زاوية Anderson
أخطار استخدام الاقتباسات لتأكي德 محتوى NLG

رأي نماذج التوليد اللغوي الطبيعي مثل GPT-3 معرضة ل “الحلم” بمواد تقدمها في سياق المعلومات الواقعية. في عصر يهتم بشكل استثنائي بنمو الأخبار الكاذبة القائمة على النص، تمثل هذه “الرحلات الخيالية” التي تهدف إلى إرضاء الجميع عقبة وجودية لتطوير الأنظمة الآلية للكتابة والتلخيص، ومستقبل “الصحافة القائمة على الذكاء الاصطناعي“، من بين مجالات فرعية أخرى من معالجة اللغة الطبيعية (NLP).
المشكلة المركزية هي أن نماذج اللغة مثل GPT تستمد ميزاتها الرئيسية وتصنيفاتها من مكتبات كبيرة جدًا من النصوص التدريبية، وتتعلم استخدام هذه الميزات كوحدات بناء للغة ببراعة وصدق، بغض النظر عن دقة المحتوى المولد أو حتى قابليته للقبول.
لذلك، تعتمد أنظمة NLG حاليًا على التحقق البشري من الحقائق إما من خلال استخدام النماذج كمولدات نص أولية يتم تمريرها على الفور إلى المستخدمين البشرين، إما للتحقق أو بعض أشكال التحرير أو التعديل؛ أو أن البشر يستخدمون كمرشحات مكلفة لتحسين جودة مجموعات البيانات الموجهة إلى نماذج أقل تجريدًا و “إبداعية” (التي من الصعب بالفعل الثقة بها من حيث الدقة الواقعية، وستتطلب طبقات إضافية من الرقابة البشرية).
أخبار قديمة وحقائق كاذبة
نماذج التوليد اللغوي الطبيعي (NLG) قادرة على إنتاج خرج مقنع ومقبول لأنها تعلمت الهندسة المعمارية الدلالية، بدلاً من امتصاص التاريخ أو العلوم أو الاقتصاد أو أي موضوع آخر بشكل مجرد، والذي يتم دمجه بشكل فعال ك “راكب” في بيانات المصدر.
دقة الحقائق للمعلومات التي تولد نماذج NLG تفترض أن الإدخال الذي يتم تدريبها عليه موثوق به ومتديث، مما يعرض عبئًا استثنائيًا فيما يتعلق بالمراحل الأولية والتحقق البشري الإضافي – عائق باهظ التكلفة الذي يتعامل قطاع البحث في معالجة اللغة الطبيعية معه حاليًا من عدة جهات.
نظام GPT-3 يستغرق وقتًا طويلاً ومالًا لتدريبه، وعندما يتم تدريبه، يصعب تحديثه على ما يمكن اعتباره “مستوى النواة”. على الرغم من أن التعديلات المحلية للجلسة والاستخدام يمكن أن تزيد من فائدة النماذج المطبقة وضبطها، فإن هذه الفوائد المفيدة صعبة وأحيانًا مستحيلة النقل إلى النموذج الأساسي دون الحاجة إلى إعادة التدريب الكامل أو الجزئي.
لهذا السبب، من الصعب إنشاء نماذج لغة مدربة يمكنها استخدام أحدث المعلومات.

تم تدريبها قبل الغزو الأوكراني عام 2022، ويمكن لنموذج text-davinci-002 – الذي يُعتبر أكثر إمكانيات GPT-3 من قبل مبتكره OpenAI – معالجة 4000 رمز لكل طلب، لكنه لا يعرف أي شيء عن كوفيد-19 أو الغزو الأوكراني (هذه التحفيزات والاستجابات هي من 5 أبريل 2022). من المثير للاهتمام أن “مجهول” هو في الواقع जवاب مقبول في كلتا الحالتين، لكن التحفيزات الإضافية تثبت بسهولة أن GPT-3 لا يعرف هذه الأحداث. مصدر: https://beta.openai.com/playground
يمكن لنماذج مدربة الوصول فقط إلى “الحقائق” التي داخلتها في وقت التدريب، ومن الصعب الحصول على اقتباس دقيق ومُلائم افتراضيًا عند محاولة الحصول على نموذج للتحقق من ادعاءاته. خطر حقيقي لتحقيق الاقتباسات من GPT-3 افتراضي (على سبيل المثال) هو أنه ينتج أحيانًا اقتباسات صحيحة، مما يؤدي إلى ثقة خاطئة في هذا الجانب من قدراته:

أعلى، ثلاث اقتباسات دقيقة تم الحصول عليها بواسطة GPT-3 davinci-instruct-text في عام 2021. في الوسط، يفشل GPT-3 في ذكر واحدة من اقتباسات أينشتاين الأكثر شهرة ("الله لا يلعب النرد مع الكون")، على الرغم من التحفيز غير الغامض. في الأسفل، يخصص GPT-3 اقتباس فاضح وزائف لألبرت أينشتاين، على ما يبدو من الانسياب من أسئلة سابقة عن ونستون تشرشل في نفس الجلسة. مصدر: المقال الخاص بالمؤلف في https://www.width.ai/post/business-applications-for-gpt-3
GopherCite
في محاولة لتصحيح هذا النقص العام في نماذج NLG، اقترح DeepMind التابع لجوجل مؤخرًا GopherCite، نموذج يحتوي على 280 مليار معامل وقادر على ذكر أدلة محددة ودقيقة لدعم استجاباته المولدة للتحفيزات.



ثلاثة أمثلة على GopherCite التي تدعم ادعاءاتها بالاقتباسات الحقيقية. مصدر: https://arxiv.org/pdf/2203.11147.pdf
يستخدم GopherCite التعلم بالتعزيز من التفضيلات البشرية (RLHP) لتدريب نماذج الاستعلام القادرة على ذكر اقتباسات حقيقية كدليل داعم. يتم سحب الاقتباسات مباشرة من مصادر وثائق متعددة تم الحصول عليها من محركات البحث، أو من وثيقة محددة تم توفيرها من قبل المستخدم.
تم قياس أداء GopherCite من خلال التقييم البشري لاستجابات النموذج، والتي تم العثور عليها لتكون “جودة عالية” بنسبة 80٪ من الوقت على مجموعة بيانات NaturalQuestions التابعة لجوجل، و 67٪ من الوقت على مجموعة بيانات ELI5.
اقتباسات كاذبة
然而، عندما تم اختبارها ضد معيار TruthfulQA التابع لجامعة أكسفورد، نادرًا ما تم تصنيف استجابات GopherCite على أنها صادقة، بالمقارنة مع الإجابات “صحيحة” المحددة من قبل البشر.
يقترح المؤلفون أن هذا因为 مفهوم “الإجابات المدعومة” لا يساهم بأي شكل موضوعي في تعريف الحقيقة نفسها، منذ أن يمكن أن تكون مفيدة مصادر الاقتباسات متأثرة بعوامل أخرى، مثل احتمال أن يكون مؤلف الاقتباس نفسه “حالمًا” (أي يكتب عن عوالم خيالية، أو ينتج محتوى إعلاني، أو يخترع مواد غير حقيقية بطرق أخرى).



حالات GopherCite حيث لا يترافق القبول مع “الحقيقة” بالضرورة.
بصورة فعالة، يصبح من الضروري التمييز بين “مدعوم” و “صحيح” في مثل هذه الحالات. الثقافة البشرية حاليًا متقدمة جدًا على التعلم الآلي فيما يتعلق باستخدام منهجيات وإطارات مصممة للحصول على تعريفات موضوعية للحقائق، وحتى هناك، يبدو أن حالة “الحقيقة” المهمة هي الخلاف والإنكار الهامشي.
المشكلة متكررة في архيتكتشرات NLG التي تسعى إلى وضع آليات “مؤكدة” حاسمة: يتم الضغط على الإجماع البشري كبENCHMARK للحقيقة من خلال نماذج AMT الخارجة، حيث يكون المvaluators البشر (وأولئك البشر الآخرون الذين يوسطون النزاعات بينهم) هم أنفسهم جزئيين ومحايدين.
على سبيل المثال، تستخدم تجارب GopherCite الأولية نموذج “مُحكِّم siêu” لاختيار أفضل موضوعات بشرية لتقييم مخرجات النموذج، حيث يتم اختيار فقط المُحَكِّمين الذين حصلوا على نسبة 85٪ على الأقل بالمقارنة مع مجموعة ضمان الجودة. في النهاية، تم اختيار 113 مُحَكِّمًا siêu لل任务.
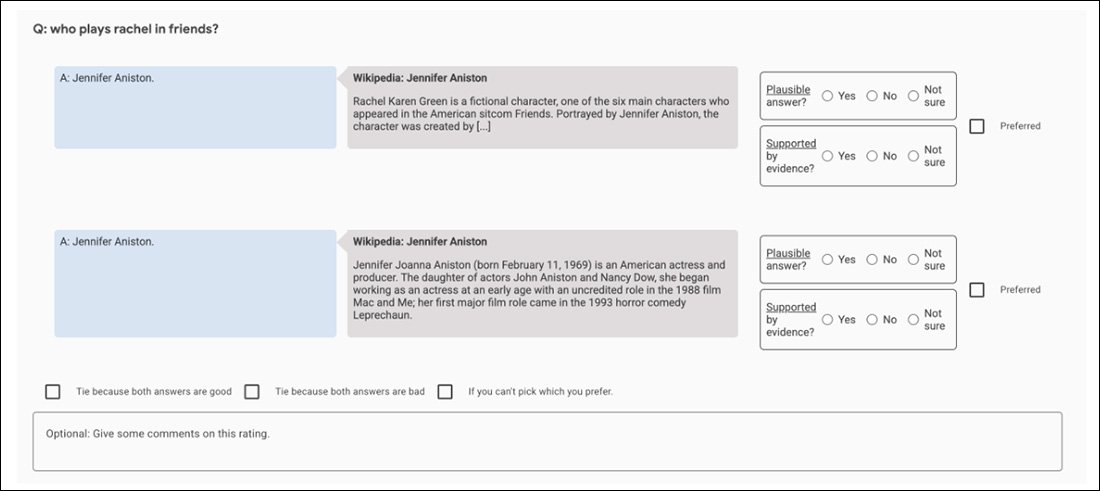
لقطة شاشة لتطبيق المقارنة المستخدم لمساعدة تقييم مخرجات GopherCite.
يمكن القول إن هذا هو صورة مثالية لمطاردة غير قابلة للفوز: مجموعة ضمان الجودة المستخدمة لتقييم المُحَكِّمين هي في حد ذاتها معيار آخر “محدد من البشر” للحقيقة، كما هو الحال مع مجموعة TruthfulQA التابعة لجامعة أكسفورد التي وجدت GopherCite عاجزة عن مواكبتها.
فيما يتعلق بمحتوى مدعوم و “مؤكد”، لا يمكن لنماذج NLG أن تتطلع إلى تحليل أي شيء من بيانات التدريب البشرية إلا التنوع والاختلاف البشري، وهو في حد ذاته مشكلة غير محددة وغير محلولة. لدينا ميل فطري للاقتباس من مصادر تدعم وجهات نظرنا، والتحدث بسلطة واقتناع في الحالات التي قد تكون فيها معلومات المصدر قديمة أو غير دقيقة أو مضللة عمدًا بطرق أخرى؛ و밀 إلى نشر هذه الآراء مباشرة في البرية، بنطاق وفعالية غير مسبوقة في التاريخ البشري، مباشرة في طريق إطارات الحصاد المعرفي التي تغذي إطارات NLG الجديدة.
لذلك، يبدو أن الخطر المترتب على تطوير أنظمة NLG مدعومة الاقتباسات مرتبط بطبع المواد المصدر غير متوقع. أي آليات (مثل الاقتباسات المباشرة) التي تزيد من ثقة المستخدم في مخرجات NLG هي، في حالة الحالة الحالية، تضيف بشكل خطير إلى الصدق، وليس الصحة، للمخرجات.
من المحتمل أن تكون هذه التقنيات كافية عندما ينجح NLP في cuốiًا في إعادة إنشاء “كاليديسكوبس” لكتابة الخيال في رواية أورويل “1984”؛ لكنها تمثل مطاردة خطيرة لتحليل الوثائق الموضوعي والصحافة القائمة على الذكاء الاصطناعي، وتطبيقات أخرى محتملة لتلخيص الآلة والنص التوليدي الموجه أو التلقائي.
نشر لأول مرة في 5 أبريل 2022. تم تحديثه في الساعة 3:29 مساءً بتوقيت شرق أوروبا لتصحيح المصطلح.












