
AI 101
Cây quyết định là gì?
Cây quyết định là gì?
A cây quyết định là một thuật toán học máy hữu ích được sử dụng cho cả nhiệm vụ hồi quy và phân loại. Cái tên “cây quyết định” xuất phát từ thực tế là thuật toán tiếp tục chia tập dữ liệu thành các phần ngày càng nhỏ hơn cho đến khi dữ liệu được chia thành các trường hợp riêng lẻ, sau đó được phân loại. Nếu bạn hình dung kết quả của thuật toán, cách phân chia các danh mục sẽ giống như một cái cây và nhiều lá.
Đó là định nghĩa nhanh về cây quyết định, nhưng chúng ta hãy tìm hiểu sâu hơn về cách thức hoạt động của cây quyết định. Hiểu rõ hơn về cách thức hoạt động của cây quyết định, cũng như các trường hợp sử dụng của chúng, sẽ giúp bạn biết khi nào nên sử dụng chúng trong các dự án máy học của mình.
Định dạng của một cây quyết định
Cây quyết định là rất giống như một sơ đồ. Để sử dụng lưu đồ, bạn bắt đầu tại điểm bắt đầu hoặc gốc của biểu đồ và sau đó dựa trên cách bạn trả lời các tiêu chí lọc của nút bắt đầu đó, bạn di chuyển đến một trong các nút có thể tiếp theo. Quá trình này được lặp lại cho đến khi đạt được kết thúc.
Cây quyết định về cơ bản hoạt động theo cùng một cách, với mọi nút bên trong cây là một số loại tiêu chí kiểm tra/lọc. Các nút ở bên ngoài, các điểm cuối của cây, là các nhãn cho điểm dữ liệu được đề cập và chúng được gọi là "các lá". Các nhánh dẫn từ các nút bên trong đến nút tiếp theo là các tính năng hoặc liên kết của các tính năng. Các quy tắc được sử dụng để phân loại các điểm dữ liệu là các đường dẫn chạy từ gốc đến lá.
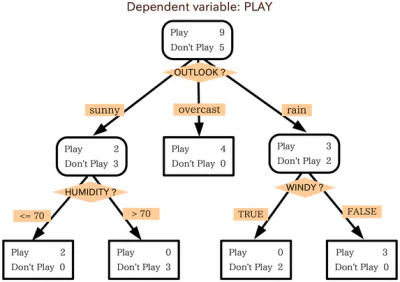
Thuật toán cho cây quyết định
Cây quyết định hoạt động theo cách tiếp cận thuật toán chia tập dữ liệu thành các điểm dữ liệu riêng lẻ dựa trên các tiêu chí khác nhau. Việc phân tách này được thực hiện với các biến khác nhau hoặc các tính năng khác nhau của tập dữ liệu. Ví dụ: nếu mục tiêu là xác định xem một con chó hoặc con mèo có được mô tả bằng các tính năng đầu vào hay không, thì các biến mà dữ liệu được phân chia có thể là những thứ như “móng vuốt” và “tiếng sủa”.
Vì vậy, thuật toán nào được sử dụng để thực sự chia dữ liệu thành các nhánh và lá? Có nhiều phương pháp khác nhau có thể được sử dụng để tách cây, nhưng phương pháp tách phổ biến nhất có lẽ là một kỹ thuật được gọi là “phân chia nhị phân đệ quy”. Khi thực hiện phương pháp phân tách này, quy trình bắt đầu từ gốc và số lượng tính năng trong tập dữ liệu biểu thị số lượng phân tách có thể có. Một hàm được sử dụng để xác định mức độ chính xác của mỗi lần phân tách có thể có và việc phân chia được thực hiện bằng cách sử dụng tiêu chí hy sinh độ chính xác thấp nhất. Quá trình này được thực hiện theo cách đệ quy và các nhóm nhỏ được hình thành bằng cách sử dụng cùng một chiến lược chung.
Để xác định chi phí phân chia, một hàm chi phí được sử dụng. Một hàm chi phí khác được sử dụng cho các nhiệm vụ hồi quy và nhiệm vụ phân loại. Mục tiêu của cả hai hàm chi phí là xác định nhánh nào có giá trị phản hồi giống nhau nhất hoặc nhánh đồng nhất nhất. Hãy xem xét rằng bạn muốn dữ liệu thử nghiệm của một lớp nhất định đi theo các đường dẫn nhất định và điều này có ý nghĩa trực quan.
Về hàm chi phí hồi quy cho phép chia nhị phân đệ quy, thuật toán được sử dụng để tính toán chi phí như sau:
tổng(y – dự đoán)^2
Dự đoán cho một nhóm điểm dữ liệu cụ thể là giá trị trung bình của các phản hồi của dữ liệu huấn luyện cho nhóm đó. Tất cả các điểm dữ liệu được chạy thông qua hàm chi phí để xác định chi phí cho tất cả các phần tách có thể và phần tách có chi phí thấp nhất được chọn.
Về hàm chi phí để phân loại, hàm như sau:
G = tổng(pk * (1 – pk))
Đây là điểm Gini và nó là phép đo hiệu quả của việc phân chia, dựa trên số lượng phiên bản của các lớp khác nhau trong các nhóm do sự phân tách. Nói cách khác, nó định lượng mức độ hỗn hợp của các nhóm sau khi chia tách. Sự phân chia tối ưu là khi tất cả các nhóm do sự phân chia chỉ bao gồm các đầu vào từ một lớp. Nếu một sự phân chia tối ưu đã được tạo thì giá trị “pk” sẽ là 0 hoặc 1 và G sẽ bằng 50. Bạn có thể đoán rằng sự phân chia trong trường hợp xấu nhất là sự phân chia trong đó có sự biểu diễn 50-0.5 của các lớp trong sự phân tách, trong trường hợp phân loại nhị phân. Trong trường hợp này, giá trị “pk” sẽ là 0.5 và G cũng sẽ là XNUMX.
Quá trình chia tách kết thúc khi tất cả các điểm dữ liệu đã được chuyển thành lá và được phân loại. Tuy nhiên, bạn có thể muốn ngăn chặn sự phát triển của cây sớm. Các cây phức tạp lớn có xu hướng bị thừa, nhưng có thể sử dụng một số phương pháp khác nhau để chống lại điều này. Một phương pháp giảm overfitting là chỉ định số lượng điểm dữ liệu tối thiểu sẽ được sử dụng để tạo một lá. Một phương pháp khác để kiểm soát việc trang bị quá mức là giới hạn cây ở một độ sâu tối đa nhất định, điều này kiểm soát khoảng thời gian một đường dẫn có thể kéo dài từ gốc đến lá.
Một quá trình khác liên quan đến việc tạo ra các cây quyết định đang cắt tỉa. Cắt tỉa có thể giúp tăng hiệu suất của cây quyết định bằng cách loại bỏ các nhánh chứa các tính năng có ít khả năng dự đoán/ít quan trọng đối với mô hình. Bằng cách này, độ phức tạp của cây giảm đi, nó ít có khả năng bị overfit hơn và tiện ích dự đoán của mô hình được tăng lên.
Khi tiến hành cắt tỉa, quá trình có thể bắt đầu từ ngọn cây hoặc từ dưới gốc cây. Tuy nhiên, phương pháp cắt tỉa đơn giản nhất là bắt đầu với các lá và cố gắng loại bỏ nút chứa lớp phổ biến nhất trong lá đó. Nếu độ chính xác của mô hình không giảm khi điều này được thực hiện, thì sự thay đổi sẽ được giữ nguyên. Có những kỹ thuật khác được sử dụng để thực hiện việc cắt tỉa, nhưng phương pháp được mô tả ở trên – giảm lỗi cắt tỉa – có lẽ là phương pháp phổ biến nhất để cắt tỉa cây quyết định.
Cân nhắc sử dụng cây quyết định
Cây quyết định thường hữu ích khi phân loại cần phải được thực hiện nhưng thời gian tính toán là một hạn chế lớn. Cây quyết định có thể làm rõ tính năng nào trong bộ dữ liệu đã chọn mang lại khả năng dự đoán cao nhất. Hơn nữa, không giống như nhiều thuật toán học máy trong đó các quy tắc được sử dụng để phân loại dữ liệu có thể khó diễn giải, cây quyết định có thể đưa ra các quy tắc có thể diễn giải được. Cây quyết định cũng có thể sử dụng cả biến phân loại và biến liên tục, nghĩa là cần ít tiền xử lý hơn so với các thuật toán chỉ có thể xử lý một trong các loại biến này.
Cây quyết định có xu hướng hoạt động không tốt khi được sử dụng để xác định giá trị của các thuộc tính liên tục. Một hạn chế khác của cây quyết định là khi thực hiện phân loại, nếu có ít ví dụ huấn luyện nhưng nhiều lớp thì cây quyết định có xu hướng thiếu chính xác.










