-500 Gigabyte Festplattenspeicher benötigen. Obwohl ich das Verfahren mehrmals ohne Zwischenfälle in neu installierten Testumgebungen mit Windows 10 getestet habe, haften weder ich noch unite.ai für Systemschäden, die durch das Befolgen dieser Anweisungen entstehen. Ich rate Ihnen, alle wichtigen Daten zu sichern, bevor Sie diese Art von Installationsverfahren versuchen.
Überlegungen
Ist diese Methode noch gültig?
Die Szene der generativen KI entwickelt sich sehr schnell und wir können dieses Jahr bessere und optimierte Methoden der Hunyuan Video LoRA-Frameworks erwarten.
…oder sogar diese Woche! Während ich diesen Artikel schrieb, produzierte der Entwickler von Kohya/Musubi Musubi-Tuner-GUI, eine ausgeklügelte Gradio-GUI für Musubi Tuner:

Offensichtlich ist eine benutzerfreundliche GUI den BAT-Dateien vorzuziehen, die ich in dieser Funktion verwende – sobald musubi-tuner-gui funktioniert. Während ich dies schreibe, ist es erst vor fünf Tagen online gegangen und ich kann keinen Bericht darüber finden, dass es jemand erfolgreich verwendet hat.
Laut Beiträgen im Repository soll die neue GUI so schnell wie möglich direkt in das Musubi-Tuner-Projekt integriert werden, wodurch ihre derzeitige Existenz als eigenständiges GitHub-Repository beendet wird.
Basierend auf den vorliegenden Installationsanweisungen wird die neue GUI direkt in die vorhandene virtuelle Musubi-Umgebung geklont; und trotz vieler Bemühungen gelingt es mir nicht, sie mit der vorhandenen Musubi-Installation zu verknüpfen. Das bedeutet, dass sie beim Ausführen feststellen wird, dass sie keine Engine hat!
Sobald die GUI in Musubi Tuner integriert ist, werden Probleme dieser Art sicherlich gelöst sein. Obwohl der Autor räumt ein, dass das neue Projekt „wirklich hart“ istEr ist optimistisch, was die Entwicklung und direkte Integration in Musubi Tuner angeht.
Angesichts dieser Probleme (auch im Hinblick auf die Standardpfade zur Installationszeit und die Verwendung des UV-Python-Paket, was bestimmte Verfahren in der neuen Version komplizierter macht), müssen wir wahrscheinlich noch etwas auf ein reibungsloseres Hunyuan Video LoRA-Trainingserlebnis warten. Trotzdem sieht es sehr vielversprechend aus!
Aber wenn Sie nicht warten können und bereit sind, die Ärmel hochzukrempeln, können Sie das Hunyuan-Video-LoRA-Training jetzt gleich vor Ort durchführen.
Lass uns anfangen.
Warum installieren? Etwas auf Bare Metal?
(Überspringen Sie diesen Absatz, wenn Sie kein fortgeschrittener Benutzer sind)
Fortgeschrittene Benutzer werden sich fragen, warum ich mich dafür entschieden habe, so viel Software auf der Bare-Metal-Windows-10-Installation zu installieren, anstatt in einer virtuellen Umgebung. Der Grund dafür ist, dass der wesentliche Windows-Port des Linux-basierten Triton-Paket ist in einer virtuellen Umgebung weitaus schwieriger zum Laufen zu bringen. Alle anderen Bare-Metal-Installationen im Tutorial konnten nicht in einer virtuellen Umgebung installiert werden, da sie direkt mit der lokalen Hardware verbunden werden müssen.
Installieren erforderlicher Pakete und Programme
Bei den Programmen und Paketen, die zunächst installiert werden müssen, ist die Reihenfolge der Installation wichtig. Lassen Sie uns beginnen.
1: Laden Sie Microsoft Redistributable herunter
Laden Sie das Microsoft Redistributable-Paket herunter und installieren Sie es von https://aka.ms/vs/17/release/vc_redist.x64.exe.
Die Installation ist unkompliziert und schnell.

2: Installieren Sie Visual Studio 2022
Laden Sie die Microsoft Visual Studio 2022 Community Edition herunter von https://visualstudio.microsoft.com/downloads/?cid=learn-onpage-download-install-visual-studio-page-cta
Starten Sie das heruntergeladene Installationsprogramm:

Wir benötigen nicht jedes verfügbare Paket, da dies eine schwere und langwierige Installation bedeuten würde. Arbeitsauslastungen Seite, die geöffnet wird, aktivieren Sie Desktop-Entwicklung mit C++ (siehe Bild unten).

Klicken Sie nun auf Einzelkomponenten oben links auf der Benutzeroberfläche und verwenden Sie das Suchfeld, um nach „Windows SDK“ zu suchen.

Standardmäßig ist nur die Windows 11-SDK ist angekreuzt. Wenn Sie Windows 10 verwenden (diese Installationsprozedur wurde von mir nicht unter Windows 11 getestet), kreuzen Sie die neueste Windows 10-Version an, die im Bild oben angegeben ist.
Suchen Sie nach 'C++ CMake' und überprüfen Sie, ob C++ CMake-Tools für Windows wird geprüft.

Diese Installation benötigt mindestens 13 GB Speicherplatz.

Sobald Visual Studio installiert ist, wird versucht, es auf Ihrem Computer auszuführen. Lassen Sie es vollständig geöffnet. Wenn die Vollbildoberfläche von Visual Studio schließlich sichtbar ist, schließen Sie das Programm.
3: Installieren Sie Visual Studio 2019
Einige der nachfolgenden Pakete für Musubi setzen eine ältere Version von Microsoft Visual Studio voraus, während andere eine neuere benötigen.
Laden Sie sich daher auch die kostenlose Community Edition von Visual Studio 19 entweder bei Microsoft herunter (https://visualstudio.microsoft.com/vs/older-downloads/ – Konto erforderlich) oder Techspot (https://www.techspot.com/downloads/7241-visual-studio-2019.html).
Installieren Sie es mit den gleichen Optionen wie für Visual Studio 2022 (siehe Verfahren oben, außer dass Windows SDK ist im Visual Studio 2019-Installationsprogramm bereits aktiviert).
Sie werden feststellen, dass das Installationsprogramm von Visual Studio 2019 die neuere Version bereits während der Installation erkennt:

Wenn die Installation abgeschlossen ist und Sie die installierte Visual Studio 2019-Anwendung geöffnet und geschlossen haben, öffnen Sie eine Windows-Eingabeaufforderung (Geben Sie CMD in Suche starten) und geben Sie Folgendes ein und drücken Sie die Eingabetaste:
where cl
Das Ergebnis sollten die bekannten Speicherorte der beiden installierten Visual Studio-Editionen sein.

Wenn Sie stattdessen INFO: Could not find files for the given pattern(s)Finden Sie in der Pfad prüfen dieses Artikels weiter unten und verwenden Sie diese Anweisungen, um die relevanten Visual Studio-Pfade zur Windows-Umgebung hinzuzufügen.
Speichern Sie alle vorgenommenen Änderungen gemäß den Pfade prüfen Abschnitt weiter unten und versuchen Sie es dann erneut mit dem Befehl „where cl“.
4: Installieren Sie CUDA 11 + 12 Toolkits
Die verschiedenen in Musubi installierten Pakete benötigen unterschiedliche Versionen von NVIDIA CUDA, welches das Training auf NVIDIA-Grafikkarten beschleunigt und optimiert.
Der Grund, warum wir die Visual Studio-Versionen installiert haben zuerst besteht darin, dass die NVIDIA CUDA-Installationsprogramme nach vorhandenen Visual Studio-Installationen suchen und sich in diese integrieren.
Laden Sie ein CUDA-Installationspaket der Serie 11+ herunter von:
https://developer.nvidia.com/cuda-11-8-0-download-archive?target_os=Windows&target_arch=x86_64&target_version=11&target_type=exe_local (download „exe (lokal“) )
Laden Sie ein CUDA Toolkit-Installationspaket der Serie 12+ herunter von:
https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64
Der Installationsvorgang ist für beide Installer identisch. Ignorieren Sie alle Warnungen über das Vorhandensein oder Nichtvorhandensein von Installationspfaden in Windows-Umgebungsvariablen – wir werden uns später manuell darum kümmern.
Installieren Sie NVIDIA CUDA Toolkit V11+
Starten Sie das Installationsprogramm für das CUDA Toolkit der Serie 11+.


At Installationsoptionen, wählen Benutzerdefiniert (Erweitert) und fortfahren.

Deaktivieren Sie die Option NVIDIA GeForce Experience und klicken Sie auf Next.

Verlassen Installationsort auswählen bei den Voreinstellungen (das ist wichtig):

Klicken Sie Next und lassen Sie die Installation abschließen.

Ignorieren Sie alle Warnungen oder Hinweise des Installers über Nsight Visual Studio Integration, die für unseren Anwendungsfall nicht erforderlich ist.
Installieren Sie NVIDIA CUDA Toolkit V12+
Wiederholen Sie den gesamten Vorgang für das separate 12+ NVIDIA Toolkit-Installationsprogramm, das Sie heruntergeladen haben:

Der Installationsvorgang für diese Version ist identisch mit dem oben aufgeführten (Version 11+), mit Ausnahme einer Warnung bezüglich Umgebungspfaden, die Sie ignorieren können:

Wenn die Installation der CUDA-Version 12+ abgeschlossen ist, öffnen Sie eine Eingabeaufforderung in Windows und geben Sie Folgendes ein:
nvcc --version
Dies sollte die Informationen zur installierten Treiberversion bestätigen:

Um zu überprüfen, ob Ihre Karte erkannt wird, geben Sie Folgendes ein:
nvidia-smi

5: Installieren Sie GIT
GIT übernimmt die Installation des Musubi-Repositorys auf Ihrem lokalen Computer. Laden Sie das GIT-Installationsprogramm herunter unter:
https://git-scm.com/downloads/win ('64-Bit-Git für Windows-Setup')

Führen Sie das Installationsprogramm aus:

Standardeinstellungen verwenden für Wählen Sie Komponenten aus:
Belassen Sie den Standard-Editor bei Vim:

Lassen Sie GIT über die Zweignamen entscheiden:

Verwenden Sie empfohlene Einstellungen für die Path Umwelt:

Verwenden Sie empfohlene Einstellungen für SSH:

Verwenden Sie empfohlene Einstellungen für HTTPS-Transport-Backend:
Verwenden Sie die empfohlenen Einstellungen für Zeilenende-Konvertierungen:

Wählen Sie die Windows-Standardkonsole als Terminalemulator:
Standardeinstellungen verwenden (Schneller Vorlauf oder Zusammenführen) für Git Pull:

Verwenden Sie Git-Credential Manager (die Standardeinstellung) für Credential Helper:

In Konfigurieren zusätzlicher Optionen, verlassen Dateisystem-Caching aktivieren angekreuzt, und Symbolische Links aktivieren nicht angekreuzt (es sei denn, Sie sind ein fortgeschrittener Benutzer, der Hardlinks für ein zentrales Modell-Repository verwendet).

Schließen Sie die Installation ab und testen Sie, ob Git ordnungsgemäß installiert ist, indem Sie ein CMD-Fenster öffnen und Folgendes eingeben:
git --version

GitHub-Anmeldung
Wenn Sie später versuchen, GitHub-Repositorys zu klonen, werden Sie möglicherweise nach Ihren GitHub-Anmeldeinformationen gefragt. Um dies zu verhindern, melden Sie sich in allen auf Ihrem Windows-System installierten Browsern bei Ihrem GitHub-Konto an (erstellen Sie ggf. eines). Auf diese Weise sollte die 0Auth-Authentifizierungsmethode (ein Popup-Fenster) so wenig Zeit wie möglich in Anspruch nehmen.
Nach dieser ersten Herausforderung sollten Sie automatisch authentifiziert bleiben.
6: CMake installieren
Für Teile des Musubi-Installationsprozesses ist CMake 3.21 oder neuer erforderlich. CMake ist eine plattformübergreifende Entwicklungsarchitektur, die verschiedene Compiler orchestrieren und Software aus dem Quellcode kompilieren kann.
Laden Sie es herunter unter:
https://cmake.org/download/ ('Windows x64-Installer')
Starten Sie das Installationsprogramm:

Gewährleisten Fügen Sie Cmake zur Umgebungsvariable PATH hinzu wird geprüft.

Presse Next.

Geben Sie diesen Befehl in eine Windows-Eingabeaufforderung ein:
cmake --version
Wenn CMake erfolgreich installiert wurde, wird etwa Folgendes angezeigt:
cmake version 3.31.4
CMake suite maintained and supported by Kitware (kitware.com/cmake).

7: Installieren Sie Python 3.10
Der Python-Interpreter ist für dieses Projekt von zentraler Bedeutung. Laden Sie die Version 3.10 (der beste Kompromiss zwischen den unterschiedlichen Anforderungen der Musubi-Pakete) herunter unter:
https://www.python.org/downloads/release/python-3100/ ('Windows-Installer (64-Bit)')
Führen Sie das Download-Installationsprogramm aus und belassen Sie die Standardeinstellungen:

Klicken Sie am Ende des Installationsvorgangs auf Deaktivieren der Pfadlängenbeschränkung (erfordert UAC-Administratorbestätigung):

Geben Sie in einer Windows-Eingabeaufforderung Folgendes ein:
python --version
Dies sollte dazu führen, Python 3.10.0

Pfade prüfen
Das Klonen und Installieren des Musubi-Frameworks sowie dessen normaler Betrieb nach der Installation erfordern, dass seine Komponenten den Pfad zu mehreren wichtigen externen Komponenten in Windows kennen, insbesondere CUDA.
Daher müssen wir die Pfadumgebung öffnen und überprüfen, ob alle Voraussetzungen vorhanden sind.
Um schnell zu den Steuerelementen für die Windows-Umgebung zu gelangen, geben Sie Folgendes ein: Bearbeiten Sie die Systemumgebungsvariablen in die Windows-Suchleiste.

Ein Klick darauf öffnet das System Properties Bedienfeld. Unten rechts System Properties, drücke den Umgebungsvariablen Schaltfläche und ein Fenster namens Umgebungsvariablen öffnet sich. Im Systemvariablen Scrollen Sie in der unteren Hälfte des Fensters nach unten zu Path und doppelklicken Sie darauf. Dies öffnet ein Fenster namens Umgebungsvariablen bearbeiten. Ziehen Sie die Breite dieses Fensters weiter, damit Sie den vollständigen Pfad der Variablen sehen können:

Hier die wichtigen Einträge:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6\libnvvp
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\libnvvp
C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.29.30133\bin\Hostx64\x64
C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.42.34433\bin\Hostx64\x64
C:\Program Files\Git\cmd
C:\Program Files\CMake\bin
In den meisten Fällen sollten die richtigen Pfadvariablen bereits vorhanden sein.
Fügen Sie fehlende Pfade hinzu, indem Sie auf Neue auf der linken Seite des Umgebungsvariable bearbeiten Fenster und fügen Sie den richtigen Pfad ein:

Kopieren und fügen Sie die oben aufgeführten Pfade NICHT einfach ein. Prüfen Sie, ob die entsprechenden Pfade in Ihrer eigenen Windows-Installation vorhanden sind.
Wenn es geringfügige Pfadabweichungen gibt (insbesondere bei Visual Studio-Installationen), verwenden Sie die oben aufgeführten Pfade, um die richtigen Zielordner zu finden (d. h. x64 in Gastgeber64 in Ihrer eigenen Installation. Fügen Sie dann diejenigen Wege in die Umgebungsvariable bearbeiten Fenster.
Starten Sie anschließend den Computer neu.
Musubi installieren
PIP aktualisieren
Die Verwendung der neuesten Version des PIP-Installationsprogramms kann einige Installationsschritte vereinfachen. In einer Windows-Eingabeaufforderung mit Administratorrechten (siehe Elevation, unten), geben Sie Folgendes ein und drücken Sie die Eingabetaste:
pip install --upgrade pip
Elevation
Einige Befehle erfordern möglicherweise erhöhte Berechtigungen (d. h. sie müssen als Administrator ausgeführt werden). Wenn Sie in den folgenden Schritten Fehlermeldungen zu Berechtigungen erhalten, schließen Sie das Eingabeaufforderungsfenster und öffnen Sie es erneut im Administratormodus, indem Sie Folgendes eingeben: CMD in das Windows-Suchfeld, Rechtsklick auf Eingabeaufforderung und Auswählen Als Administrator ausführen:

Für die nächsten Schritte verwenden wir Windows Powershell anstelle der Windows-Eingabeaufforderung. Sie finden diese, indem Sie Folgendes eingeben: Powershell in das Windows-Suchfeld ein und klicken Sie (falls nötig) mit der rechten Maustaste darauf, um Als Administrator ausführen:

Torch installieren
Geben Sie in Powershell Folgendes ein:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Haben Sie Geduld, während die vielen Pakete installiert werden.
Wenn der Vorgang abgeschlossen ist, können Sie eine GPU-fähige PyTorch-Installation überprüfen, indem Sie Folgendes eintippen und eingeben:
python -c "import torch; print(torch.cuda.is_available())"
Dies sollte zu Folgendem führen:
C:\WINDOWS\system32>python -c "import torch;
print(torch.cuda.is_available())"
True
Installieren Sie Triton für Windows
Als nächstes erfolgt die Installation der Triton für Windows Komponente. Geben Sie in einer Powershell mit erhöhten Rechten (in einer einzigen Zeile) Folgendes ein:
pip install https://github.com/woct0rdho/triton-windows/releases/download/v3.1.0-windows.post8/triton-3.1.0-cp310-cp310-win_amd64.whl
(Das Installationsprogramm triton-3.1.0-cp310-cp310-win_amd64.whl funktioniert sowohl für Intel- als auch für AMD-CPUs, solange die Architektur 64-Bit ist und die Umgebung mit der Python-Version übereinstimmt)
Nach dem Ausführen sollte Folgendes resultieren:
Successfully installed triton-3.1.0
Wir können überprüfen, ob Triton funktioniert, indem wir es in Python importieren. Geben Sie diesen Befehl ein:
python -c "import triton; print('Triton is working')"
Dies sollte Folgendes ausgeben:
Triton is working
Um zu überprüfen, ob Triton GPU-fähig ist, geben Sie Folgendes ein:
python -c "import torch; print(torch.cuda.is_available())"
Dies sollte dazu führen, True:

Erstellen Sie die virtuelle Umgebung für Musubi
Ab sofort installieren wir jede weitere Software in einem Virtuelle Python-Umgebung (oder venv). Dies bedeutet, dass Sie zum Deinstallieren der folgenden Software nur den Installationsordner von venv in den Papierkorb ziehen müssen.
Lassen Sie uns diesen Installationsordner erstellen: Erstellen Sie einen Ordner namens Musubi auf Ihrem Desktop. Die folgenden Beispiele gehen davon aus, dass dieser Ordner existiert: C:\Users\[Your Profile Name]\Desktop\Musubi\.
Navigieren Sie in Powershell zu diesem Ordner, indem Sie Folgendes eingeben:
cd C:\Users\[Your Profile Name]\Desktop\Musubi
Wir möchten, dass die virtuelle Umgebung auf das zugreift, was wir bereits installiert haben (insbesondere Triton). Daher verwenden wir die --system-site-packages Flagge. Geben Sie Folgendes ein:
python -m venv --system-site-packages musubi
Warten Sie, bis die Umgebung erstellt wurde, und aktivieren Sie sie dann durch Eingabe von:
.\musubi\Scripts\activate
Dass Sie sich in der aktivierten virtuellen Umgebung befinden, erkennen Sie ab diesem Zeitpunkt daran, dass bei allen Eingabeaufforderungen am Anfang (musubi) steht.

Klonen Sie das Repository
Navigieren Sie zum neu erstellten musubi Ordner (der sich im Musubi Ordner auf Ihrem Desktop):
cd musubi
Nun sind wir am richtigen Ort und geben den folgenden Befehl ein:
git clone https://github.com/kohya-ss/musubi-tuner.git
Warten Sie, bis der Klonvorgang abgeschlossen ist (dies dauert nicht lange).

Installationsanforderungen
Navigieren Sie zum Installationsordner:
cd musubi-tuner
Geben Sie ein:
pip install -r requirements.txt
Warten Sie, bis die vielen Installationen abgeschlossen sind (dies dauert länger).

Automatisierter Zugriff auf das Hunyuan Video Venv
Um das neue Venv für zukünftige Sitzungen einfach zu aktivieren und darauf zuzugreifen, fügen Sie Folgendes in den Editor ein und speichern Sie es unter dem Namen aktivieren.bat, speichern mit Alle Dateien Option (siehe Abbildung unten).
@echo off
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate
cd C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner
cmd
(Ersetzen [Your Profile Name]durch den realen Namen Ihres Windows-Benutzerprofils)

Es spielt keine Rolle, an welchem Ort Sie diese Datei speichern.
Ab sofort können Sie doppelklicken aktivieren.bat und sofort mit der Arbeit beginnen.

Verwenden des Musubi-Tuners
Herunterladen der Modelle
Der Hunyuan Video LoRA-Trainingsprozess erfordert das Herunterladen von mindestens sieben Modellen, um alle möglichen Optimierungsoptionen für das Vorab-Caching und Training eines Hunyuan Video LoRA zu unterstützen. Zusammen wiegen diese Modelle mehr als 60 GB.
Aktuelle Anweisungen zum Download finden Sie unter https://github.com/kohya-ss/musubi-tuner?tab=readme-ov-file#model-download
Dies sind jedoch die Download-Anweisungen zum Zeitpunkt des Schreibens:
clip_l.safetensors
llava_llama3_fp16.safetensors
llava_llama3_fp8_scaled.safetensors
kann heruntergeladen werden unter:
https://huggingface.co/Comfy-Org/HunyuanVideo_repackaged/tree/main/split_files/text_encoders
mp_rank_00_model_states.pt
mp_rank_00_model_states_fp8.pt
mp_rank_00_model_states_fp8_map.pt
kann heruntergeladen werden unter:
https://huggingface.co/tencent/HunyuanVideo/tree/main/hunyuan-video-t2v-720p/transformers
pytorch_model.pt
kann heruntergeladen werden unter:
https://huggingface.co/tencent/HunyuanVideo/tree/main/hunyuan-video-t2v-720p/vae
Sie können diese zwar in jedem beliebigen Verzeichnis ablegen, aus Gründen der Konsistenz mit späteren Skripten legen wir sie jedoch hier ab:
C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\
Dies entspricht der Verzeichnisanordnung bis zu diesem Punkt. Alle nachfolgenden Befehle oder Anweisungen gehen davon aus, dass sich die Modelle hier befinden. Vergessen Sie nicht, [Ihr Profilname] durch den Namen Ihres tatsächlichen Windows-Profilordners zu ersetzen.
Datensatzvorbereitung
Wenn man die Kontroverse in der Community zu diesem Thema außer Acht lässt, kann man mit Fug und Recht sagen, dass Sie für einen Trainingsdatensatz für Ihr Hunyuan LoRA zwischen 10 und 100 Fotos benötigen. Selbst mit 15 Bildern lassen sich sehr gute Ergebnisse erzielen, solange die Bilder ausgewogen und von guter Qualität sind.
Ein Hunyuan LoRA kann sowohl anhand von Bildern als auch mit sehr kurzen und niedrig aufgelösten Videoclips oder sogar einer Mischung aus beidem trainiert werden – obwohl die Verwendung von Videoclips als Trainingsdaten selbst für eine 24-GB-Karte eine Herausforderung darstellt.
Allerdings sind Videoclips nur dann wirklich nützlich, wenn Ihr Charakter bewegt sich so ungewöhnlich, dass das Hunyuan Video Foundation-Modell möglicherweise nichts davon weiß, oder raten können.
Beispiele hierfür wären Roger Rabbit, ein Xenomorph, The Mask, Spider-Man oder andere Persönlichkeiten, die einzigartiges charakteristische Bewegung.
Da Hunyuan Video bereits weiß, wie sich normale Männer und Frauen bewegen, sind Videoclips nicht erforderlich, um einen überzeugenden menschlichen Charakter von Hunyuan Video LoRA zu erhalten. Daher verwenden wir statische Bilder.
Bildvorbereitung
The Bucket List
Die TLDR-Version:
Am besten verwenden Sie für Ihren Datensatz entweder Bilder, die alle die gleiche Größe haben, oder eine 50/50-Aufteilung zwischen zwei verschiedenen Größen, also 10 Bilder mit 512 x 768 Pixeln und 10 mit 768 x 512 Pixeln.
Auch wenn Sie dies nicht tun, kann das Training erfolgreich verlaufen – Hunyuan Video LoRAs können überraschend nachsichtig sein.
Die längere Version
Wie bei Kohya-ss LoRAs für statische generative Systeme wie Stable Diffusion, eimern wird verwendet, um die Arbeitslast auf Bilder unterschiedlicher Größe zu verteilen. Dadurch können größere Bilder verwendet werden, ohne dass während des Trainings Speicherfehler auftreten (d. h. durch Bucketing werden die Bilder in Blöcke „zerschnitten“, die der GPU verarbeiten kann, während die semantische Integrität des gesamten Bildes erhalten bleibt).
Für jede Bildgröße, die Sie in Ihren Trainingsdatensatz aufnehmen (z. B. 512 x 768 Pixel), wird ein Bucket oder eine „Unteraufgabe“ für diese Größe erstellt. Wenn Sie also die folgende Bildverteilung haben, wird die Bucket-Aufmerksamkeit unausgewogen und es besteht die Gefahr, dass einigen Fotos beim Training mehr Beachtung geschenkt wird als anderen:
2x 512x768px Bilder
7x 768x512px Bilder
1x 1000x600px Bild
3x 400x800px Bilder
Wir können sehen, dass die Aufmerksamkeit ungleichmäßig auf diese Bilder verteilt ist:

Bleiben Sie deshalb entweder bei einer Formatgröße oder versuchen Sie, die Verteilung der unterschiedlichen Größen relativ gleichmäßig zu halten.
Vermeiden Sie in jedem Fall sehr große Bilder, da dies das Training wahrscheinlich verlangsamt und der Nutzen kaum ins Gewicht fällt.
Der Einfachheit halber habe ich für alle Fotos in meinem Datensatz 512 x 768 Pixel verwendet.
Haftungsausschluss: Das im Datensatz verwendete Modell (die Person) erteilte mir die uneingeschränkte Erlaubnis, diese Bilder für diesen Zweck zu verwenden, und billigte alle KI-basierten Ausgaben, die ihr Abbild in diesem Artikel zeigen.

Mein Datensatz besteht aus 40 Bildern im PNG-Format (JPG ist aber auch in Ordnung). Meine Bilder wurden gespeichert bei C:\Users\Martin\Desktop\DATASETS_HUNYUAN\examplewoman
Sie sollten eine erstellen Cache-Speicher Ordner im Trainingsbildordner:

Lassen Sie uns nun eine spezielle Datei erstellen, die das Training konfiguriert.
TOML-Dateien
Die Trainings- und Pre-Caching-Prozesse von Hunyuan Video LoRAs beziehen die Dateipfade aus einer flachen Textdatei mit dem .toml Erweiterung.
Für meinen Test befindet sich das TOML unter C:\Users\Martin\Desktop\DATASETS_HUNYUAN\training.toml
Die Inhalte meines Trainings-TOML sehen folgendermaßen aus:
[general]
resolution = [512, 768]
caption_extension = ".txt"
batch_size = 1
enable_bucket = true
bucket_no_upscale = false
[[datasets]]
image_directory = "C:\\Users\\Martin\\Desktop\\DATASETS_HUNYUAN\\examplewoman"
cache_directory = "C:\\Users\\Martin\\Desktop\\DATASETS_HUNYUAN\\examplewoman\\cache"
num_repeats = 1
(Die doppelten Backslashes für Bild- und Cache-Verzeichnisse sind nicht immer notwendig, können aber helfen, Fehler zu vermeiden, wenn der Pfad ein Leerzeichen enthält. Ich habe Modelle mit .toml-Dateien trainiert, die einzelne Schrägstriche und einzelne Backslashes verwendeten.)
Wir sehen in der resolution Abschnitt, dass zwei Auflösungen berücksichtigt werden – 512px und 768px. Sie können dies auch bei 512 belassen und trotzdem gute Ergebnisse erzielen.
Simulatan die gesprochenen Worte mitlesen
Hunyuan Video ist ein Text+vision-Grundmodell, daher benötigen wir beschreibende Bildunterschriften für diese Bilder, die beim Training berücksichtigt werden. Der Trainingsprozess schlägt ohne Bildunterschriften fehl.
Es gibt eine Vielzahl von Open-Source-Untertitelungssystemen, die wir für diese Aufgabe verwenden könnten, aber lassen Sie es uns einfach halten und verwenden Sie die taggui System. Obwohl es auf GitHub gespeichert ist und beim ersten Ausführen einige sehr umfangreiche Deep-Learning-Modelle herunterlädt, wird es in Form einer einfachen ausführbaren Windows-Datei geliefert, die Python-Bibliotheken und eine unkomplizierte grafische Benutzeroberfläche lädt.
Nach dem Start von Taggui verwenden Sie Datei > Verzeichnis laden , um zu Ihrem Bilddatensatz zu navigieren, und geben Sie optional eine Token-ID ein (in diesem Fall Beispielfrau), das allen Untertiteln hinzugefügt wird:

(Schalten Sie unbedingt Laden in 4-Bit wenn Taggui zum ersten Mal geöffnet wird – es wird während der Untertitelung Fehler geben, wenn dies eingeschaltet bleibt)
Wählen Sie in der linken Vorschauspalte ein Bild aus und drücken Sie STRG+A, um alle Bilder auszuwählen. Klicken Sie dann rechts auf die Schaltfläche Automatische Untertitelung starten:

Sie sehen, dass Taggui in der kleinen CLI in der rechten Spalte Modelle herunterlädt, aber nur, wenn Sie den Untertiteler zum ersten Mal ausführen. Andernfalls sehen Sie eine Vorschau der Untertitel.

Jetzt verfügt jedes Foto über eine entsprechende TXT-Beschriftung mit einer Beschreibung des Bildinhalts:

Sie können klicken Erweiterte Optionen in Taggui, um Länge und Stil der Untertitel zu erhöhen, aber das geht über den Rahmen dieses Durchlaufs hinaus.
Beenden Sie Taggui und fahren wir fort mit …
Latentes Vorab-Caching
Um eine übermäßige GPU-Auslastung während des Trainings zu vermeiden, müssen zwei Arten von vorab zwischengespeicherten Dateien erstellt werden – eine zur Darstellung des aus den Bildern selbst abgeleiteten latenten Bildes und eine andere zur Auswertung einer Textkodierung in Bezug auf den Beschriftungsinhalt.
Um alle drei Prozesse (2x Cache + Training) zu vereinfachen, können Sie interaktive .BAT-Dateien verwenden, die Ihnen Fragen stellen und die Prozesse ausführen, wenn Sie die erforderlichen Informationen angegeben haben.
Für das latente Vorcaching kopieren Sie den folgenden Text in den Editor und speichern ihn als .BAT-Datei (benennen Sie ihn also etwa so: latent-precache.bat), und stellen Sie sicher, dass der Dateityp im Dropdown-Menü im Speichern unter Dialog ist Alle Dateien (siehe Bild unten):
@echo off
REM Activate the virtual environment
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate.bat
REM Get user input
set /p IMAGE_PATH=Enter the path to the image directory:
set /p CACHE_PATH=Enter the path to the cache directory:
set /p TOML_PATH=Enter the path to the TOML file:
echo You entered:
echo Image path: %IMAGE_PATH%
echo Cache path: %CACHE_PATH%
echo TOML file path: %TOML_PATH%
set /p CONFIRM=Do you want to proceed with latent pre-caching (y/n)?
if /i "%CONFIRM%"=="y" (
REM Run the latent pre-caching script
python C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\cache_latents.py --dataset_config %TOML_PATH% --vae C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\pytorch_model.pt --vae_chunk_size 32 --vae_tiling
) else (
echo Operation canceled.
)
REM Keep the window open
pause
(Stellen Sie sicher, dass Sie ersetzen [Ihr Profilname] durch den Namen Ihres echten Windows-Profilordners)

Jetzt können Sie die .BAT-Datei für das automatische latente Caching ausführen:

Wenn Sie durch die verschiedenen Fragen der BAT-Datei dazu aufgefordert werden, fügen Sie den Pfad zu Ihrem Datensatz, den Cache-Ordnern und der TOML-Datei ein oder geben Sie ihn ein.
Text-Vorab-Caching
Wir erstellen eine zweite BAT-Datei, diesmal für das Vorab-Caching des Textes.
@echo off
REM Activate the virtual environment
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate.bat
REM Get user input
set /p IMAGE_PATH=Enter the path to the image directory:
set /p CACHE_PATH=Enter the path to the cache directory:
set /p TOML_PATH=Enter the path to the TOML file:
echo You entered:
echo Image path: %IMAGE_PATH%
echo Cache path: %CACHE_PATH%
echo TOML file path: %TOML_PATH%
set /p CONFIRM=Do you want to proceed with text encoder output pre-caching (y/n)?
if /i "%CONFIRM%"=="y" (
REM Use the python executable from the virtual environment
python C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\cache_text_encoder_outputs.py --dataset_config %TOML_PATH% --text_encoder1 C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\llava_llama3_fp16.safetensors --text_encoder2 C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\clip_l.safetensors --batch_size 16
) else (
echo Operation canceled.
)
REM Keep the window open
pause
Ersetzen Sie Ihren Windows-Profilnamen und speichern Sie diesen als text-cache.bat (oder einen beliebigen anderen Namen), an einem beliebigen geeigneten Speicherort, gemäß dem Verfahren für die vorherige BAT-Datei.
Führen Sie diese neue BAT-Datei aus, folgen Sie den Anweisungen, und die erforderlichen textkodierten Dateien erscheinen im Cache-Speicher Ordner:

Training der Hunyuan Video Lora
Das Training des eigentlichen LoRA wird erheblich länger dauern als diese beiden Vorbereitungsprozesse.
Obwohl es auch mehrere Variablen gibt, die uns Sorgen bereiten könnten (wie etwa Batch-Größe, Wiederholungen, Epochen und ob vollständige oder quantisierte Modelle verwendet werden sollen, etc.), werden wir diese Überlegungen für einen anderen Tag aufheben und uns die Feinheiten der LoRA-Erstellung genauer ansehen.
Lassen Sie uns vorerst die Auswahl etwas minimieren und einen LoRA mit „mittleren“ Einstellungen trainieren.
Wir erstellen eine dritte BAT-Datei, diesmal um das Training zu starten. Fügen Sie diese in den Editor ein und speichern Sie sie wie zuvor als BAT-Datei. training.bat (oder ein beliebiger Name):
@echo off
REM Activate the virtual environment
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate.bat
REM Get user input
set /p DATASET_CONFIG=Enter the path to the dataset configuration file:
set /p EPOCHS=Enter the number of epochs to train:
set /p OUTPUT_NAME=Enter the output model name (e.g., example0001):
set /p LEARNING_RATE=Choose learning rate (1 for 1e-3, 2 for 5e-3, default 1e-3):
if "%LEARNING_RATE%"=="1" set LR=1e-3
if "%LEARNING_RATE%"=="2" set LR=5e-3
if "%LEARNING_RATE%"=="" set LR=1e-3
set /p SAVE_STEPS=How often (in steps) to save preview images:
set /p SAMPLE_PROMPTS=What is the location of the text-prompt file for training previews?
echo You entered:
echo Dataset configuration file: %DATASET_CONFIG%
echo Number of epochs: %EPOCHS%
echo Output name: %OUTPUT_NAME%
echo Learning rate: %LR%
echo Save preview images every %SAVE_STEPS% steps.
echo Text-prompt file: %SAMPLE_PROMPTS%
REM Prepare the command
set CMD=accelerate launch --num_cpu_threads_per_process 1 --mixed_precision bf16 ^
C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\hv_train_network.py ^
--dit C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\models\mp_rank_00_model_states.pt ^
--dataset_config %DATASET_CONFIG% ^
--sdpa ^
--mixed_precision bf16 ^
--fp8_base ^
--optimizer_type adamw8bit ^
--learning_rate %LR% ^
--gradient_checkpointing ^
--max_data_loader_n_workers 2 ^
--persistent_data_loader_workers ^
--network_module=networks.lora ^
--network_dim=32 ^
--timestep_sampling sigmoid ^
--discrete_flow_shift 1.0 ^
--max_train_epochs %EPOCHS% ^
--save_every_n_epochs=1 ^
--seed 42 ^
--output_dir "C:\Users\[Your Profile Name]\Desktop\Musubi\Output Models" ^
--output_name %OUTPUT_NAME% ^
--vae C:/Users/[Your Profile Name]/Desktop/Musubi/musubi/musubi-tuner/models/pytorch_model.pt ^
--vae_chunk_size 32 ^
--vae_spatial_tile_sample_min_size 128 ^
--text_encoder1 C:/Users/[Your Profile Name]/Desktop/Musubi/musubi/musubi-tuner/models/llava_llama3_fp16.safetensors ^
--text_encoder2 C:/Users/[Your Profile Name]/Desktop/Musubi/musubi/musubi-tuner/models/clip_l.safetensors ^
--sample_prompts %SAMPLE_PROMPTS% ^
--sample_every_n_steps %SAVE_STEPS% ^
--sample_at_first
echo The following command will be executed:
echo %CMD%
set /p CONFIRM=Do you want to proceed with training (y/n)?
if /i "%CONFIRM%"=="y" (
%CMD%
) else (
echo Operation canceled.
)
REM Keep the window open
cmd /k
Wie immer sollten Sie alle Instanzen ersetzen.f [Ihr Profilname] durch Ihren korrekten Windows-Profilnamen.
Stellen Sie sicher, dass das Verzeichnis C:\Users\[Your Profile Name]\Desktop\Musubi\Output Models\ existiert, und erstellen Sie es andernfalls an dieser Stelle.
Trainingsvorschau
Für den Musubi-Trainer wurde kürzlich eine sehr einfache Trainingsvorschaufunktion aktiviert, mit der Sie das Trainingsmodell zum Anhalten zwingen und Bilder basierend auf von Ihnen gespeicherten Eingabeaufforderungen generieren können. Diese werden in einem automatisch erstellten Ordner namens Musteranfrage, im selben Verzeichnis, in dem die trainierten Modelle gespeichert sind.

Um dies zu ermöglichen, müssen Sie mindestens eine Eingabeaufforderung in einer Textdatei speichern. Der von uns erstellte Trainings-BAT fordert Sie auf, den Speicherort dieser Datei einzugeben. Sie können der Eingabeaufforderungsdatei daher einen beliebigen Namen geben und sie an einem beliebigen Ort speichern.
Hier sind einige Beispiele für Eingabeaufforderungen für eine Datei, die auf Anforderung der Trainingsroutine drei verschiedene Bilder ausgibt:

Wie Sie im obigen Beispiel sehen können, können Sie am Ende der Eingabeaufforderung Flags einfügen, die sich auf die Bilder auswirken:
–w ist Breite (der Standardwert ist 256px, wenn nicht festgelegt, gemäß die docs)
-sein Höhe (der Standardwert ist 256 Pixel, wenn nicht festgelegt)
–f ist die Anzahl der Frames. Wenn der Wert auf 1 gesetzt ist, wird ein Bild erzeugt, bei mehr als einem ein Video.
–d ist der Seed. Wenn nicht festgelegt, ist es zufällig; Sie sollten es jedoch festlegen, um die Entwicklung einer Eingabeaufforderung zu sehen.
–s ist die Anzahl der Schritte bei der Generierung, der Standardwert ist 20.
Weitere Informationen finden Sie auch in den die offizielle Dokumentation für zusätzliche Flaggen.
Obwohl in der Trainingsvorschau schnell einige Probleme aufgedeckt werden können, die dazu führen könnten, dass Sie das Training abbrechen und die Daten oder die Einrichtung überdenken und so Zeit sparen, denken Sie daran, dass jede zusätzliche Eingabeaufforderung das Training ein wenig weiter verlangsamt.
Zudem verlangsamt sich das Training umso mehr, je größer die Breite und Höhe des Trainingsvorschaubilds ist (wie in den oben aufgeführten Flags festgelegt).
Starten Sie Ihre Trainings-BAT-Datei.
Frage #1 lautet: „Geben Sie den Pfad zur Datensatzkonfiguration ein. Fügen Sie den richtigen Pfad zu Ihrer TOML-Datei ein oder geben Sie ihn ein.“
Frage #2 lautet „Geben Sie die Anzahl der zu trainierenden Epochen ein“. Dies ist eine Variable, die durch Versuch und Irrtum bestimmt wird, da sie von der Menge und Qualität der Bilder sowie den Bildunterschriften und anderen Faktoren beeinflusst wird. Im Allgemeinen ist es besser, den Wert zu hoch als zu niedrig einzustellen, da Sie das Training jederzeit mit Strg+C im Trainingsfenster beenden können, wenn Sie der Meinung sind, dass das Modell weit genug fortgeschritten ist. Stellen Sie den Wert zunächst auf 100 ein und sehen Sie, wie es läuft.
Frage #3 lautet „Geben Sie den Namen des Ausgabemodells ein“. Geben Sie Ihrem Modell einen Namen! Am besten halten Sie den Namen möglichst kurz und einfach.
Frage #4 ist „Lernrate wählen“, die standardmäßig auf 1e-3 (Option 1) eingestellt ist. Dies ist ein guter Ausgangspunkt, bis weitere Erfahrungen vorliegen.
Frage #5 ist „Wie oft (in Schritten) Vorschaubilder gespeichert werden sollen. Wenn Sie diesen Wert zu niedrig einstellen, werden Sie zwischen den Speicherungen der Vorschaubilder nur geringe Fortschritte sehen und das Training wird dadurch verlangsamt.“
Frage #6 lautet: „Wo befindet sich die Texteingabeaufforderungsdatei für Trainingsvorschauen?“. Fügen Sie den Pfad zu Ihrer Eingabeaufforderungstextdatei ein oder geben Sie ihn ein.
Das BAT zeigt Ihnen dann den Befehl, den es an das Hunyuan-Modell senden wird, und fragt Sie, ob Sie fortfahren möchten, j/n.
Legen Sie gleich los und beginnen Sie mit dem Training:
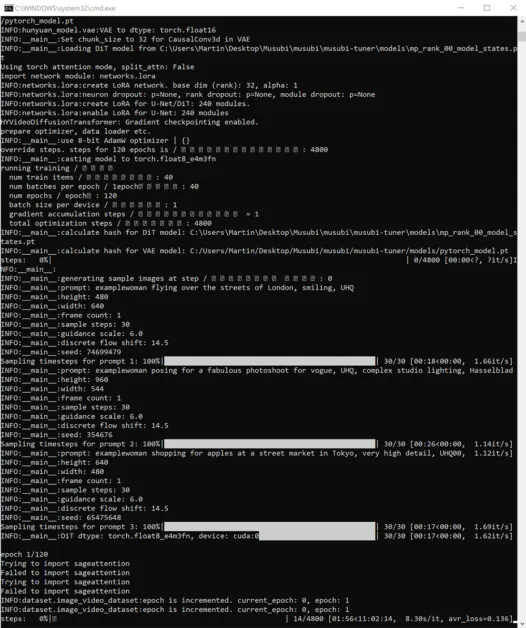
Wenn Sie während dieser Zeit den Abschnitt „GPU“ auf der Registerkarte „Leistung“ des Windows-Task-Managers überprüfen, sehen Sie, dass der Prozess etwa 16 GB VRAM beansprucht.

Dabei handelt es sich möglicherweise nicht um eine willkürliche Zahl, denn dies ist die Menge an VRAM, die auf ziemlich vielen NVIDIA-Grafikkarten verfügbar ist. Außerdem könnte der Upstream-Code optimiert worden sein, um die Aufgaben zum Vorteil der Besitzer solcher Karten auf 16 GB unterzubringen.
Allerdings ist es sehr einfach, diese Nutzung zu steigern, indem man dem Trainingskommando exorbitantere Flaggen sendet.
Während des Trainings wird unten rechts im CMD-Fenster eine Zahl angezeigt, die angibt, wie viel Zeit seit Trainingsbeginn vergangen ist, sowie eine Schätzung der gesamten Trainingszeit (die stark variiert und von den gesetzten Flags, der Anzahl der Trainingsbilder, der Anzahl der Trainingsvorschaubilder und verschiedenen anderen Faktoren abhängt).

Eine typische Trainingszeit beträgt bei mittleren Einstellungen etwa 3–4 Stunden, abhängig von der verfügbaren Hardware, der Anzahl der Bilder, den Flag-Einstellungen und anderen Faktoren.
Verwenden Ihrer trainierten LoRA-Modelle im Hunyuan-Video
Auswählen von Prüfpunkten
Wenn das Training abgeschlossen ist, verfügen Sie über einen Modellprüfpunkt für jede Trainingsepoche.

Diese Speicherhäufigkeit kann vom Benutzer geändert werden, um je nach Wunsch mehr oder weniger häufig zu speichern, indem er die --save_every_n_epochs [N] Nummer in der BAT-Trainingsdatei. Wenn Sie beim Einrichten des Trainings mit der BAT eine niedrige Zahl für die Speicherungen pro Schritt hinzugefügt haben, wird eine hohe Anzahl gespeicherter Checkpoint-Dateien vorhanden sein.
Welchen Kontrollpunkt soll ich wählen?
Wie bereits erwähnt, sind die am frühesten trainierten Modelle am flexibelsten, während die späteren Checkpoints möglicherweise die meisten Details bieten. Die einzige Möglichkeit, diese Faktoren zu testen, besteht darin, einige der LoRAs auszuführen und einige Videos zu erstellen. Auf diese Weise können Sie herausfinden, welche Checkpoints am produktivsten sind und das beste Gleichgewicht zwischen Flexibilität und Genauigkeit darstellen.
ComfyUI
Die beliebteste (wenn auch nicht die einzige) Umgebung für die Verwendung von Hunyuan Video LoRAs ist derzeit ComfyUI, ein knotenbasierter Editor mit einer ausgefeilten Gradio-Schnittstelle, die in Ihrem Webbrowser ausgeführt wird.

Quelle: https://github.com/comfyanonymous/ComfyUI
Die Installationsanweisungen sind unkompliziert und verfügbar im offiziellen GitHub-Repository (zusätzliche Modelle müssen heruntergeladen werden).
Konvertieren von Modellen für ComfyUI
Ihre trainierten Modelle werden in einem (Diffusor-)Format gespeichert, das mit den meisten Implementierungen von ComfyUI nicht kompatibel ist. Musubi kann ein Modell in ein ComfyUI-kompatibles Format konvertieren. Lassen Sie uns eine BAT-Datei einrichten, um dies zu implementieren.
Erstellen Sie vor dem Ausführen dieser BAT die C:\Users\[Your Profile Name]\Desktop\Musubi\CONVERTED\ Ordner, den das Skript erwartet.
@echo off
REM Activate the virtual environment
call C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\Scripts\activate.bat
:START
REM Get user input
set /p INPUT_PATH=Enter the path to the input Musubi safetensors file (or type "exit" to quit):
REM Exit if the user types "exit"
if /i "%INPUT_PATH%"=="exit" goto END
REM Extract the file name from the input path and append 'converted' to it
for %%F in ("%INPUT_PATH%") do set FILENAME=%%~nF
set OUTPUT_PATH=C:\Users\[Your Profile Name]\Desktop\Musubi\Output Models\CONVERTED\%FILENAME%_converted.safetensors
set TARGET=other
echo You entered:
echo Input file: %INPUT_PATH%
echo Output file: %OUTPUT_PATH%
echo Target format: %TARGET%
set /p CONFIRM=Do you want to proceed with the conversion (y/n)?
if /i "%CONFIRM%"=="y" (
REM Run the conversion script with correctly quoted paths
python C:\Users\[Your Profile Name]\Desktop\Musubi\musubi\musubi-tuner\convert_lora.py --input "%INPUT_PATH%" --output "%OUTPUT_PATH%" --target %TARGET%
echo Conversion complete.
) else (
echo Operation canceled.
)
REM Return to start for another file
goto START
:END
REM Keep the window open
echo Exiting the script.
pause
Wie bei den vorherigen BAT-Dateien speichern Sie das Skript im Editor unter dem Namen „Alle Dateien“ und benennen es konvertieren.bat (oder was auch immer Sie möchten).
Doppelklicken Sie nach dem Speichern auf die neue BAT-Datei. Sie werden aufgefordert, den Speicherort der zu konvertierenden Datei anzugeben.

Fügen Sie den Pfad zur trainierten Datei ein, die Sie konvertieren möchten, oder geben Sie ihn ein. Klicken Sie auf y, und drücken Sie die Eingabetaste.
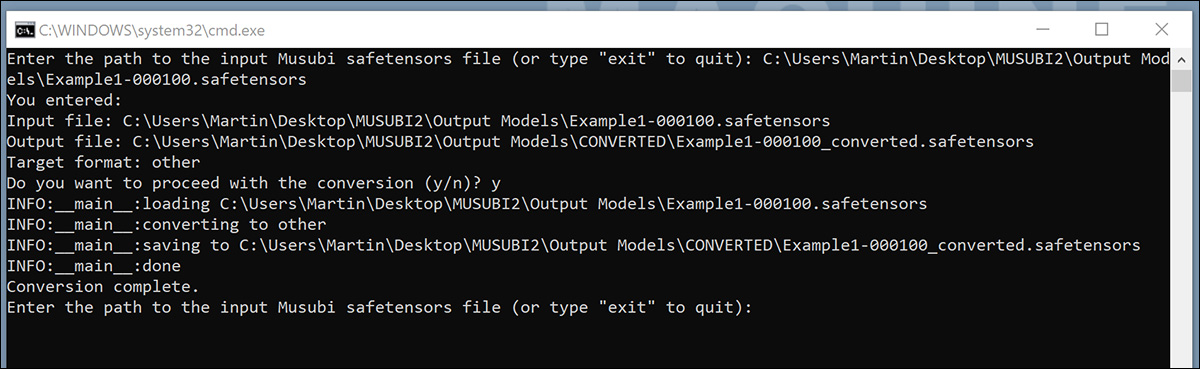
Nach dem Speichern der konvertierten LoRA im KONVERTIERT Ordner, das Skript fragt, ob Sie eine weitere Datei konvertieren möchten. Wenn Sie mehrere Checkpoints in ComfyUI testen möchten, konvertieren Sie eine Auswahl der Modelle.
Wenn Sie genügend Prüfpunkte konvertiert haben, schließen Sie das BAT-Befehlsfenster.
Sie können Ihre konvertierten Modelle jetzt in den Ordner models\loras in Ihrer ComfyUI-Installation kopieren.
Normalerweise sieht der richtige Speicherort etwa so aus:
C:\Users\[Your Profile Name]\Desktop\ComfyUI\models\loras\
Erstellen von Hunyuan Video LoRAs in ComfyUI
Obwohl die knotenbasierten Workflows von ComfyUI zunächst komplex erscheinen, können die Einstellungen anderer erfahrenerer Benutzer geladen werden, indem ein Bild (das mit dem ComfyUI des anderen Benutzers erstellt wurde) direkt in das ComfyUI-Fenster gezogen wird. Workflows können auch als JSON-Dateien exportiert werden, die manuell importiert oder in ein ComfyUI-Fenster gezogen werden können.
Einige importierte Workflows haben Abhängigkeiten, die in Ihrer Installation möglicherweise nicht vorhanden sind. Installieren Sie daher ComfyUI-Manager, das fehlende Module automatisch abrufen kann.

Quelle: https://github.com/ltdrdata/ComfyUI-Manager
Um einen der Workflows zum Generieren von Videos aus den Modellen in diesem Tutorial zu laden, laden Sie diese JSON-Datei und ziehen Sie es in Ihr ComfyUI-Fenster (es gibt allerdings weitaus bessere Workflow-Beispiele in den verschiedenen Reddit- und Discord-Communitys, die Hunyuan Video übernommen haben, und mein eigenes ist von einer dieser Communities adaptiert).
Dies ist nicht der richtige Ort für ein ausführliches Tutorial zur Verwendung von ComfyUI, aber es lohnt sich, einige der entscheidenden Parameter zu erwähnen, die sich auf Ihre Ausgabe auswirken, wenn Sie das oben verlinkte JSON-Layout herunterladen und verwenden.

1) Breite und Höhe
Je größer Ihr Image ist, desto länger dauert die Generierung und desto höher ist das Risiko eines Out-of-Memory-Fehlers (OOM).
2) Länge
Dies ist der numerische Wert für die Anzahl der Frames. Wie viele Sekunden es insgesamt sind, hängt von der Framerate ab (in diesem Layout auf 30 fps eingestellt). Sie können Sekunden in Frames basierend auf fps umwandeln. bei Omnicalculator.
3) Chargengröße
Je höher Sie die Batchgröße einstellen, desto schneller kann das Ergebnis vorliegen, aber desto größer ist auch die Belastung des VRAM. Wenn Sie den Wert zu hoch einstellen, kann es zu einem OOM kommen.
4) Kontrolle nach der Generierung
Dies steuert den Zufallsstartwert. Die Optionen für diesen Unterknoten sind fixiert, Zuwachs, Dekrement und randomisierenWenn Sie es bei fixiert und ändern Sie die Texteingabeaufforderung nicht, erhalten Sie jedes Mal dasselbe Bild. Wenn Sie die Texteingabeaufforderung ändern, ändert sich das Bild in begrenztem Umfang. Die Zuwachs und Dekrement Einstellungen ermöglichen es Ihnen, nahegelegene Seed-Werte zu erkunden, während randomisieren gibt Ihnen eine völlig neue Interpretation der Eingabeaufforderung.
5) Name Lora
Sie müssen hier Ihr eigenes installiertes Modell auswählen, bevor Sie mit der Generierung beginnen.
6) Zeichen
Wenn Sie Ihr Modell darauf trainiert haben, das Konzept mit einem Token auszulösen (z. B. 'Beispielperson'), fügen Sie dieses Auslösewort in Ihre Eingabeaufforderung ein.
7) Schritte
Dies gibt an, wie viele Schritte das System auf den Diffusionsprozess anwendet. Höhere Schritte können zu besseren Details führen, aber die Effektivität dieses Ansatzes ist begrenzt und dieser Schwellenwert kann schwer zu finden sein. Der übliche Schrittbereich liegt bei etwa 20-30.
8) Kachelgröße
Dies definiert, wie viele Informationen bei der Generierung gleichzeitig verarbeitet werden. Der Standardwert ist 256. Eine Erhöhung des Werts kann die Generierung beschleunigen, eine zu hohe Einstellung kann jedoch zu einer besonders frustrierenden OOM-Erfahrung führen, da dies ganz am Ende eines langen Prozesses erfolgt.
9) Zeitliche Überlappung
Die Hunyuan-Videogenerierung von Personen kann zu „Geisterbildern“ oder unglaubwürdigen Bewegungen führen, wenn dieser Wert zu niedrig eingestellt ist. Im Allgemeinen ist man der Meinung, dass dieser Wert höher als die Anzahl der Frames eingestellt werden sollte, um bessere Bewegungen zu erzeugen.
Schlussfolgerung
Obwohl eine weitere Erforschung der ComfyUI-Nutzung über den Rahmen dieses Artikels hinausgeht, kann die Community-Erfahrung bei Reddit und Discords die Lernkurve erleichtern, und es gibt mehrere Online-Anleitungen die in die Grundlagen einführen.
Erstveröffentlichung Donnerstag, 23. Januar 2025












