Umělá inteligence
Úplný průvodce Gemma 2: Googleův nový otevřený velký jazykový model

Gemma 2 staví na svém předchůdci, nabízí vylepšené výkony a efektivitu, spolu s řadou inovativních funkcí, které z něj dělají atraktivní možnost pro výzkum i praktické aplikace. To, co odlišuje Gemma 2, je její schopnost poskytovat výkon srovnatelný s mnohem většími proprietárními modely, ale v balíčku, který je navržen pro širší dostupnost a použití na skromnějších hardwarových konfiguracích.
Když jsem se ponořil do technických specifikací a architektury Gemma 2, stále více jsem byl ohromen vynalézavostí jejího designu. Model zahrnuje několik pokročilých technik, včetně nových mechanismů pozornosti a inovativních přístupů ke stabilitě školení, které přispívají k jejím pozoruhodným schopnostem.

Google Open Source LLM Gemma
V tomto komplexním průvodci prozkoumáme Gemma 2 do hloubky, zkoumající její architekturu, klíčové funkce a praktické aplikace. Bez ohledu na to, zda jste zkušený odborník v oblasti AI nebo nadšený nováček v oboru, tento článek si klade za cíl poskytnout cenné poznatky o tom, jak Gemma 2 funguje a jak můžete využít její sílu ve svých vlastních projektech.
Co je Gemma 2?
Gemma 2 je Googleův nejnovější otevřený velký jazykový model, navržen tak, aby byl lehký, ale výkonný. Je postaven na stejném výzkumu a technologiích, které byly použity pro vytvoření modelů Gemini, nabízí špičkový výkon v přístupnějším balíčku. Gemma 2 je k dispozici ve dvou velikostech:
Gemma 2 9B: Model s 9 miliardami parametrů
Gemma 2 27B: Větší model s 27 miliardami parametrů
Každá velikost je k dispozici ve dvou variantách:
Základní modely: Předškolené na rozsáhlém korpusu textových dat
Modely s instrukcemi (IT): Jemně vyškolené pro lepší výkon na specifických úkolech
Přístup k modelům v Google AI Studio: Google AI Studio – Gemma 2
Přečtěte si technickou zprávu zde: Technická zpráva Gemma 2
Klíčové funkce a vylepšení
Gemma 2 představuje několik významných pokroků oproti svému předchůdci:
1. Zvýšená školicí data
Modely byly školeny na podstatně více datech:
Gemma 2 27B: Školen na 13 bilionech tokenů
Gemma 2 9B: Školen na 8 bilionech tokenů
Tento rozšířený dataset, který se skládá主要ně z webových dat (převážně anglicky), kódu a matematiky, přispívá k vylepšenému výkonu a všestrannosti modelů.
2. Pozornost se skluzavým oknem
Gemma 2 implementuje novou metodu mechanismů pozornosti:
Každá druhá vrstva používá pozornost se skluzavým oknem s místním kontextem 4096 tokenů
Střídající se vrstvy využívají plnou kvadratickou globální pozornost napříč celým kontextem 8192 tokenů
Tento hybridní přístup si klade za cíl vyvážit efektivitu se schopností zachytit dlouhodobé závislosti ve vstupu.
3. Měkké omezení
Pro zlepšení stability školení a výkonu Gemma 2 zavádí mechanismus měkkého omezení:
def soft_cap(x, cap): return cap * torch.tanh(x / cap) # Použito na logity pozornosti attention_logits = soft_cap(attention_logits, cap=50.0) # Použito na logity finální vrstvy final_logits = soft_cap(final_logits, cap=30.0)
Tato technika brání růstu logitů příliš velkých bez tvrdého omezení, zachovává více informací a stabilizuje proces školení.
- Gemma 2 9B: Model s 9 miliardami parametrů
- Gemma 2 27B: Větší model s 27 miliardami parametrů
Každá velikost je k dispozici ve dvou variantách:
- Základní modely: Předškolené na rozsáhlém korpusu textových dat
- Modely s instrukcemi (IT): Jemně vyškolené pro lepší výkon na specifických úkolech
4. Přenos znalostí
Pro model 9B Gemma 2 využívá techniky přenosu znalostí:
- Předškolení: Model 9B se učí od většího učitele během počátečního školení
- Po školení: Obě modely 9B a 27B využívají on-policy destilaci pro jemné vylepšení jejich výkonu
Tento proces pomáhá menšímu modelu lépe zachytit schopnosti větších modelů.
5. Sloučení modelů
Gemma 2 využívá novou techniku sloučení modelů nazvanou Warp, která kombinuje více modelů ve třech fázích:
- Exponenciální pohyblivý průměr (EMA) během jemného školení pomocí posilovacího učení
- Sférická lineární interpolace (SLERP) po jemném školení více politik
- Lineární interpolace směrem k inicializaci (LITI) jako konečná fáze
Tento přístup si klade za cíl vytvořit robustnější a schopnější konečný model.
Běžné testy
Gemma 2 prokazuje působivý výkon napříč různými testy:
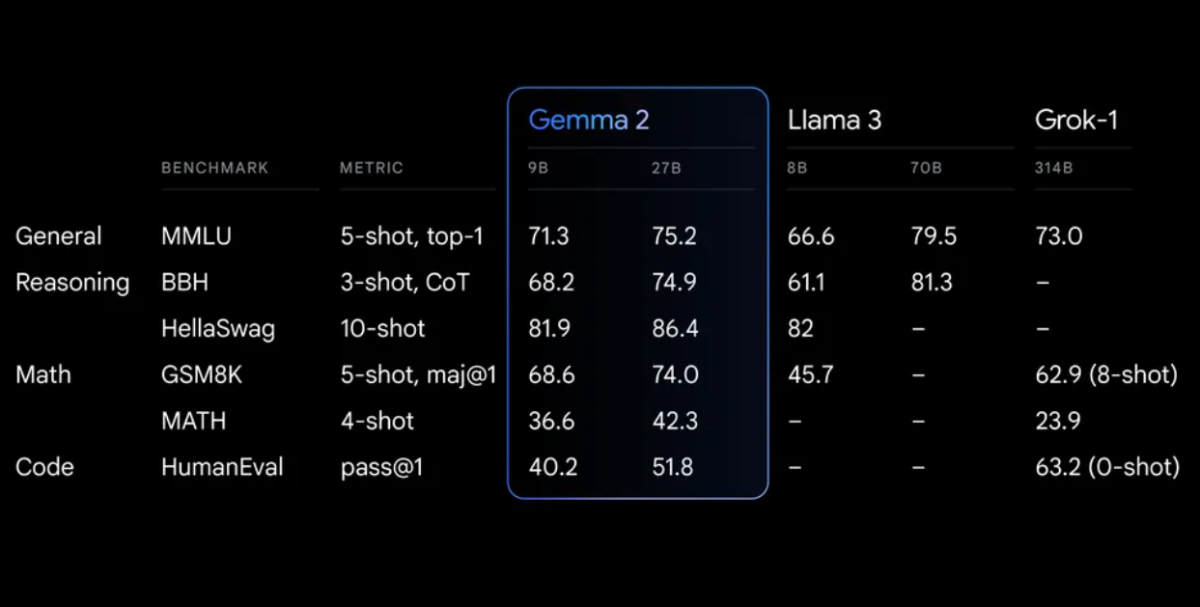
Gemma 2 na přepracované architektuře, navržené pro výjimečný výkon a efektivitu inferencí
Zahájení práce s Gemma 2
Abyste mohli začít používat Gemma 2 ve svých projektech, máte několik možností:
1. Google AI Studio
Pro rychlé experimenty bez požadavků na hardware můžete přistupovat k Gemma 2 prostřednictvím Google AI Studio.
2. Hugging Face Transformers
Gemma 2 je integrována s populární knihovnou Hugging Face Transformers. Zde je, jak můžete použít:
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> from transformers import AutoTokenizer, AutoModelForCausalLM # Načtení modelu a tokenizéru model_name = "google/gemma-2-27b-it" # nebo "google/gemma-2-9b-it" pro menší verzi tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # Příprava vstupu prompt = "Vysvětlit koncept kvantového provázání v jednoduchých termínech." inputs = tokenizer(prompt, return_tensors="pt") # Generování textu outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response)
3. TensorFlow/Keras
Pro uživatele TensorFlow je Gemma 2 k dispozici prostřednictvím Keras:
import tensorflow as tf
from keras_nlp.models import GemmaCausalLM
# Načtení modelu
model = GemmaCausalLM.from_preset("gemma_2b_en")
# Generování textu
prompt = "Vysvětlit koncept kvantového provázání v jednoduchých termínech."
output = model.generate(prompt, max_length=200)
print(output)
Pokročilé použití: Vytvoření místního RAG systému s Gemma 2
Jedním z mocných použití Gemma 2 je vytvoření systému RAG (Retrieval Augmented Generation). Vytvoříme jednoduchý, plně místní RAG systém pomocí Gemma 2 a Nomic embeddings.
Krok 1: Nastavení prostředí
Nejprve zajistěte, že máte nainstalované nezbytné knihovny:
pip install langchain ollama nomic chromadb
Krok 2: Indexování dokumentů
Vytvořte indexer pro zpracování vašich dokumentů:
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings












