
人工智能
使用 Google 的 Imagic 和 Runway 的“擦除和替换”进行人工智能辅助对象编辑

本周,两种新的、但对比鲜明的人工智能驱动的图形算法为最终用户提供了新颖的方法,可以对照片中的对象进行高度精细且有效的更改。
第一个是 意象,来自谷歌研究院与以色列理工学院和魏茨曼科学研究所联合开展的研究。 Imagic 通过扩散模型的微调提供文本调节的细粒度对象编辑。

改变你喜欢的部分,留下其余的——Imagic 承诺只对你想要改变的部分进行精细编辑。 资料来源:https://arxiv.org/pdf/2210.09276.pdf
任何曾经尝试在稳定扩散重新渲染中仅更改一个元素的人都会非常清楚,对于每一次成功的编辑,系统都会按原样更改您喜欢的五件事。 这是目前许多最有才华的 SD 爱好者不断在稳定扩散和 Photoshop 之间切换的缺点,以修复这种“附带损害”。 仅从这个角度来看,Imagic 的成就似乎是引人注目的。
截至撰写本文时,Imagic 甚至还没有宣传视频,并且考虑到 Google 的 谨慎的态度 为了发布不受约束的图像合成工具,我们不确定我们将在多大程度上(如果有的话)有机会测试该系统。
第二个产品是 Runway ML,更容易使用 擦除和替换 设施,一个 新功能 在其基于机器学习的视觉效果实用程序的独家在线套件的“AI Magic Tools”部分。
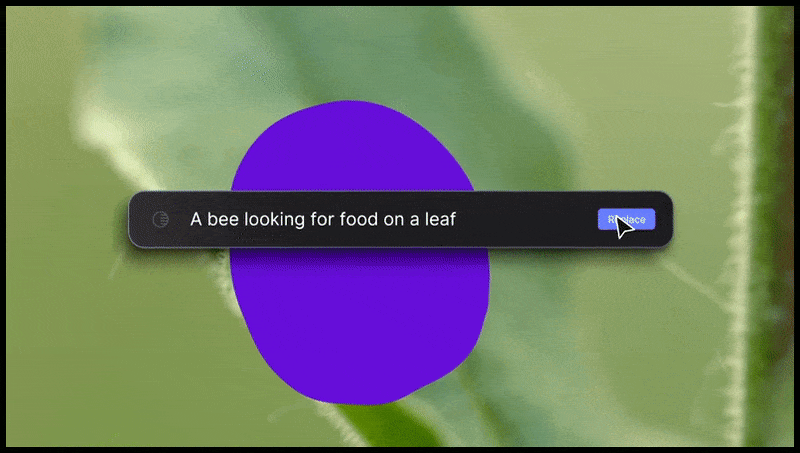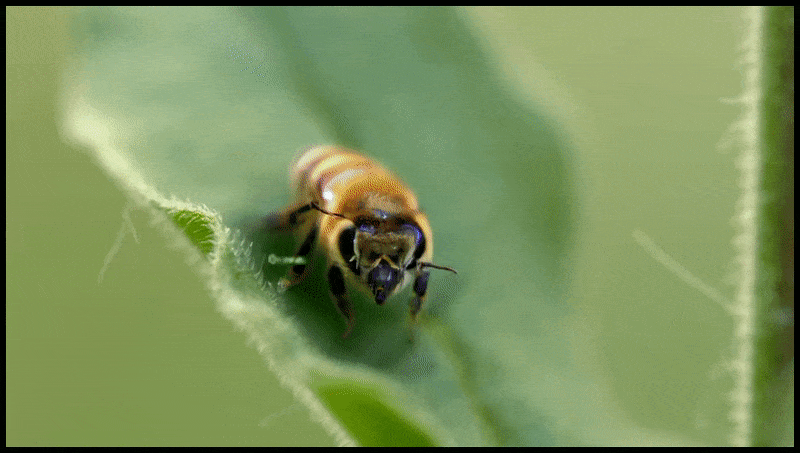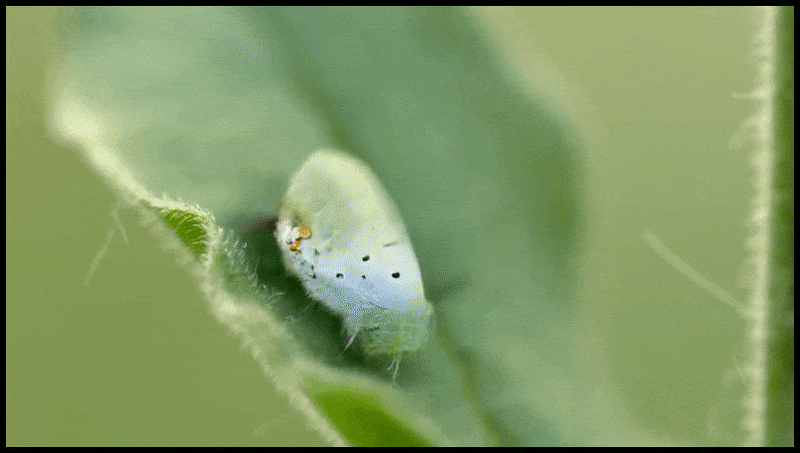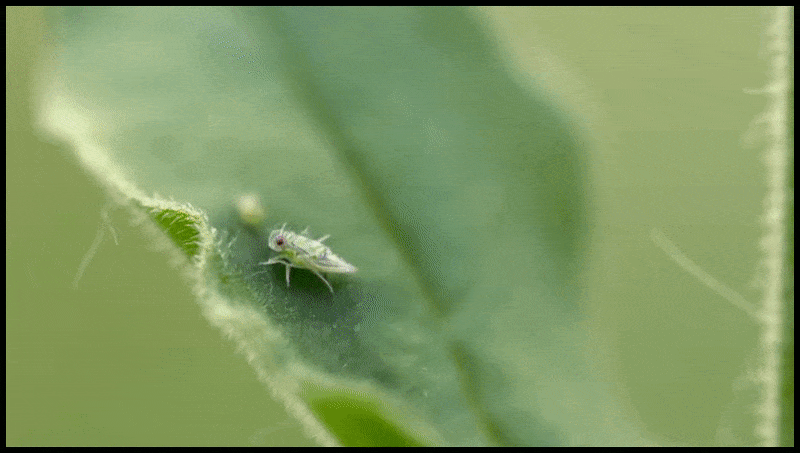
Runway ML 的擦除和替换功能已在文本转视频编辑系统的预览中看到。 资料来源:https://www.youtube.com/watch?v=41Qb58ZPO60
我们先来看看Runway的郊游吧。
擦除和替换
与 Imagic 一样,擦除和替换专门处理静态图像,尽管 Runway 有 预览 尚未发布的文本到视频编辑解决方案中的相同功能:

尽管任何人都可以在图像上测试新的“擦除和替换”功能,但视频版本尚未公开。 来源:https://twitter.com/runwayml/status/1568220303808991232
尽管 Runway ML 尚未公布“擦除和替换”背后的技术细节,但用令人信服的罗纳德·里根半身像取代室内植物的速度表明,稳定扩散等扩散模型(或者不太可能的情况是,授权的 DALL-E 2) 是在擦除和替换中重新发明您选择的对象的引擎。

用吉普半身像替换室内植物虽然没有这么快,但也相当快了。 来源:https://app.runwayml.com/
该系统有一些 DALL-E 2 类型限制 - 标记擦除和替换过滤器的图像或文本将触发有关在进一步违规的情况下可能暂停帐户的警告 - 实际上是 OpenAI 正在进行的样板克隆 政策 对于 DALL-E 2 。
许多结果缺乏稳定扩散的典型粗糙边缘。 Runway ML 是投资者和 研究伙伴 在 SD 中,他们可能已经训练了一个专有模型,该模型优于我们其他人目前正在努力解决的开源 1.4 检查点权重(正如许多其他开发团队,业余爱好者和专业人士一样,目前正在训练或微调稳定扩散模型)。
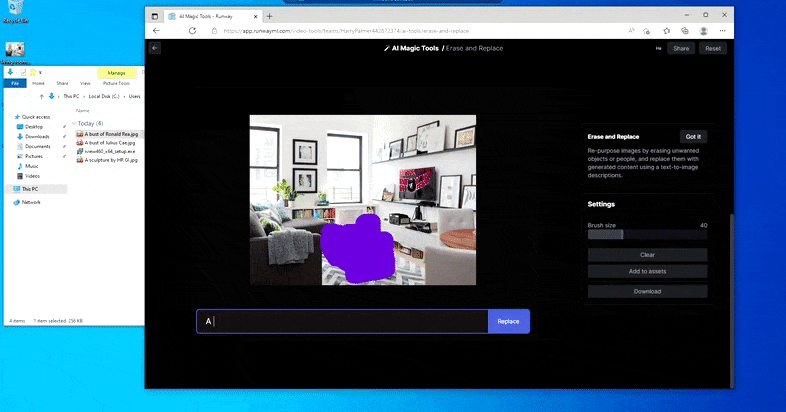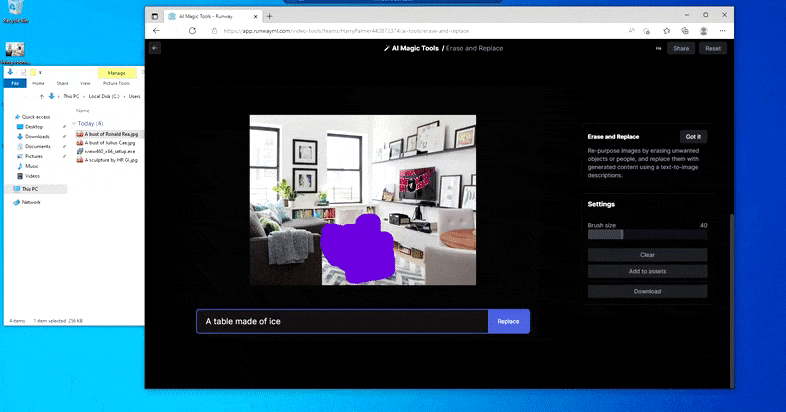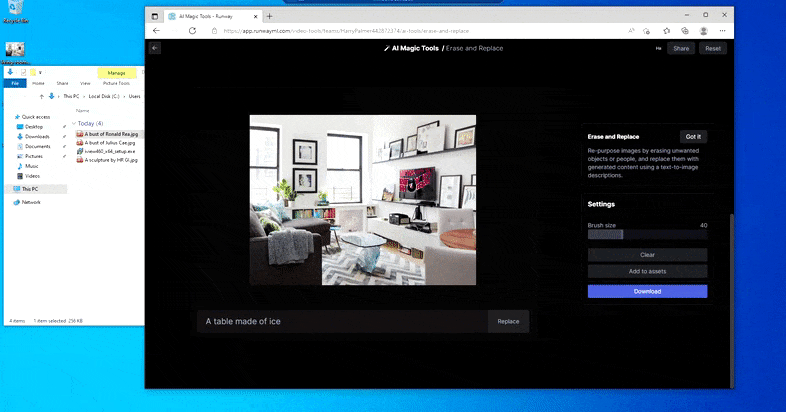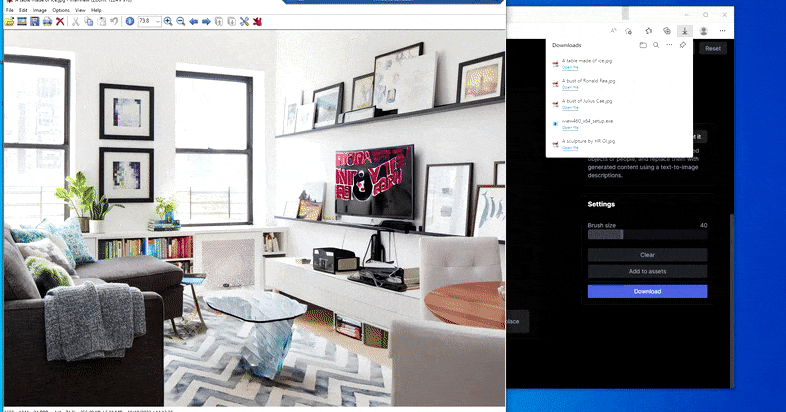
在 Runway ML 的“擦除和替换”中用家用桌子替换“冰制桌子”。
与 Imagic 一样(见下文),擦除和替换是“面向对象的”,可以说 - 你不能只擦除图片的“空”部分,然后用文本提示的结果来修复它; 在这种情况下,系统将简单地沿着面罩的视线追踪最近的明显物体(例如墙壁或电视),并在那里应用变换。
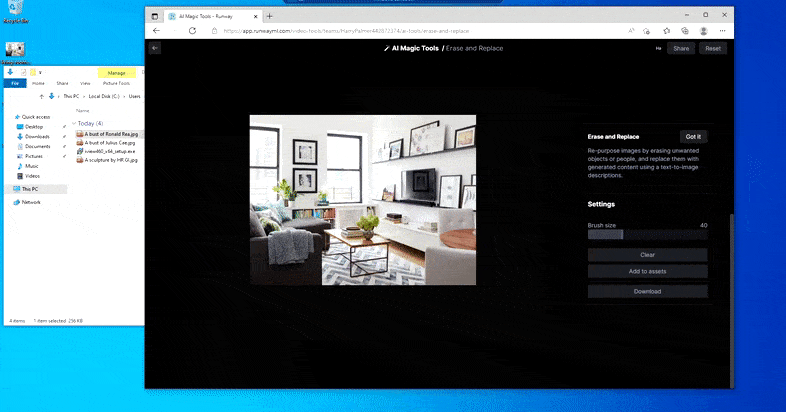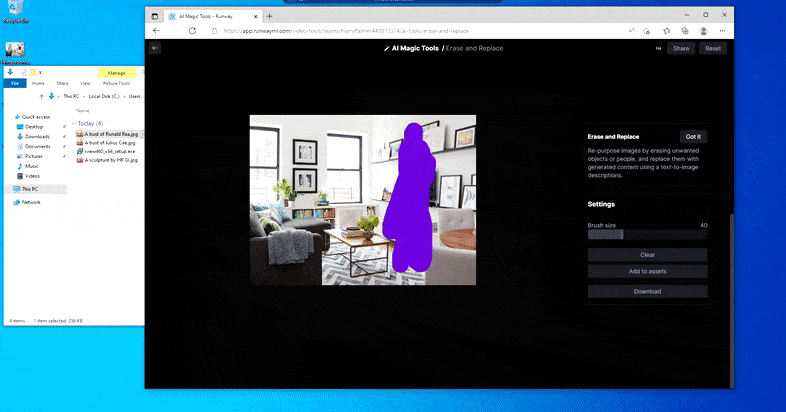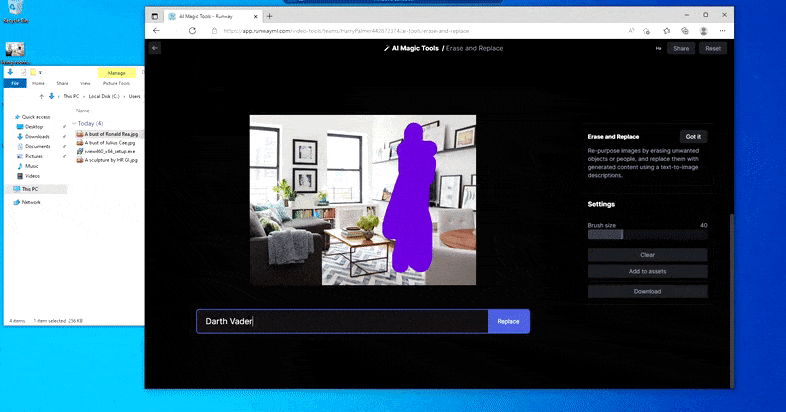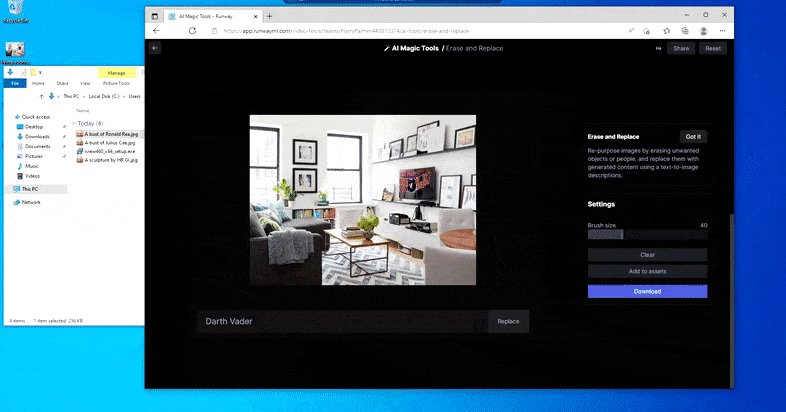
顾名思义,您无法在“擦除和替换”中将对象插入到空白空间中。 在这里,召唤最著名的西斯领主的努力导致电视上出现了一幅与维达相关的奇怪壁画,大致就是绘制“替换”区域的地方。
很难判断擦除和替换是否在使用受版权保护的图像方面回避(在 DALL-E 2 中,尽管取得了不同的成功,但在很大程度上仍然受到阻碍),或者后端渲染引擎中使用的模型是否有效只是没有针对此类事情进行优化。

略显 NSFW 的“妮可基德曼壁画”表明,手头的(大概)基于扩散的模型缺乏 DALL-E 2 以前对渲染真实面孔或色情内容的系统性拒绝,而尝试证明受版权保护的作品的结果范围从模棱两可到(“异形”)到荒谬的(“铁王座”)。 右下角插图,源图片。
了解擦除和替换使用什么方法来隔离它能够替换的对象将会很有趣。 大概该图像正在通过某种推导来运行 CLIP,通过对象识别和随后的语义分割来区分离散项目。 这些操作在稳定扩散的普通或花园安装中都无法正常工作。
但没有什么是完美的——有时系统似乎会删除而不是替换,即使(正如我们在上图中看到的)底层渲染机制肯定知道文本提示的含义。 在这种情况下,事实证明不可能将咖啡桌变成异形——相反,桌子就会消失。
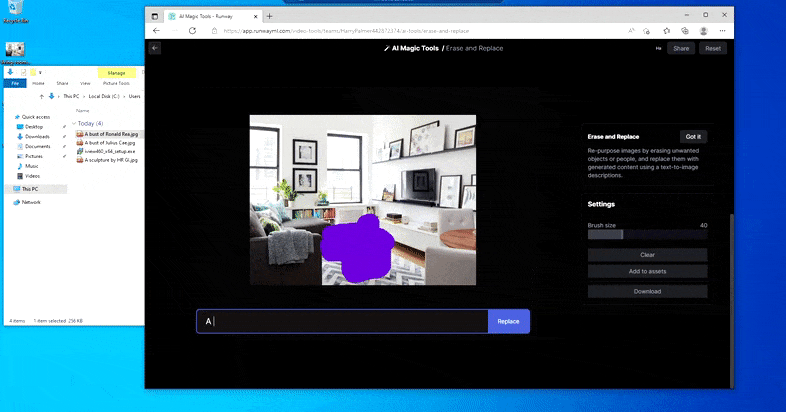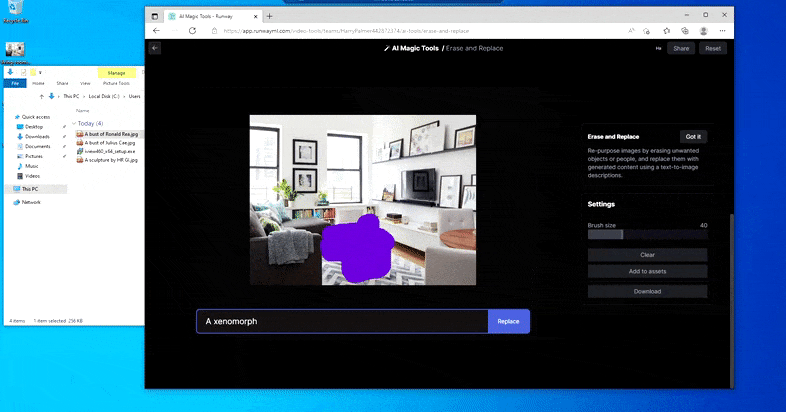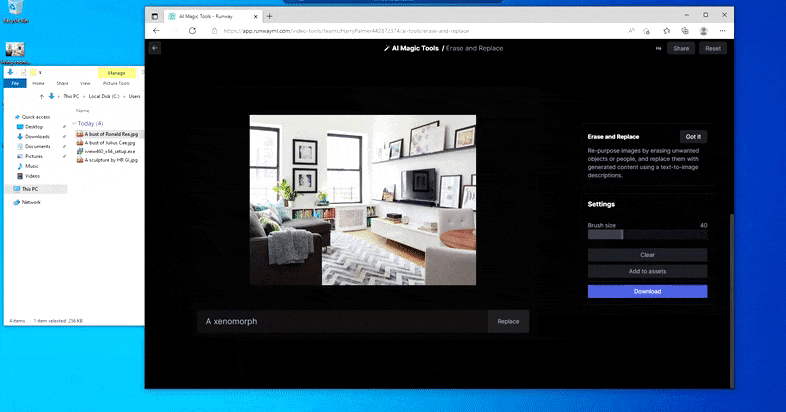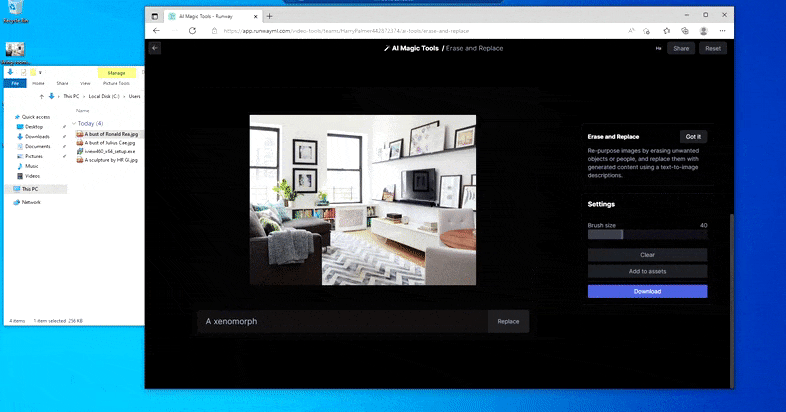
更可怕的“沃尔多在哪里”的迭代,因为擦除和替换未能产生外星人。
擦除和替换似乎是一个有效的对象替换系统,具有出色的修复功能。但是,它无法编辑现有的感知对象,而只能替换它们。在不影响环境材料的情况下实际改变现有图像内容可以说是一项更加艰巨的任务,这与计算机视觉研究部门长期以来的努力密切相关 解开 在流行框架的各种潜在空间中。
意象
这是 Imagic 解决的一项任务。 这 新文 提供了大量编辑示例,可以成功修改照片的各个方面,同时保持图像的其余部分不变。

在 Imagic 中,修改后的图像不会受到 Deepfake puppetry 特征的拉伸、扭曲和“遮挡猜测”特征的影响,它利用从单个图像导出的有限先验。
该系统采用三阶段过程——文本嵌入优化; 模型微调; 最后,生成修改后的图像。

Imagic 对目标文本提示进行编码以检索初始文本嵌入,然后优化结果以获得输入图像。 之后,生成模型根据源图像进行微调,添加一系列参数,然后进行所请求的插值。
不出所料,该框架基于 Google 的 图像 文本到视频架构,尽管研究人员表示该系统的原理广泛适用于潜在扩散模型。
Imagen 使用三层架构,而不是该公司最近使用的七层阵列 文本到视频的迭代 该软件的。 这三个不同的模块包括一个以 64x64px 分辨率运行的生成扩散模型; 一个超分辨率模型,可将此输出放大到 256x256px; 以及一个额外的超分辨率模型,可将输出分辨率一直提高到 1024×1024。
Imagic 在此过程的最早阶段进行干预,在 Adam 优化器上以 64 的静态学习率优化 0.0001px 阶段所请求的文本嵌入。

解缠结大师级课程:那些尝试更改扩散、GAN 或 NeRF 模型中渲染对象的颜色等简单内容的最终用户将会知道 Imagic 能够在不“撕裂”的情况下执行此类转换有多么重要' 图像其余部分的一致性。
然后在 Imagen 的基本模型上进行微调,每个输入图像 1500 个步骤,以修改后的嵌入为条件。 同时,辅助 64px>256px 层在条件图像上并行优化。 研究人员指出,对最终 256px>1024px 图层的类似优化对最终结果“影响很小甚至没有影响”,因此尚未实施。
该论文指出,双胞胎上每个图像的优化过程大约需要八分钟 TPUV4 筹码。 最终渲染发生在核心 Imagen 下 DDIM抽样方案.
与 Google 的类似微调流程相同 梦想展位,生成的嵌入还可以用于增强风格化以及照片级真实感编辑,其中包含从支持 Imagen 的更广泛的底层数据库中提取的信息(因为,如下面第一列所示,源图像没有任何必要的内容)影响这些转变)。

可以通过 Imagic 引发灵活的照片级移动和编辑,而在此过程中获得的派生和解开的代码可以轻松用于风格化输出。
研究人员将 Imagic 与之前的作品进行了比较 SD编辑,从 2021 年开始采用基于 GAN 的方法,由斯坦福大学和卡内基梅隆大学合作; 和 文字直播是魏茨曼科学研究所与 NVIDIA 于 2022 年 XNUMX 月开始合作的成果。

Imagic、SDEdit 和 Text2Live 之间的视觉比较。
很明显,前一种方法正在挣扎,但在最后一行,涉及插入巨大的姿势变化,与 Imagic 的显着成功相比,现任者完全无法重新调整源材料。
Imagic 的资源需求和每张图像的训练时间虽然短于此类追求的标准,但使其不太可能包含在个人计算机上的本地图像编辑应用程序中 - 并且尚不清楚微调过程可以达到何种程度缩小到消费者水平。
就目前情况而言,Imagic 是一个令人印象深刻的产品,更适合 API——谷歌研究中心对促进深度造假的批评持谨慎态度,无论如何可能是最适应的。
首次发布于 18 年 2022 月 XNUMX 日。















