AI 101
Overfitting là gì?
Overfitting là gì?
Khi bạn huấn luyện một mạng nơ-ron, bạn phải tránh hiện tượng overfitting. Overfitting là một vấn đề trong học máy và thống kê, xảy ra khi một mô hình học các mẫu của tập dữ liệu huấn luyện quá tốt, giải thích hoàn hảo tập dữ liệu huấn luyện nhưng lại không thể khái quát hóa khả năng dự đoán của nó cho các tập dữ liệu khác. Nói cách khác, trong trường hợp một mô hình bị overfitting, nó thường thể hiện độ chính xác cực cao trên tập dữ liệu huấn luyện nhưng độ chính xác thấp trên dữ liệu được thu thập và chạy qua mô hình trong tương lai. Đó là định nghĩa nhanh về overfitting, nhưng hãy cùng xem xét khái niệm này chi tiết hơn. Hãy xem overfitting xảy ra như thế nào và có thể tránh nó ra sao.
Hiểu về “Fit” và Underfitting
Sẽ rất hữu ích khi xem xét khái niệm underfitting và “fit” một cách tổng quát khi thảo luận về overfitting. Khi chúng ta huấn luyện một mô hình, chúng ta đang cố gắng phát triển một khuôn khổ có khả năng dự đoán bản chất, hoặc lớp, của các mục trong một tập dữ liệu, dựa trên các đặc trưng mô tả những mục đó. Một mô hình nên có khả năng giải thích một mẫu trong tập dữ liệu và dự đoán lớp của các điểm dữ liệu tương lai dựa trên mẫu này. Mô hình giải thích mối quan hệ giữa các đặc trưng của tập huấn luyện càng tốt thì mô hình của chúng ta càng “fit”.

Đường màu xanh dương biểu thị dự đoán của một mô hình đang underfitting, trong khi đường màu xanh lá cây biểu thị một mô hình fit tốt hơn. Ảnh: Pep Roca qua Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Một mô hình giải thích kém mối quan hệ giữa các đặc trưng của dữ liệu huấn luyện và do đó không phân loại chính xác các ví dụ dữ liệu tương lai được gọi là underfitting dữ liệu huấn luyện. Nếu bạn vẽ đồ thị mối quan hệ dự đoán của một mô hình underfitting so với giao điểm thực tế của các đặc trưng và nhãn, các dự đoán sẽ lệch khỏi mục tiêu. Nếu chúng ta có một đồ thị với các giá trị thực tế của một tập huấn luyện được gắn nhãn, một mô hình underfitting nghiêm trọng sẽ bỏ lỡ hầu hết các điểm dữ liệu một cách đáng kể. Một mô hình fit tốt hơn có thể cắt một đường đi qua trung tâm của các điểm dữ liệu, với các điểm dữ liệu riêng lẻ chỉ lệch khỏi các giá trị dự đoán một chút. Underfitting thường xảy ra khi không có đủ dữ liệu để tạo ra một mô hình chính xác, hoặc khi cố gắng thiết kế một mô hình tuyến tính với dữ liệu phi tuyến. Thêm dữ liệu huấn luyện hoặc thêm đặc trưng thường sẽ giúp giảm underfitting. Vậy tại sao chúng ta không chỉ tạo ra một mô hình giải thích mọi điểm trong dữ liệu huấn luyện một cách hoàn hảo? Chắc chắn độ chính xác hoàn hảo là mong muốn? Việc tạo ra một mô hình đã học các mẫu của dữ liệu huấn luyện quá tốt chính là nguyên nhân gây ra overfitting. Tập dữ liệu huấn luyện và các tập dữ liệu khác, tương lai mà bạn chạy qua mô hình sẽ không hoàn toàn giống nhau. Chúng có thể sẽ rất giống nhau về nhiều mặt, nhưng chúng cũng sẽ khác nhau theo những cách then chốt. Do đó, việc thiết kế một mô hình giải thích tập dữ liệu huấn luyện một cách hoàn hảo có nghĩa là bạn sẽ có một lý thuyết về mối quan hệ giữa các đặc trưng mà không khái quát hóa tốt cho các tập dữ liệu khác.
Hiểu về Overfitting
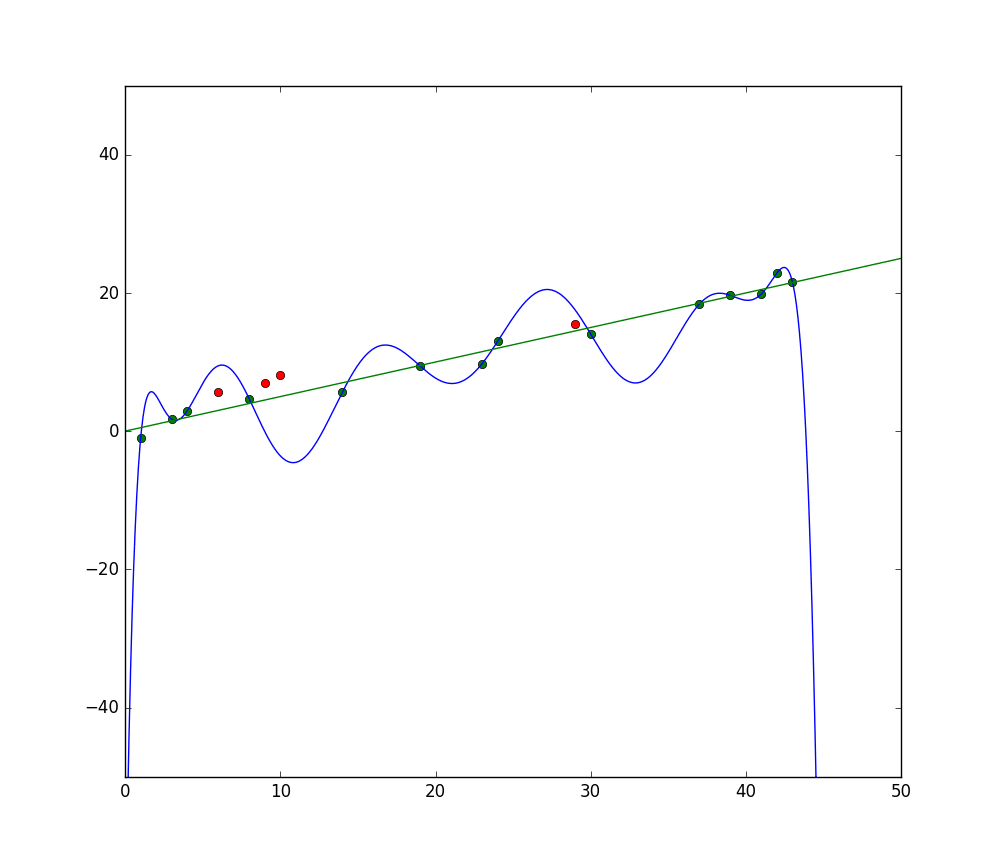
Overfitting xảy ra khi một mô hình học các chi tiết bên trong tập dữ liệu huấn luyện quá tốt, khiến mô hình hoạt động kém khi đưa ra dự đoán trên dữ liệu bên ngoài. Điều này có thể xảy ra khi mô hình không chỉ học các đặc trưng của tập dữ liệu, mà còn học cả các biến động ngẫu nhiên hoặc nhiễu bên trong tập dữ liệu, đặt tầm quan trọng vào những sự xuất hiện ngẫu nhiên/không quan trọng này. Overfitting có nhiều khả năng xảy ra hơn khi sử dụng các mô hình phi tuyến, vì chúng linh hoạt hơn khi học các đặc trưng dữ liệu. Các thuật toán học máy phi tham số thường có nhiều tham số và kỹ thuật khác nhau có thể được áp dụng để hạn chế độ nhạy cảm của mô hình với dữ liệu và từ đó giảm overfitting. Ví dụ, các mô hình cây quyết định rất nhạy cảm với overfitting, nhưng một kỹ thuật gọi là pruning có thể được sử dụng để loại bỏ ngẫu nhiên một số chi tiết mà mô hình đã học. Nếu bạn vẽ đồ thị các dự đoán của mô hình trên các trục X và Y, bạn sẽ có một đường dự đoán ngoằn ngoèo qua lại, phản ánh thực tế là mô hình đã cố gắng quá mức để khớp tất cả các điểm trong tập dữ liệu vào lời giải thích của nó.
Kiểm soát Overfitting
Khi chúng ta huấn luyện một mô hình, lý tưởng nhất là chúng ta muốn mô hình không mắc lỗi nào. Khi hiệu suất của mô hình hội tụ về việc đưa ra dự đoán chính xác trên tất cả các điểm dữ liệu trong tập dữ liệu huấn luyện, thì độ fit đang trở nên tốt hơn. Một mô hình có độ fit tốt có thể giải thích gần như toàn bộ tập dữ liệu huấn luyện mà không bị overfitting. Khi một mô hình được huấn luyện, hiệu suất của nó được cải thiện theo thời gian. Tỷ lệ lỗi của mô hình sẽ giảm khi thời gian huấn luyện trôi qua, nhưng nó chỉ giảm đến một điểm nhất định. Điểm mà hiệu suất của mô hình trên tập kiểm tra bắt đầu tăng trở lại thường là điểm mà overfitting đang xảy ra. Để có được độ fit tốt nhất cho một mô hình, chúng ta muốn dừng huấn luyện mô hình tại điểm có tổn thất thấp nhất trên tập huấn luyện, trước khi lỗi bắt đầu tăng trở lại. Điểm dừng tối ưu có thể được xác định bằng cách vẽ đồ thị hiệu suất của mô hình trong suốt thời gian huấn luyện và dừng huấn luyện khi tổn thất ở mức thấp nhất. Tuy nhiên, một rủi ro với phương pháp kiểm soát overfitting này là việc chỉ định điểm kết thúc cho quá trình huấn luyện dựa trên hiệu suất kiểm tra có nghĩa là dữ liệu kiểm tra phần nào đó được đưa vào quy trình huấn luyện, và nó mất đi trạng thái là dữ liệu hoàn toàn “chưa chạm tới”. Có một vài cách khác nhau để chống lại overfitting. Một phương pháp giảm overfitting là sử dụng chiến thuật lấy mẫu lại, hoạt động bằng cách ước tính độ chính xác của mô hình. Bạn cũng có thể sử dụng một tập dữ liệu validation bổ sung cùng với tập kiểm tra và vẽ đồ thị độ chính xác huấn luyện so với tập validation thay vì tập dữ liệu kiểm tra. Điều này giữ cho tập dữ liệu kiểm tra của bạn không bị nhìn thấy. Một phương pháp lấy mẫu lại phổ biến là xác thực chéo K-folds. Kỹ thuật này cho phép bạn chia dữ liệu của mình thành các tập con mà mô hình được huấn luyện trên đó, sau đó hiệu suất của mô hình trên các tập con được phân tích để ước tính mô hình sẽ hoạt động như thế nào trên dữ liệu bên ngoài. Sử dụng xác thực chéo là một trong những cách tốt nhất để ước tính độ chính xác của mô hình trên dữ liệu chưa nhìn thấy, và khi kết hợp với một tập dữ liệu validation, overfitting thường có thể được giữ ở mức tối thiểu.








