人工智能
Zero123++:单图像到一致的多视图扩散基础模型

过去几年,新兴小说的性能、效率和生成能力都在快速进步。 人工智能生成模型 利用广泛的数据集和二维扩散生成实践。 如今,生成式 AI 模型非常有能力生成不同形式的 2D,在某种程度上,还可以生成 2D 媒体内容,包括文本、图像、视频、GIF 等。
在本文中,我们将讨论 Zero123++ 框架,这是一种图像条件扩散生成 AI 模型,旨在使用单视图输入生成 3D 一致的多视图图像。 为了最大限度地发挥先前预训练生成模型的优势,Zero123++ 框架实施了大量的训练和调节方案,以最大程度地减少从现成的扩散图像模型进行微调所需的工作量。 我们将更深入地研究 Zero123++ 框架的架构、工作原理和结果,并分析其从单个图像生成一致的高质量多视图图像的能力。 那么让我们开始吧。
Zero123 和 Zero123++:简介
Zero123++ 框架是一个基于图像条件的扩散生成式 AI 模型,旨在使用单视图输入生成 3D 一致的多视图图像。Zero123++ 框架是 Zero123 或 Zero-1-to-3 框架的延续,它利用零样本新视图图像合成技术,开创了开源单图像到 3D 的转换。尽管 Zero123++ 框架的性能表现令人瞩目,但其生成的图像存在明显的几何不一致性,这也是 3D 场景与多视图图像之间仍然存在差距的主要原因。
Zero-1-to-3 框架是其他几个框架的基础,包括 SyncDreamer、One-2-3-45、Concient123 等,这些框架向 Zero123 框架添加了额外的层,以便在生成 3D 图像时获得更一致的结果。 其他框架(如 ProlificDreamer、DreamFusion、DreamGaussian 等)遵循基于优化的方法,通过从各种不一致的模型中提取 3D 图像来获取 3D 图像。 尽管这些技术很有效,并且可以生成令人满意的 3D 图像,但通过实施能够一致生成多视图图像的基础扩散模型,可以改进结果。 因此,Zero123++ 框架采用了 Zero-1 to-3,并从 Stable Diffusion 中微调了新的多视图基础扩散模型。
在零一到三的框架中,每个新颖的视图都是独立生成的,这种方法会导致生成的视图之间不一致,因为扩散模型具有采样性质。 为了解决这个问题,Zero1++框架采用了平铺布局的方法,将对象由六个视图包围成一个图像,并确保对对象的多视图图像的联合分布进行正确的建模。
使用 Zero-1-to-3 框架的开发人员面临的另一个主要挑战是,它没有充分利用 稳定扩散 这最终会导致效率低下并增加成本。 零一到三框架无法最大化稳定扩散所提供的能力有两个主要原因
- 当使用图像条件进行训练时,零一到三框架没有有效地结合稳定扩散提供的局部或全局调节机制。
- 在训练期间,零一到三框架使用降低的分辨率,这种方法将输出分辨率降低到低于训练分辨率,这会降低稳定扩散模型的图像生成质量。
为了解决这些问题,Zero123++ 框架实现了一系列调节技术,最大限度地利用稳定扩散提供的资源,并保持稳定扩散模型的图像生成质量。
改善条件和一致性
为了改善图像调节和多视图图像一致性,Zero123++ 框架实现了不同的技术,主要目标是重用源自预训练稳定扩散模型的现有技术。
多视图生成
生成一致的多视图图像不可或缺的品质在于正确地对多个图像的联合分布进行建模。 在 Zero-1-to-3 框架中,多视图图像之间的相关性被忽略,因为对于每个图像,该框架独立且单独地对条件边缘分布进行建模。 然而,在 Zero123++ 框架中,开发人员选择了平铺布局方法,将 6 个图像平铺到单个帧/图像中,以实现一致的多视图生成,下图演示了该过程。
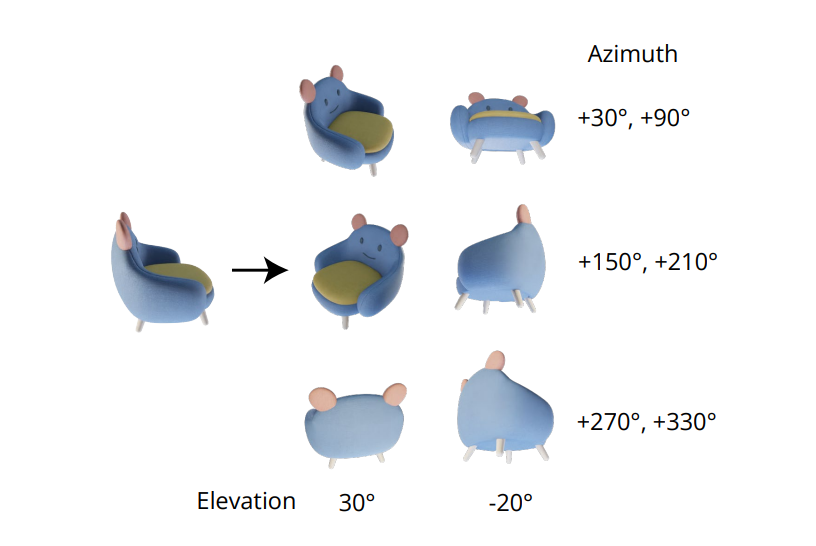

此外,人们注意到,在根据相机姿势训练模型时,物体方向往往会消除歧义,为了防止这种歧义消除,Zero-1-to-3 框架使用输入的仰角和相对方位角来训练相机姿势。 为了实现这种方法,有必要知道输入视图的仰角,然后使用该仰角来确定新输入视图之间的相对姿势。 为了了解这个仰角,框架通常会添加一个仰角估计模块,而这种方法通常会以管道中的额外误差为代价。
噪音表
缩放线性计划,稳定扩散的原始噪声计划主要关注局部细节,但如下图所示,它的步骤很少,SNR 或信噪比较低。


这些低信噪比的步骤发生在去噪阶段的早期,这是确定全局低频结构的关键阶段。 在干扰或训练期间减少去噪阶段的步骤数通常会导致更大的结构变化。 尽管此设置非常适合单图像生成,但它确实限制了框架确保不同视图之间全局一致性的能力。 为了克服这一障碍,Zero123++ 框架在 Stable Diffusion 2 v 预测框架上对 LoRA 模型进行了微调,以执行玩具任务,结果如下所示。

通过缩放线性噪声表,LoRA 模型不会过度拟合,而只会使图像稍微变白。 相反,当使用线性噪声调度时,无论输入提示如何,LoRA 框架都会成功生成空白图像,从而表明噪声调度对框架适应全局新要求的能力的影响。
针对当地条件的缩放参考注意力
将零一到三框架中的单视图输入或调节图像与特征维度中的噪声输入连接起来,以对图像调节进行噪声处理。
这种串联导致目标图像和输入之间的像素级空间对应不正确。 为了提供适当的局部调节输入,Zero123++ 框架使用了缩放参考注意,这是一种在额外参考图像上运行去噪 UNet 模型的方法,然后附加来自参考的值矩阵和自注意键当模型输入去噪时,图像到各个注意力层,如下图所示。

参考注意方法能够指导扩散模型生成与参考图像共享相似纹理和语义内容的图像,而无需任何微调。 通过微调,参考注意力方法可通过缩放潜在值提供卓越的结果。

全局调节:FlexDiffuse
在最初的稳定扩散方法中,文本嵌入是全局嵌入的唯一来源,该方法采用 CLIP 框架作为文本编码器来执行文本嵌入和模型潜在之间的交叉检查。 因此,开发人员可以自由地使用文本空间之间的对齐方式以及生成的 CLIP 图像,以将其用于全局图像调节。
Zero123++ 框架建议利用线性引导机制的可训练变体,以最小的成本将全局图像调节纳入框架中。 微调 所需,结果如下图所示。可以看出,在没有全局图像调节的情况下,该框架对于与输入图像对应的可见区域生成的内容质量令人满意。然而,该框架对于不可见区域生成的图像质量显著下降,这主要是因为该模型无法推断对象的全局语义。

模型架构
Zero123++ 框架以稳定扩散 2v 模型为基础,使用本文中提到的不同方法和技术进行训练。 Zero123++ 框架在使用随机 HDRI 光照渲染的 Objaverse 数据集上进行了预训练。 该框架还采用了稳定扩散图像变化框架中使用的分阶段训练计划方法,试图进一步减少所需的微调量,并尽可能保留之前的稳定扩散。
Zero123++框架的工作或架构可以进一步分为连续的步骤或阶段。 第一阶段见证了框架对交叉注意力层的 KV 矩阵以及以 AdamW 作为优化器的稳定扩散的自注意力层进行微调,1000 个预热步骤以及 7×10 的余弦学习率计划最大化-5。 在第二阶段,该框架采用高度保守的恒定学习率和 2000 个预热集,并采用 Min-SNR 方法来最大化训练过程中的效率。
Zero123++:结果和性能比较
质量表现
为了根据生成的质量评估 Zero123++ 框架的性能,我们将其与 SyncDreamer 和 Zero-1-to-3-XL 这两个最先进的内容生成框架进行了比较。 将框架与不同范围的四个输入图像进行比较。 第一张图像是一只电动玩具猫,直接取自 Objaverse 数据集,它在物体的后端具有很大的不确定性。 第二张是灭火器的图像,第三张是由 SDXL 模型生成的一只狗坐在火箭上的图像。 最终图像是动漫插图。 框架所需的高程步长是通过使用One-2-3-4-5框架的高程估计方法来实现的,并且使用SAM框架来实现背景去除。 可以看出,Zero123++ 框架始终生成高质量的多视图图像,并且能够同样出色地推广到域外 2D 插图和 AI 生成的图像。


定量分析
为了将 Zero123++ 框架与最先进的 Zero-1-to-3 和 Zero-1to-3 XL 框架进行定量比较,开发人员在验证分割数据(一个子集)上评估了这些模型的学习感知图像块相似性 (LPIPS) 分数Objaverse 数据集的。 为了评估模型在多视图图像生成方面的性能,开发人员分别平铺地面实况参考图像和 6 个生成的图像,然后计算学习感知图像块相似度 (LPIPS) 分数。 结果如下所示,可以清楚地看到,Zero123++ 框架在验证分割集上实现了最佳性能。

文本到多视图评估
为了评估Zero123++框架在文本到多视图内容生成方面的能力,开发人员首先使用带有文本提示的SDXL框架生成图像,然后使用Zero123++框架来生成图像。 结果如下图所示,可以看出,与不能保证一致的多视图生成的零一到三框架相比,Zero1++框架返回了一致、真实且高度详细的多视图。通过执行查看图像 文本到图像到多视图 方法或管道。

Zero123++深度控制网络
除了基本 Zero123++ 框架之外,开发人员还发布了 Depth ControlNet Zero123++,这是使用 ControlNet 架构构建的原始框架的深度控制版本。 归一化的线性图像根据后续 RGB 图像进行渲染,并且 ControlNet 框架经过训练以使用深度感知来控制 Zero123++ 框架的几何形状。


结语
在本文中,我们讨论了 Zero123++,这是一种图像条件扩散生成 AI 模型,旨在使用单视图输入生成 3D 一致的多视图图像。 为了最大限度地发挥先前预训练生成模型的优势,Zero123++ 框架实施了大量的训练和调节方案,以最大程度地减少从现成的扩散图像模型进行微调所需的工作量。 我们还讨论了 Zero123++ 框架实现的不同方法和增强功能,帮助其实现与当前最先进的框架相当甚至超过的结果。
然而,尽管 Zero123++ 框架效率很高,并且能够一致地生成高质量的多视图图像,但它仍然有一些改进的空间,潜在的研究领域是
- 两级精炼机模型 这可能会解决 Zero123++ 无法满足全球一致性要求的问题。
- 额外的放大 进一步增强 Zero123++ 生成更高质量图像的能力。
