الذكاء الاصطناعي
AudioSep : افصل أي شيء تصفه
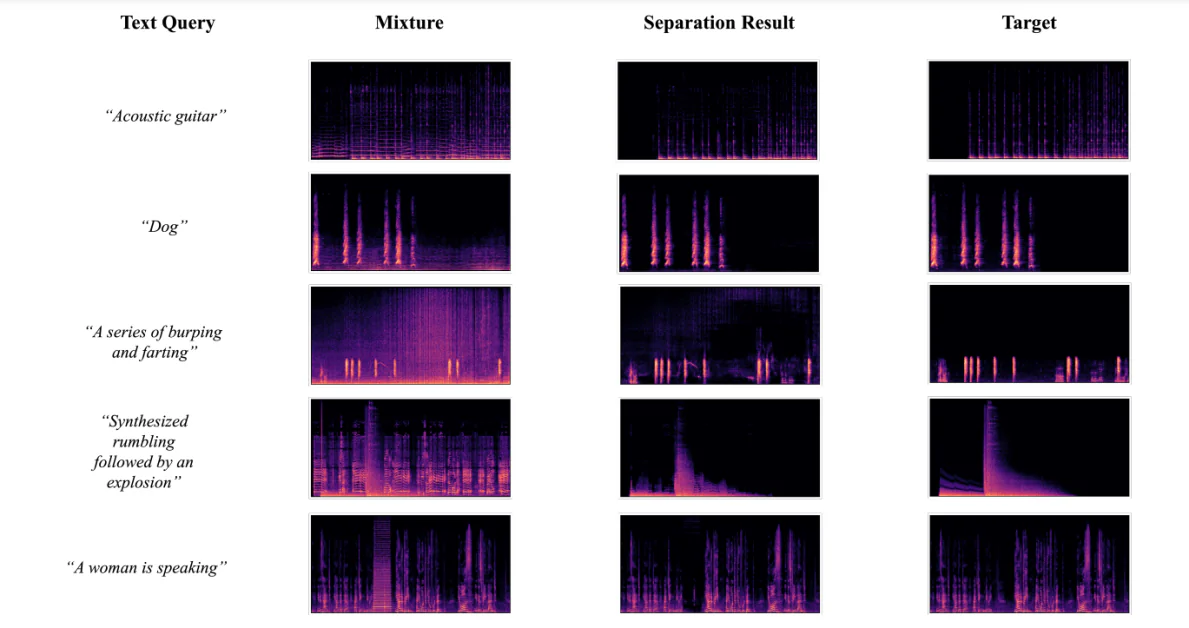
LASS أو Language-queried Audio Source Separation هو نموذج جديد للـ CASA أو Computational Auditory Scene Analysis يهدف إلى فصل صوت مستهدف من مزيج صوتي معين باستخدام استعلام لغة طبيعية يوفر واجهة قابلة للتطوير ومستدامة للمهام والتطبيقات الصوتية الرقمية. على الرغم من أن إطارات LASS قد تقدمت بشكل كبير في السنوات القليلة الماضية فيما يتعلق بالحصول على الأداء المطلوب على مصادر صوتية محددة مثل الآلات الموسيقية ، إلا أنها غير قادرة على فصل الصوت المستهدف في المجال المفتوح.
AudioSep ، هو نموذج أساسي يهدف إلى حل القيود الحالية لإطارات LASS من خلال تمكين فصل الصوت المستهدف باستخدام استعلامات لغة طبيعية. قام مطورو إطار AudioSep بتدريب النموذج بشكل مكثف على مجموعة واسعة من مجموعات البيانات الكبيرة متعددة الوسائط ، وتقييم أداء الإطار على مجموعة واسعة من المهام الصوتية بما في ذلك فصل الآلات الموسيقية وفصل الأحداث الصوتية وتحسين الكلام من بين أمور أخرى. يلبي الأداء الأولي لبرنامج AudioSep المعايير حيث يظهر أداءً قويًا في التعلم من الصفر ويوفر أداءً جيدًا في فصل الصوت.
في هذا المقال ، سنقوم بالغوص بشكل أعمق في عمل إطار AudioSep حيث سنقوم بتقييم هندسة النموذج ومجموعات البيانات المستخدمة للتدريب والتقييم والمفاهيم الأساسية المشاركة في عمل نموذج AudioSep. لذلك دعونا نبدأ بمقدمة أساسية إلى إطار CASA.
CASA, USS, QSS, LASS الإطارات : الأساس لبرنامج AudioSep
إطار CASA أو Computational Auditory Scene Analysis هو إطار يستخدمه المطورون لتصميم أنظمة الاستماع الآلية التي لديها القدرة على إدراك بيئات الصوت المعقدة بطريقة مشابهة لطريقة إدراك البشر للصوت باستخدام أنظمة السمع الخاصة بهم. فصل الصوت ، مع التركيز الخاص على فصل الصوت المستهدف ، هو مجال بحث أساسي داخل إطار CASA ، ويهدف إلى حل “مشكلة الحفلة” أو فصل التسجيلات الصوتية الحقيقية من تسجيلات المصدر الصوتي الفردية أو الملفات.
معظم الأعمال على فصل الصوت التي تم إجراؤها في الماضي تدور حول فصل مصدر أو أكثر من المصادر الصوتية مثل فصل الموسيقى أو فصل الكلام. نموذج جديد يحمل اسم USS أو Universal Sound Separation يهدف إلى فصل الأصوات التعسفية في التسجيلات الصوتية الحقيقية. ومع ذلك ، فإن فصل كل مصدر صوتي من مزيج صوتي يعتبر مهمة صعبة ومقيدة بسبب وجود مجموعة واسعة من المصادر الصوتية المختلفة في العالم وهو السبب الرئيسي لعدم جدوى طريقة USS للتطبيقات الحقيقية التي تعمل في الوقت الفعلي.
بديل قابل للتطبيق لطريقة USS هو طريقة QSS أو Query-based Sound Separation التي تهدف إلى فصل مصدر صوتي فردي أو مستهدف من مزيج صوتي بناءً على مجموعة معينة من الاستعلامات. بفضل ذلك ، يسمح إطار QSS للمطورين والمستخدمين باستخراج المصادر الصوتية المرغوبة من المزيج بناءً على متطلباتهم مما يجعل طريقة QSS حلاً أكثر واقعية للتطبيقات الرقمية الحقيقية مثل تحرير المحتوى المتعددي أو تحرير الصوت.
علاوة على ذلك ، اقترح المطورون مؤخرًا تمديد إطار QSS ، وهو إطار LASS أو Language-queried Audio Source Separation الذي يهدف إلى فصل مصادر الصوت التعسفية من مزيج صوتي باستخدام وصفات اللغة الطبيعية للمصدر الصوتي المستهدف. نظرًا لأن إطار LASS يسمح للمستخدمين باستخراج مصادر الصوت المستهدفة باستخدام مجموعة من التوجيهات اللغوية الطبيعية ، فقد يصبح أداة قوية ذات تطبيقات واسعة في التطبيقات الصوتية الرقمية.
في الأصل ، يعتمد إطار LASS على التعلم الإشرافي الذي يتم فيه تدريب النموذج على مجموعة من بيانات الصوت والنص المرتبط والمسمى. ومع ذلك ، فإن المشكلة الرئيسية في هذا النهج هي محدودية توافر بيانات الصوت والنص المسمى. من أجل تقليل اعتماد إطار LASS على بيانات الصوت والنص المسمى ، يتم تدريب النماذج باستخدام نهج التعلم الإشرافي المتعدد الوسائط.
الغرض الرئيسي من استخدام نهج التعلم الإشرافي المتعدد الوسائط هو استخدام نماذج التعلم الإشرافي المتعددة الوسائط مثل نموذج CLIP أو Contrastive Language Image Pre Training ككود الاستعلام لإطار العمل. نظرًا لأن إطار CLIP لديه القدرة على محاذاة التضمين النصي مع الوسائط الأخرى مثل الصوت أو الرؤية ، therefore يسمح للمطورين بتدريب نماذج LASS باستخدام بيانات غنية بالوسائط ، ويتداخل مع البيانات النصية في إعداد من الصفر.
AudioSep : المكونات الرئيسية والهندسة
تتكون هندسة إطار AudioSep من مكونين رئيسيين: كودر نصي ونموذج فصل.
كودر النص
يستخدم إطار AudioSep كودر نصي من نموذج CLIP أو Contrastive Language Image Pre Training أو نموذج CLAP أو Contrastive Language Audio Pre Training لاستخراج التضمين النصي من استعلام لغة طبيعية.
نموذج الفصل
يستخدم إطار AudioSep نموذج ResUNet في مجال التردد كنموذج فصل للعين.
التدريب والخسارة
خلال تدريب نموذج AudioSep ، يستخدم المطورون طريقة تعزيز الصوت ، ويدربون إطار AudioSep من النهاية إلى النهاية باستخدام دالة خسارة L1 بين الشكل الموجي الحقيقي والمتوقع.
مجموعات البيانات والمراجع
كما ذكر في الأقسام السابقة ، AudioSep هو نموذج أساسي يهدف إلى حل الاعتماد الحالي لنماذج LASS على مجموعات بيانات الصوت والنص المسمى.
AudioSet
AudioSet هو مجموعة بيانات صوتية كبيرة الحجم تم تصنيفها بشكل ضعيف تتكون من أكثر من 2 مليون مقطع صوتي dài 10 ثواني مستخرجة مباشرة من YouTube.
VGGSound
مجموعة بيانات VGGSound هي مجموعة بيانات صوتية وبصرية كبيرة الحجم تم استخلاصها أيضًا من YouTube ، وتحتوي على أكثر من 200000 مقطع فيديو ، كل مقطع له طول 10 ثواني.
AudioCaps
AudioCaps هو أكبر مجموعة بيانات تعليم الصوت المتاحة للجمهور ، ويتكون من أكثر من 50000 مقطع صوتي dài 10 ثواني مستخرجة من مجموعة بيانات AudioSet.
نتائج التقييم
على مجموعات البيانات المرئية
الرسم التالي ي比較 أداء إطار AudioSep على مجموعات البيانات المرئية خلال مرحلة التدريب بما في ذلك مجموعات البيانات للتدريب.
على مجموعات البيانات غير المرئية
为了 تقييم أداء AudioSep في إعداد من الصفر ، واصل المطورون تقييم الأداء على مجموعات البيانات غير المرئية ، ويقدم إطار AudioSep أداء فصل قوي في إعداد من الصفر ، والنتائج معروضة في الرسم التالي.
الاستنتاج
AudioSep هو نموذج أساسي تم تطويره بهدف أن يكون إطار فصل صوت عالمي في المجال المفتوح باستخدام وصفات اللغة الطبيعية لفصل الصوت. كما لوحظ خلال التقييم ، فإن إطار AudioSep قادر على أداء التعلم من الصفر والتعلم غير المشرّف بشكل سلس باستخدام التسميات النصية أو التسميات الصوتية كاستعلامات.












