Evnen til at generere 3D digitale aktiver fra tekstprompter repræsenterer en af de mest spændende nyere udviklinger inden for AI og computergrafik. Da markedet for digitale 3D-aktiver forventes at vokse fra $ 28.3 milliarder i 2024 til $ 51.8 milliarder i 2029, tekst-til-3D AI-modeller er klar til at spille en stor rolle i at revolutionere indholdsskabelse på tværs af industrier som spil, film, e-handel og meget mere. Men hvordan fungerer disse AI-systemer præcist? I denne artikel tager vi et dybt dyk ned i de tekniske detaljer bag tekst-til-3D-generering.
Udfordringen ved 3D-generering
Generering af 3D-aktiver ud fra tekst er en væsentlig mere kompleks opgave end generering af 2D-billeder. Mens 2D-billeder i det væsentlige er gitter af pixels, kræver 3D-aktiver at repræsentere geometri, teksturer, materialer og ofte animationer i tredimensionelt rum. Denne ekstra dimensionalitet og kompleksitet gør generationsopgaven meget mere udfordrende.
Nogle nøgleudfordringer i tekst-til-3D-generering inkluderer:
Repræsenterer 3D geometri og struktur
Generering af ensartede teksturer og materialer på tværs af 3D-overfladen
Sikring af fysisk plausibilitet og sammenhæng fra flere synsvinkler
Fang fine detaljer og global struktur på samme tid
Generering af aktiver, der nemt kan gengives eller 3D-printes
For at tackle disse udfordringer udnytter tekst-til-3D-modeller flere nøgleteknologier og -teknikker.
Nøglekomponenter i tekst-til-3D-systemer
De fleste avancerede tekst-til-3D-genereringssystemer deler nogle få kernekomponenter:
Tekstkodning: Konvertering af inputtekstprompten til en numerisk repræsentation
3D-repræsentation: En metode til at repræsentere 3D-geometri og udseende
Generativ model: Kerne-AI-modellen til generering af 3D-aktivet
rendering: Konvertering af 3D-repræsentationen til 2D-billeder til visualisering
Lad os udforske hver af disse mere detaljeret.
Tekstkodning
Det første trin er at konvertere inputtekstprompten til en numerisk repræsentation, som AI-modellen kan arbejde med. Dette gøres typisk ved hjælp af store sprogmodeller som f.eks BERT eller GPT.
3D-repræsentation
Der er flere almindelige måder at repræsentere 3D-geometri på i AI-modeller:
Voxel gitter: 3D-arrays af værdier, der repræsenterer belægning eller funktioner
Punkt skyer: Sæt med 3D-punkter
Masker: Hjørner og flader, der definerer en overflade
Implicitte funktioner: Kontinuerlige funktioner, der definerer en overflade (f.eks. fortegnsafstandsfunktioner)
Hver har kompromiser med hensyn til opløsning, hukommelsesbrug og nem generering. Mange nyere modeller bruger implicitte funktioner eller NeRF'er, da de giver mulighed for resultater af høj kvalitet med rimelige beregningskrav.
For eksempel kan vi repræsentere en simpel kugle som en fortegnsafstandsfunktion:
import numpy as np
def sphere_sdf(x, y, z, radius=1.0):
return np.sqrt(x**2 + y**2 + z**2) - radius
# Evaluate SDF at a 3D point
point = [0.5, 0.5, 0.5]
distance = sphere_sdf(*point)
print(f"Distance to sphere surface: {distance}")
Generativ model
Kernen i et tekst-til-3D-system er den generative model, der producerer 3D-repræsentationen fra indlejring af tekst. De fleste avancerede modeller bruger en eller anden variation af en diffusionsmodel, svarende til dem, der bruges i 2D-billedgenerering.
Diffusionsmodeller fungerer ved gradvist at tilføje støj til data og derefter lære at vende denne proces. For 3D-generering sker denne proces i rummet af den valgte 3D-repræsentation.
En forenklet pseudokode til et træningstrin i en diffusionsmodel kan se sådan ud:
def diffusion_training_step(model, x_0, text_embedding):
# Sample a random timestep
t = torch.randint(0, num_timesteps, (1,))
# Add noise to the input
noise = torch.randn_like(x_0)
x_t = add_noise(x_0, noise, t)
# Predict the noise
predicted_noise = model(x_t, t, text_embedding)
# Compute loss
loss = F.mse_loss(noise, predicted_noise)
return loss
# Training loop
for batch in dataloader:
x_0, text = batch
text_embedding = encode_text(text)
loss = diffusion_training_step(model, x_0, text_embedding)
loss.backward()
optimizer.step()
Under genereringen tager vi udgangspunkt i ren støj og iterativt denoise, betinget af tekstindlejringen.
rendering
For at visualisere resultater og beregne tab under træning, skal vi gengive vores 3D-repræsentation til 2D-billeder. Dette gøres typisk ved hjælp af differentierbare gengivelsesteknikker, der tillader gradienter at flyde tilbage gennem gengivelsesprocessen.
Til mesh-baserede repræsentationer kan vi bruge en rasteriseringsbaseret renderer:
import torch
import torch.nn.functional as F
import pytorch3d.renderer as pr
def render_mesh(vertices, faces, image_size=256):
# Create a renderer
renderer = pr.MeshRenderer(
rasterizer=pr.MeshRasterizer(),
shader=pr.SoftPhongShader()
)
# Set up camera
cameras = pr.FoVPerspectiveCameras()
# Render
images = renderer(vertices, faces, cameras=cameras)
return images
# Example usage
vertices = torch.rand(1, 100, 3) # Random vertices
faces = torch.randint(0, 100, (1, 200, 3)) # Random faces
rendered_images = render_mesh(vertices, faces)
Til implicitte repræsentationer som NeRF'er bruger vi typisk strålemarchteknikker til at gengive visninger.
At sætte det hele sammen: Tekst-til-3D-pipeline
Nu hvor vi har dækket nøglekomponenterne, lad os gennemgå, hvordan de kommer sammen i en typisk tekst-til-3D-genereringspipeline:
Tekstkodning: Input-prompten er kodet til en tæt vektorrepræsentation ved hjælp af en sprogmodel.
Indledende generation: En diffusionsmodel, betinget af tekstindlejringen, genererer en indledende 3D-repræsentation (f.eks. en NeRF eller implicit funktion).
Konsistens i flere visninger: Modellen gengiver flere visninger af det genererede 3D-aktiv og sikrer konsistens på tværs af synspunkter.
Refinement: Yderligere netværk kan forfine geometri, tilføje teksturer eller forbedre detaljer.
Endeligt output: 3D-repræsentationen konverteres til et ønsket format (f.eks. tekstureret mesh) til brug i downstream-applikationer.
Her er et forenklet eksempel på, hvordan dette kan se ud i kode:
class TextTo3D(nn.Module):
def __init__(self):
super().__init__()
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.diffusion_model = DiffusionModel()
self.refiner = RefinerNetwork()
self.renderer = DifferentiableRenderer()
def forward(self, text_prompt):
# Encode text
text_embedding = self.text_encoder(text_prompt).last_hidden_state.mean(dim=1)
# Generate initial 3D representation
initial_3d = self.diffusion_model(text_embedding)
# Render multiple views
views = self.renderer(initial_3d, num_views=4)
# Refine based on multi-view consistency
refined_3d = self.refiner(initial_3d, views)
return refined_3d
# Usage
model = TextTo3D()
text_prompt = "A red sports car"
generated_3d = model(text_prompt)
Toptekst til 3d-aktivmodeller tilgængelige
3DGen – Meta
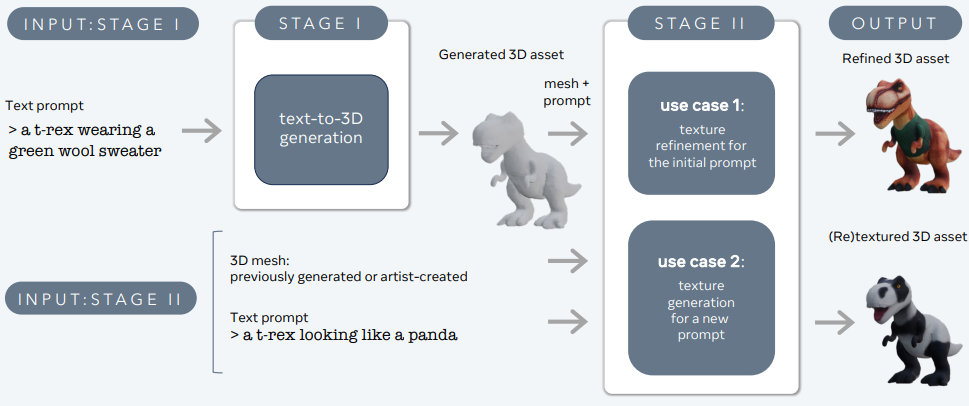
3DGen er designet til at tackle problemet med at generere 3D-indhold – såsom karakterer, rekvisitter og scener – ud fra tekstbeskrivelser.
3DGen understøtter fysisk-baseret rendering (PBR), der er afgørende for realistisk 3D-aktiveringslys i virkelige applikationer. Det muliggør også generativ omstrukturering af tidligere genererede eller kunstnerskabte 3D-former ved hjælp af nye tekstinput. Pipelinen integrerer to kernekomponenter: Meta 3D AssetGen og Meta 3D TextureGen, som håndterer henholdsvis tekst-til-3D og tekst-til-tekstur-generering.
Meta 3D AssetGen
Meta 3D AssetGen (Siddiqui et al., 2024) er ansvarlig for den indledende generering af 3D-aktiver fra tekstprompter. Denne komponent producerer et 3D-net med teksturer og PBR-materialekort på cirka 30 sekunder.
Meta 3D TextureGen
Meta 3D TextureGen (Bensadoun et al., 2024) forfiner de teksturer, der genereres af AssetGen. Det kan også bruges til at generere nye teksturer til eksisterende 3D-masker baseret på yderligere tekstbeskrivelser. Denne fase tager cirka 20 sekunder.
Point-E (OpenAI)
Point-E, udviklet af OpenAI, er en anden bemærkelsesværdig tekst-til-3D-genereringsmodel. I modsætning til DreamFusion, som producerer NeRF-repræsentationer, genererer Point-E 3D-punktskyer.
Nøglefunktioner ved Point-E:
a) To-trins rørledning: Point-E genererer først en syntetisk 2D-visning ved hjælp af en tekst-til-billede diffusionsmodel, og bruger derefter dette billede til at konditionere en anden diffusionsmodel, der producerer 3D-punktskyen.
b) Effektivitet: Point-E er designet til at være beregningsmæssigt effektiv og i stand til at generere 3D-punktskyer på få sekunder på en enkelt GPU.
c) Farveoplysninger: Modellen kan generere farvede punktskyer, der bevarer både geometriske og udseendeoplysninger.
Begrænsninger:
Lavere troskab sammenlignet med mesh-baserede eller NeRF-baserede tilgange
Punktskyer kræver yderligere behandling for mange downstream-applikationer
Shap-E (OpenAI):
Med udgangspunkt i Point-E introducerede OpenAI Shap-E, som genererer 3D-masker i stedet for punktskyer. Dette adresserer nogle af begrænsningerne ved Point-E, samtidig med at beregningseffektiviteten bevares.
Nøglefunktioner i Shap-E:
a) Implicit repræsentation: Shap-E lærer at generere implicitte repræsentationer (signerede afstandsfunktioner) af 3D-objekter.
b) Mesh ekstraktion: Modellen bruger en differentierbar implementering af algoritmen for marcherende terninger til at konvertere den implicitte repræsentation til et polygonalt net.
c) Teksturgenerering: Shap-E kan også generere teksturer til 3D-maskerne, hvilket resulterer i mere visuelt tiltalende output.
fordele:
Hurtige generationstider (sekunder til minutter)
Direkte mesh-output velegnet til rendering og downstream-applikationer
Evne til at generere både geometri og tekstur
GET3D (NVIDIA):
GET3D, udviklet af NVIDIA-forskere, er en anden kraftfuld tekst-til-3D-generationsmodel, der fokuserer på at producere højkvalitets teksturerede 3D-masker.
Nøglefunktioner i GET3D:
a) Eksplicit overfladerepræsentation: I modsætning til DreamFusion eller Shap-E genererer GET3D direkte eksplicitte overfladerepræsentationer (masker) uden mellemliggende implicitte repræsentationer.
b) Teksturgenerering: Modellen inkluderer en differentierbar gengivelsesteknik til at lære og generere teksturer af høj kvalitet til 3D-maskerne.
c) GAN-baseret arkitektur: GET3D bruger en generative adversarial network (GAN) tilgang, som giver mulighed for hurtig generering, når først modellen er trænet.
fordele:
Højkvalitets geometri og teksturer
Hurtige slutningstider
Direkte integration med 3D-gengivelsesmotorer
Begrænsninger:
Kræver 3D-træningsdata, som kan være knappe for nogle objektkategorier
Konklusion
Tekst-til-3D AI-generering repræsenterer et grundlæggende skift i, hvordan vi skaber og interagerer med 3D-indhold. Ved at udnytte avancerede deep learning-teknikker kan disse modeller producere komplekse 3D-aktiver af høj kvalitet ud fra simple tekstbeskrivelser. Efterhånden som teknologien fortsætter med at udvikle sig, kan vi forvente at se stadig mere sofistikerede og dygtige tekst-til-3D-systemer, der vil revolutionere industrier fra spil og film til produktdesign og arkitektur.
Jeg har brugt de sidste fem år på at fordybe mig i den fascinerende verden af Machine Learning og Deep Learning. Min passion og ekspertise har ført mig til at bidrage til over 50 forskellige software engineering projekter, med særligt fokus på AI/ML. Min vedvarende nysgerrighed har også trukket mig hen imod Natural Language Processing, et felt jeg er ivrig efter at udforske yderligere.