AI 101
Những gì là CNNs (Mạng nơ-ron tích chập)?
Có thể bạn đã từng thắc mắc làm thế nào Facebook hoặc Instagram có thể tự động nhận dạng khuôn mặt trong một hình ảnh, hoặc làm thế nào Google cho phép bạn tìm kiếm web cho các ảnh tương tự chỉ bằng cách tải lên một ảnh của riêng bạn. Những tính năng này là ví dụ về tầm nhìn máy tính, và chúng được cung cấp bởi mạng nơ-ron tích chập (CNNs). Nhưng chính xác thì mạng nơ-ron tích chập là gì? Hãy cùng tìm hiểu sâu về kiến trúc của một CNN và hiểu cách chúng hoạt động.
Những gì là Mạng nơ-ron?
Trước khi chúng ta bắt đầu nói về mạng nơ-ron tích chập, hãy dành một chút thời gian để định nghĩa mạng nơ-ron thông thường. Có một bài viết khác về chủ đề mạng nơ-ron có sẵn, vì vậy chúng ta sẽ không đi quá sâu vào chúng ở đây. Tuy nhiên, để định nghĩa ngắn gọn, chúng là các mô hình tính toán được lấy cảm hứng từ não bộ con người. Một mạng nơ-ron hoạt động bằng cách lấy dữ liệu và điều chỉnh dữ liệu bằng cách điều chỉnh “trọng số”, những giả định về cách các tính năng đầu vào liên quan đến nhau và lớp của đối tượng. Khi mạng được đào tạo, giá trị của trọng số được điều chỉnh và chúng sẽ hội tụ về trọng số mà chính xác nắm bắt được mối quan hệ giữa các tính năng.
Đây là cách một mạng nơ-ron tiến hành, và CNNs bao gồm hai nửa: một mạng nơ-ron tiến hành và một nhóm các lớp tích chập.
Những gì là Mạng nơ-ron Tích chập (CNNs)?
Những “tích chập” đó xảy ra trong một mạng nơ-ron tích chập là gì? Một tích chập là một phép toán toán học tạo ra một tập hợp trọng số, về cơ bản tạo ra một biểu diễn của các phần của hình ảnh. Tập hợp trọng số này được gọi là một hạt nhân hoặc bộ lọc. Bộ lọc được tạo ra nhỏ hơn toàn bộ hình ảnh đầu vào, chỉ bao phủ một phần của hình ảnh. Các giá trị trong bộ lọc được nhân với các giá trị trong hình ảnh. Bộ lọc sau đó được di chuyển để tạo ra một biểu diễn của một phần mới của hình ảnh, và quá trình được lặp lại cho đến khi toàn bộ hình ảnh đã được bao phủ.
Một cách khác để nghĩ về điều này là tưởng tượng một bức tường gạch, với gạch đại diện cho các pixel trong hình ảnh đầu vào. Một “cửa sổ” đang được trượt trở lại và forth dọc theo bức tường, đó là bộ lọc. Các gạch có thể nhìn thấy được qua cửa sổ là các pixel có giá trị được nhân với các giá trị trong bộ lọc. Vì lý do này, phương pháp tạo trọng số với một bộ lọc thường được gọi là kỹ thuật “cửa sổ trượt”.
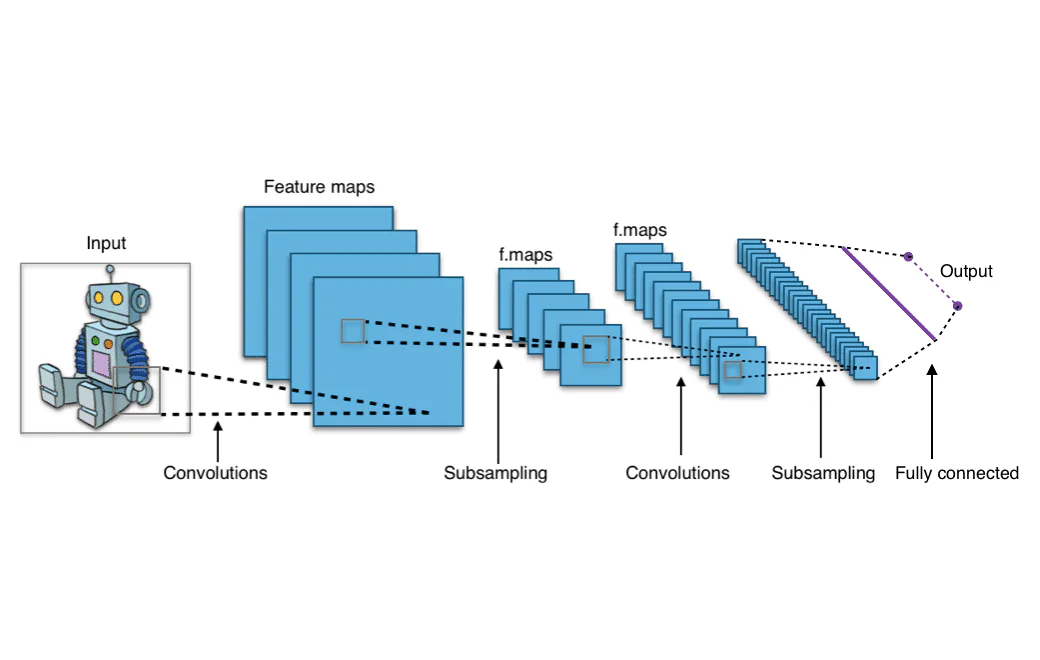
Đầu ra từ các bộ lọc được di chuyển xung quanh toàn bộ hình ảnh đầu vào là một mảng hai chiều đại diện cho toàn bộ hình ảnh. Mảng này được gọi là “bản đồ tính năng”.
Tại sao Tích chập là Thiết yếu
Mục đích của việc tạo ra tích chập là gì? Tích chập là cần thiết vì một mạng nơ-ron phải có thể giải thích các pixel trong một hình ảnh như các giá trị số. Chức năng của các lớp tích chập là chuyển đổi hình ảnh thành các giá trị số mà mạng nơ-ron có thể giải thích và sau đó trích xuất các mẫu liên quan từ. Công việc của các bộ lọc trong mạng tích chập là tạo ra một mảng hai chiều của các giá trị có thể được truyền vào các lớp sau của mạng nơ-ron, những lớp sẽ học các mẫu trong hình ảnh.
Bộ lọc và Kênh
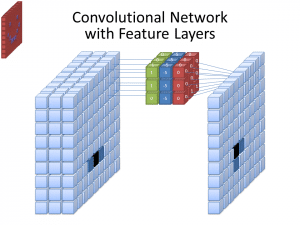
Photo: cecebur via Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)
CNNs không sử dụng chỉ một bộ lọc để học mẫu từ hình ảnh đầu vào. Nhiều bộ lọc được sử dụng, vì các mảng khác nhau được tạo ra bởi các bộ lọc khác nhau dẫn đến một biểu diễn phức tạp, phong phú hơn của hình ảnh đầu vào. Các số bộ lọc phổ biến cho CNNs là 32, 64, 128 và 512. Số bộ lọc càng nhiều, cơ hội càng nhiều để CNN kiểm tra dữ liệu đầu vào và học từ nó.
Một CNN phân tích sự khác biệt trong giá trị pixel để xác định biên giới của các đối tượng. Trong một hình ảnh thang độ xám, CNN chỉ xem xét sự khác biệt trong đen và trắng, từ sáng đến tối. Khi hình ảnh là hình ảnh màu, không chỉ CNN xem xét sự khác biệt về sáng và tối, mà còn phải xem xét ba kênh màu khác nhau – đỏ, xanh lá cây và xanh lam. Trong trường hợp này, các bộ lọc có 3 kênh, giống như hình ảnh chính nó. Số kênh mà một bộ lọc có được gọi là độ sâu của nó, và số kênh trong bộ lọc phải khớp với số kênh trong hình ảnh.
Kiến trúc Mạng nơ-ron Tích chập (CNN)
Hãy cùng xem kiến trúc hoàn chỉnh của một mạng nơ-ron tích chập. Một lớp tích chập được tìm thấy ở đầu của mọi mạng tích chập, vì nó cần thiết để chuyển đổi dữ liệu hình ảnh thành mảng số. Tuy nhiên, các lớp tích chập cũng có thể đến sau các lớp tích chập khác, có nghĩa là các lớp này có thể được xếp chồng lên nhau. Việc có nhiều lớp tích chập có nghĩa là đầu ra từ một lớp có thể trải qua các tích chập thêm và được nhóm lại với nhau trong các mẫu liên quan. Về thực tế, điều này có nghĩa là khi dữ liệu hình ảnh đi qua các lớp tích chập, mạng bắt đầu “nhận dạng” các tính năng phức tạp hơn của hình ảnh.
Các lớp đầu tiên của một ConvNet chịu trách nhiệm trích xuất các tính năng cấp thấp, chẳng hạn như các pixel tạo thành các đường thẳng đơn giản. Các lớp sau của ConvNet sẽ kết hợp các đường thẳng này thành hình dạng. Quá trình này của việc di chuyển từ phân tích cấp bề mặt đến phân tích cấp sâu tiếp tục cho đến khi ConvNet nhận dạng các hình dạng phức tạp như động vật, khuôn mặt người và ô tô.
Sau khi dữ liệu đã đi qua tất cả các lớp tích chập, nó đi vào phần kết nối dày của CNN. Các lớp kết nối dày là những gì một mạng nơ-ron tiến hành truyền thống trông như thế nào, một loạt các nút được sắp xếp thành các lớp được kết nối với nhau. Dữ liệu đi qua các lớp kết nối dày, những lớp học các mẫu được trích xuất bởi các lớp tích chập, và bằng cách này, mạng trở nên có khả năng nhận dạng đối tượng.










