
Künstliche Intelligenz
GPT-4o von OpenAI: Das multimodale KI-Modell, das die Mensch-Maschine-Interaktion verändert

OpenAI hat sein neuestes und fortschrittlichstes Sprachmodell veröffentlicht – GPT-4o, auch bekannt als „Omni" Modell. Dieses revolutionäre KI-System stellt einen riesigen Fortschritt dar und verfügt über Fähigkeiten, die die Grenze zwischen menschlicher und künstlicher Intelligenz verwischen.
Das Herzstück von GPT-4o ist seine native multimodale Natur, die es ihm ermöglicht, Inhalte aus Text, Audio, Bildern und Video nahtlos zu verarbeiten und zu generieren. Diese Integration mehrerer Modalitäten in ein einziges Modell ist einzigartig und verspricht, die Art und Weise, wie wir mit KI-Assistenten interagieren, neu zu gestalten.
Aber GPT-4o ist viel mehr als nur ein multimodales System. Es verfügt über eine erstaunliche Leistungssteigerung gegenüber seinem Vorgänger GPT-4 und lässt Konkurrenzmodelle wie Gemini 1.5 Pro, Claude 3 und Llama 3-70B in den Schatten stellen. Lassen Sie uns genauer untersuchen, was dieses KI-Modell wirklich bahnbrechend macht.
Beispiellose Leistung und Effizienz
Einer der beeindruckendsten Aspekte von GPT-4o ist seine beispiellose Leistungsfähigkeit. Den Auswertungen von OpenAI zufolge weist das Modell einen beachtlichen Vorsprung von 60 Elo-Punkten gegenüber dem bisherigen Top-Performer GPT-4 Turbo auf. Mit diesem bedeutenden Vorteil spielt GPT-4o in einer eigenen Liga und übertrifft selbst die fortschrittlichsten derzeit verfügbaren KI-Modelle.
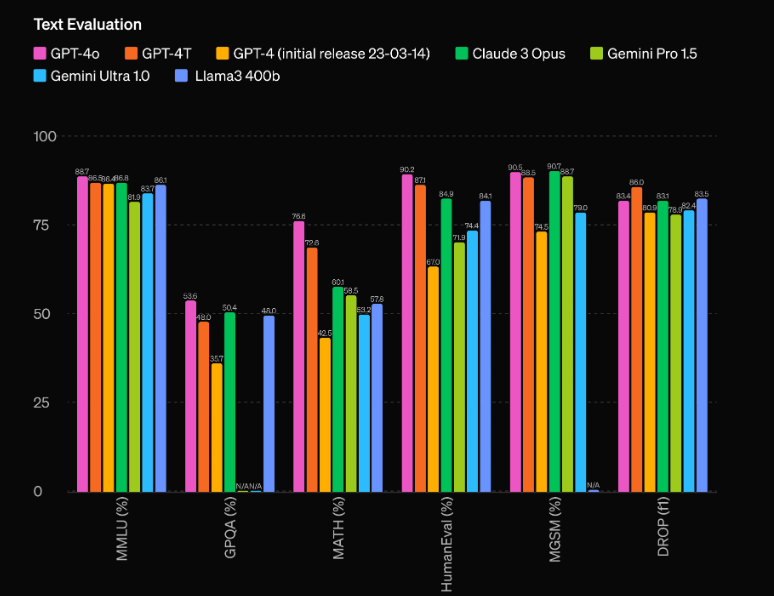
Aber die reine Leistung ist nicht der einzige Bereich, in dem GPT-4o glänzt. Das Modell zeichnet sich außerdem durch eine beeindruckende Effizienz aus: Es arbeitet mit der doppelten Geschwindigkeit des GPT-4 Turbo und kostet im Betrieb nur die Hälfte. Diese Kombination aus überlegener Leistung und Kosteneffizienz macht GPT-4o zu einem äußerst attraktiven Angebot für Entwickler und Unternehmen, die modernste KI-Funktionen in ihre Anwendungen integrieren möchten.
Multimodale Fähigkeiten: Kombination von Text, Audio und Bild
Der vielleicht bahnbrechendste Aspekt von GPT-4o ist seine native multimodale Natur, die es ihm ermöglicht, Inhalte über mehrere Modalitäten hinweg, einschließlich Text, Audio und Bild, nahtlos zu verarbeiten und zu generieren. Diese Integration mehrerer Modalitäten in ein einziges Modell ist einzigartig und verspricht, die Art und Weise, wie wir mit KI-Assistenten interagieren, zu revolutionieren.
Mit GPT-4o können Benutzer mithilfe von Sprache natürliche Gespräche in Echtzeit führen, wobei das Modell Audioeingaben sofort erkennt und darauf reagiert. Aber damit sind die Fähigkeiten noch nicht getan – GPT-4o kann auch visuelle Inhalte interpretieren und generieren und eröffnet so eine Welt voller Möglichkeiten für Anwendungen, die von der Bildanalyse und -generierung bis hin zum Verstehen und Erstellen von Videos reichen.
Eine der beeindruckendsten Demonstrationen der multimodalen Fähigkeiten von GPT-4o ist seine Fähigkeit, eine Szene oder ein Bild in Echtzeit zu analysieren und die wahrgenommenen visuellen Elemente genau zu beschreiben und zu interpretieren. Diese Funktion hat tiefgreifende Auswirkungen auf Anwendungen wie unterstützende Technologien für Sehbehinderte sowie auf Bereiche wie Sicherheit, Überwachung und Automatisierung.
Die multimodalen Fähigkeiten von GPT-4o gehen jedoch über das bloße Verstehen und Generieren von Inhalten über verschiedene Modalitäten hinaus hinaus. Das Modell kann diese Modalitäten auch nahtlos kombinieren und so wirklich immersive und fesselnde Erlebnisse schaffen. Während der Live-Demo von OpenAI war GPT-4o beispielsweise in der Lage, einen Song basierend auf Eingabebedingungen zu generieren und dabei sein Verständnis von Sprache, Musiktheorie und Audioerzeugung zu einem zusammenhängenden und beeindruckenden Ergebnis zu vereinen.
Verwendung von GPT0 mit Python
import openai
# Replace with your actual API key
OPENAI_API_KEY = "your_openai_api_key_here"
# Function to extract the response content
def get_response_content(response_dict, exclude_tokens=None):
if exclude_tokens is None:
exclude_tokens = []
if response_dict and response_dict.get("choices") and len(response_dict["choices"]) > 0:
content = response_dict["choices"][0]["message"]["content"].strip()
if content:
for token in exclude_tokens:
content = content.replace(token, '')
return content
raise ValueError(f"Unable to resolve response: {response_dict}")
# Asynchronous function to send a request to the OpenAI chat API
async def send_openai_chat_request(prompt, model_name, temperature=0.0):
openai.api_key = OPENAI_API_KEY
message = {"role": "user", "content": prompt}
response = await openai.ChatCompletion.acreate(
model=model_name,
messages=[message],
temperature=temperature,
)
return get_response_content(response)
# Example usage
async def main():
prompt = "Hello!"
model_name = "gpt-4o-2024-05-13"
response = await send_openai_chat_request(prompt, model_name)
print(response)
if __name__ == "__main__":
import asyncio
asyncio.run(main())
Ich habe:
- Das OpenAI-Modul wurde direkt importiert, anstatt eine benutzerdefinierte Klasse zu verwenden.
- Die Funktion openai_chat_resolve wurde in get_response_content umbenannt und einige kleinere Änderungen an ihrer Implementierung vorgenommen.
- Die AsyncOpenAI-Klasse wurde durch die Funktion openai.ChatCompletion.acreate ersetzt, die offizielle asynchrone Methode, die von der OpenAI-Python-Bibliothek bereitgestellt wird.
- Es wurde eine Beispielhauptfunktion hinzugefügt, die zeigt, wie die Funktion send_openai_chat_request verwendet wird.
Bitte beachten Sie, dass Sie „your_openai_api_key_here“ durch Ihren tatsächlichen OpenAI-API-Schlüssel ersetzen müssen, damit der Code ordnungsgemäß funktioniert.


















