Tankeledere
3 måder at holde stælle fakta friske i store sprogmodeller
Store Sprogmodeller (LLM) som GPT3, ChatGPT og BARD er meget populære i dag. Alle har en mening om, hvordan disse værktøjer er gode eller dårlige for samfundet og hvad de betyder for fremtiden for AI. Google fik meget kritik for sin nye model BARD, der fik en kompleks spørgsmål forkert (lidt). Da de blev spurgt “Hvad nye opdagelser fra James Webb-rumteleskabet kan jeg fortælle min 9-årige om?” – gav chatbot’en tre svar, hvoraf 2 var rigtige og 1 var forkert. Det forkerte var, at den første “exoplanet”-billede blev taget af JWST, hvilket var forkert. Så grundlæggende havde modellen en forkert faktum gemt i sin videnbase. For store sprogmodeller til at være effektive, har vi brug for en måde at holde disse fakta opdaterede eller supplere fakta med ny viden.
Lad os først se, hvordan fakta er gemt inden i store sprogmodeller (LLM). Store sprogmodeller gemmer ikke information og fakta på en traditionel måde som databaser eller filer. I stedet er de blevet trænet på enorme mængder af tekstdata og har lært mønstre og relationer i denne data. Dette giver dem mulighed for at generere menneske-lignende svar på spørgsmål, men de har ikke en specifik lagringsplacering for deres lært information. Når de besvarer et spørgsmål, bruger modellen sin træning til at generere et svar baseret på inputtet, de modtager. Den information og viden, som en sprogmodel har, er et resultat af de mønstre, de har lært i den data, de er trænet på, og ikke et resultat af, at det er eksPLICIT gemt i modellens hukommelse. Transformers-arkitekturen, som de fleste moderne LLM’er er baseret på, har en intern kodning af fakta, der bruges til at besvare spørgsmålet i prompten.

Så, hvis fakta inden i den interne hukommelse af LLM er forkerte eller stælle, har vi brug for at give ny information via en prompt. Prompt er den tekst, der sendes til LLM med spørgsmålet og understøttende bevis, der kan være nogle nye eller korrekte fakta. Her er 3 måder at tilgå dette på.
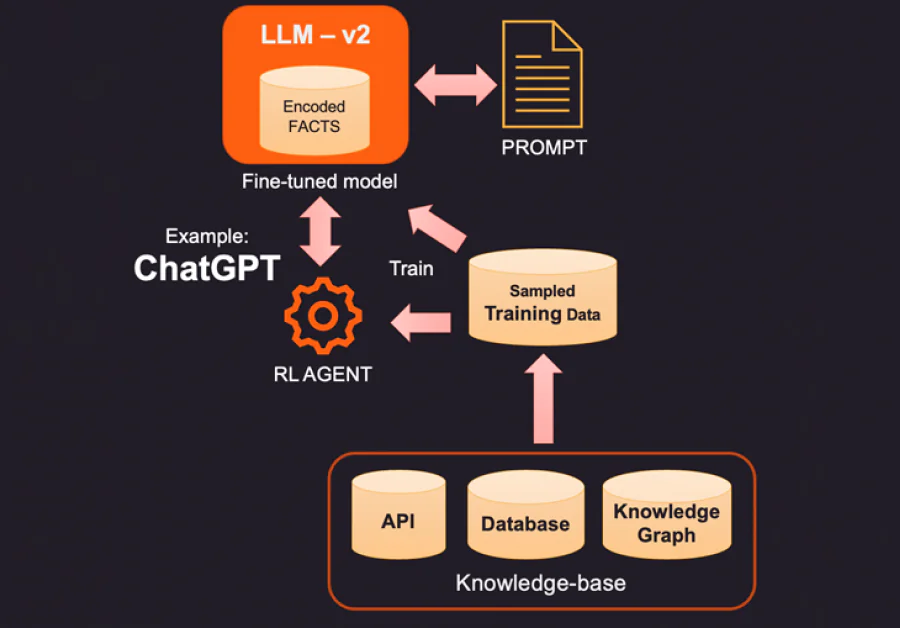
1. En måde at korrigere de kodede fakta i en LLM er at give nye fakta, der er relevante for konteksten, ved hjælp af en ekstern videnbase. Denne videnbase kan være API-kald til at få relevant information eller en opslag på en SQL-, No-SQL- eller Vektor-database. Mere avanceret viden kan udtrækkes fra en videngraf, der gemmer dataenheder og relationer mellem dem. Afhængigt af den information, brugeren spørger om, kan den relevante kontekstinformation hentes og gives som ekstra fakta til LLM. Disse fakta kan også formateres til at se ud som træningseksempler for at forbedre læringsprocessen. For eksempel kan du give en bunke spørgsmål og svarpar, så modellen kan lære, hvordan den kan give svar.

2. En mere innovativ (og mere dyre) måde at supplere LLM på er faktisk finjustering ved hjælp af træningsdata. I stedet for at spørge videnbasen om specifikke fakta til at tilføje, bygger vi en træningsdataset ved at udtage videnbasen. Ved hjælp af superviseret læringsteknikker som finjustering kan vi oprette en ny version af LLM, der er trænet på denne ekstra viden. Denne proces er normalt dyre og kan koste et par tusinde dollars at bygge og vedligeholde en finjusteret model i OpenAI. Selvfølgelig forventes omkostningerne at blive billigere over tid.
3. En anden mulighed er at bruge metoder som Forstærket Læring (RL) til at træne en agent med menneskelig feedback og lære en politik for, hvordan man besvarer spørgsmål. Denne metode har været meget effektiv til at bygge mindre fodaftryksmodeller, der bliver gode til bestemte opgaver. For eksempel var den berømte ChatGPT, der blev udgivet af OpenAI, trænet på en kombination af superviseret læring og RL med menneskelig feedback.

I sammenfattende er dette et højt udviklende område, hvor hver større virksomhed vil være med og vise deres differentiering. Vi vil snart se store LLM-værktøjer i de fleste områder som detail, sundhed og bank, der kan svare på en menneske-lignende måde og forstå nuancerne i sproget. Disse LLM-drevne værktøjer integreret med virksomhedsdata kan strømline adgangen og gøre den rigtige data tilgængelig for de rigtige mennesker på det rigtige tidspunkt.












