AI 101
RNNs và LSTMs là gì trong Deep Learning?
Nhiều tiến bộ ấn tượng nhất trong xử lý ngôn ngữ tự nhiên và AI chatbots được thúc đẩy bởi Mạng nơ-ron hồi quy (RNNs) và mạng nhớ ngắn hạn dài (LSTM). RNNs và LSTMs là kiến trúc mạng nơ-ron đặc biệt có thể xử lý dữ liệu tuần tự, dữ liệu mà thứ tự thời gian quan trọng. LSTMs cơ bản là phiên bản cải tiến của RNNs, có khả năng giải thích các chuỗi dữ liệu dài hơn. Hãy cùng xem xét cách RNNs và LSTMS được cấu trúc và cách chúng cho phép tạo ra các hệ thống xử lý ngôn ngữ tự nhiên tinh vi.
Feed-Forward Neural Networks là gì?
Vậy trước khi chúng ta thảo luận về cách Long Short-Term Memory (LSTM) và Mạng nơ-ron tích chập (CNN) hoạt động, chúng ta nên thảo luận về định dạng của một mạng nơ-ron nói chung.
Một mạng nơ-ron được thiết kế để kiểm tra dữ liệu và học các mẫu liên quan, để các mẫu này có thể được áp dụng cho các dữ liệu khác và dữ liệu mới có thể được phân loại. Mạng nơ-ron được chia thành ba phần: lớp đầu vào, lớp ẩn (hoặc nhiều lớp ẩn) và lớp đầu ra.
Lớp đầu vào là gì nhận dữ liệu vào mạng nơ-ron, trong khi các lớp ẩn là những gì học các mẫu trong dữ liệu. Các lớp ẩn trong tập dữ liệu được kết nối với lớp đầu vào và đầu ra bởi “trọng số” và “偏见” mà chỉ là giả định về cách các điểm dữ liệu liên quan đến nhau. Những trọng số này được điều chỉnh trong quá trình đào tạo. Khi mạng được đào tạo, các dự đoán của mô hình về dữ liệu đào tạo (các giá trị đầu ra) được so sánh với các nhãn đào tạo thực tế. Trong quá trình đào tạo, mạng nên (hy vọng) trở nên chính xác hơn trong việc dự đoán mối quan hệ giữa các điểm dữ liệu, để nó có thể phân loại chính xác các điểm dữ liệu mới. Mạng nơ-ron sâu là mạng có nhiều lớp ở giữa / nhiều lớp ẩn hơn. Số lớp ẩn và số nơ-ron / nút mô hình có, mô hình càng tốt có thể nhận ra các mẫu trong dữ liệu.
Mạng nơ-ron hồi tiếp thường, như những gì tôi đã mô tả ở trên thường được gọi là “mạng nơ-ron dày”. Những mạng nơ-ron dày này được kết hợp với các kiến trúc mạng khác chuyên về giải thích các loại dữ liệu khác nhau.
RNNs (Mạng nơ-ron hồi quy) là gì?

Mạng nơ-ron hồi quy lấy nguyên tắc chung của mạng nơ-ron hồi tiếp và cho phép chúng xử lý dữ liệu tuần tự bằng cách cho mô hình một bộ nhớ nội bộ. Phần “Hồi quy” của tên RNN đến từ thực tế rằng đầu vào và đầu ra được lặp lại. Một khi đầu ra của mạng được tạo ra, đầu ra được sao chép và trả lại mạng như đầu vào. Khi đưa ra quyết định, không chỉ đầu vào và đầu ra hiện tại được phân tích, mà đầu vào trước cũng được xem xét. Để nói cách khác, nếu đầu vào ban đầu cho mạng là X và đầu ra là H, cả H và X1 (đầu vào tiếp theo trong chuỗi dữ liệu) được đưa vào mạng cho vòng học tiếp theo. Theo cách này, ngữ cảnh của dữ liệu (các đầu vào trước) được bảo tồn khi mạng được đào tạo.
Kết quả của kiến trúc này là RNNs có khả năng xử lý dữ liệu tuần tự. Tuy nhiên, RNNs gặp phải một số vấn đề. RNNs gặp phải vấn đề gradient biến mất và gradient nổ.
Độ dài của các chuỗi mà một RNN có thể giải thích khá hạn chế, đặc biệt là so với LSTMs.
LSTMs (Mạng nhớ ngắn hạn dài) là gì?
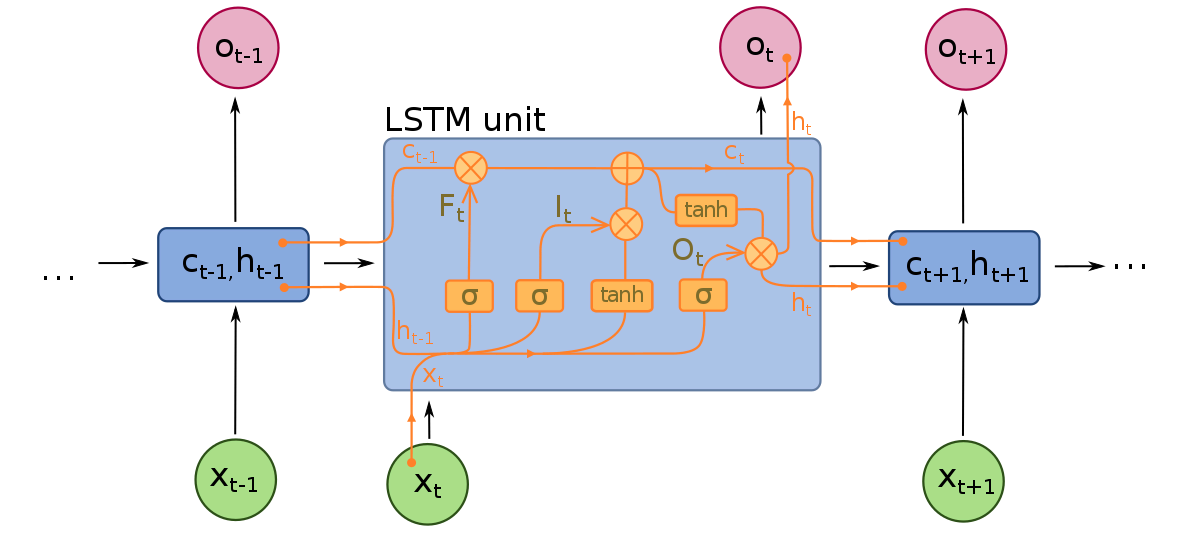
Mạng nhớ ngắn hạn dài có thể được coi là phần mở rộng của RNNs, một lần nữa áp dụng khái niệm bảo tồn ngữ cảnh của đầu vào. Tuy nhiên, LSTMs đã được sửa đổi theo một số cách quan trọng cho phép chúng giải thích dữ liệu trong quá khứ với phương pháp vượt trội. Những thay đổi được thực hiện đối với LSTMs liên quan đến vấn đề gradient biến mất và cho phép LSTMs xem xét các chuỗi đầu vào dài hơn.

Mô hình LSTM bao gồm ba thành phần khác nhau, hoặc cổng. Có một cổng đầu vào, cổng đầu ra và cổng quên. Giống như RNNs, LSTMs lấy đầu vào từ bước thời gian trước vào tài khoản khi sửa đổi bộ nhớ và trọng số đầu vào của mô hình. Cổng đầu vào đưa ra quyết định về những giá trị nào quan trọng và nên được truyền qua mô hình. Một hàm sigmoid được sử dụng trong cổng đầu vào, giúp xác định những giá trị nào nên được truyền qua mạng hồi quy. Zero bỏ giá trị, trong khi 1 bảo tồn nó. Một hàm TanH cũng được sử dụng ở đây, giúp quyết định mức độ quan trọng của các giá trị đầu vào đối với mô hình, từ -1 đến 1.
Sau khi đầu vào hiện tại và trạng thái bộ nhớ được tính đến, cổng đầu ra quyết định những giá trị nào nên được đẩy đến bước thời gian tiếp theo. Trong cổng đầu ra, các giá trị được phân tích và được chỉ định mức độ quan trọng từ -1 đến 1. Điều này điều chỉnh dữ liệu trước khi nó được chuyển đến bước tính toán tiếp theo. Cuối cùng, công việc của cổng quên là bỏ thông tin mà mô hình coi là không cần thiết để đưa ra quyết định về bản chất của các giá trị đầu vào. Cổng quên sử dụng một hàm sigmoid trên các giá trị, đầu ra số từ 0 (bỏ qua) đến 1 (giữ lại).
Một mạng nơ-ron LSTM được tạo thành từ cả các lớp LSTM đặc biệt có thể giải thích dữ liệu từ tuần tự và các lớp kết nối dày như những gì được mô tả ở trên. Một khi dữ liệu di chuyển qua các lớp LSTM, nó tiếp tục vào các lớp kết nối dày.








