Trí tuệ nhân tạo
Hướng tới Con người Trí tuệ Nhân tạo Thực thời với Rendering Lumigraph Neural

Mặc dù hiện tại có một làn sóng quan tâm đến các Trường Neuron Quang (NeRF), một công nghệ có khả năng tạo ra môi trường và vật thể 3D được tạo bởi trí tuệ nhân tạo, nhưng cách tiếp cận mới này đối với công nghệ tổng hợp hình ảnh vẫn đòi hỏi một lượng thời gian đào tạo lớn và thiếu một triển khai cho phép giao diện thực thời và phản hồi cao.
Tuy nhiên, một sự hợp tác giữa một số tên tuổi ấn tượng trong ngành công nghiệp và học thuật cung cấp một cách nhìn mới về thách thức này (được gọi chung là Tổng hợp Xem mới, hoặc NVS).
Bản nghiên cứu bài báo, có tiêu đề Rendering Lumigraph Neural, tuyên bố một sự cải thiện về tình trạng hiện tại khoảng hai bậc, đại diện cho một số bước tiến tới việc渲染 CG thực thời qua các đường ống máy học.

Rendering Lumigraph Neural (phải) cung cấp độ phân giải tốt hơn của các hiện tượng trộn lẫn và xử lý che khuất tốt hơn so với các phương pháp trước đây. Nguồn.
Mặc dù chỉ ghi nhận các tác giả từ Đại học Stanford và công ty công nghệ hiển thị holographic Raxium (hiện đang hoạt động ở chế độ ẩn), nhưng các đóng góp bao gồm một kiến trúc sư máy học chính tại Google, một nhà khoa học máy tính tại Adobe, và CTO tại StoryFile (đã tạo ra tiêu đề gần đây với một phiên bản trí tuệ nhân tạo của William Shatner).
Về việc quảng bá gần đây của Shatner, StoryFile dường như đang sử dụng NLR trong quy trình mới để tạo ra các thực thể tương tác được tạo bởi trí tuệ nhân tạo dựa trên các đặc điểm và câu chuyện của từng người.
https://www.youtube.com/watch?v=AEj2K4YzwiU
StoryFile hình dung việc sử dụng công nghệ này trong các màn hình bảo tàng, các câu chuyện tương tác trực tuyến, hiển thị holographic, thực tế ảo tăng cường (AR) và tài liệu di sản – và cũng似乎 đang xem xét các ứng dụng mới của NLR trong các cuộc phỏng vấn tuyển dụng và các ứng dụng hẹn hò ảo:

Các ứng dụng được đề xuất từ một video trực tuyến của StoryFile. Nguồn: https://www.youtube.com/watch?v=2K9J6q5DqRc
Chụp Volumetric Cho Giao Diện Tổng hợp Xem mới và Video
Nguyên tắc của chụp volumetric, trên phạm vi các bài báo đang tích lũy về chủ đề này, là ý tưởng chụp các hình ảnh tĩnh hoặc video của một đối tượng, và sử dụng máy học để ‘điền’ vào các điểm nhìn không được bao phủ bởi mảng camera ban đầu.

Nguồn: https://research.fb.com/wp-content/uploads/2019/06/Neural-Volumes-Learning-Dynamic-Renderable-Volumes-from-Images.pdf
Trong hình ảnh trên, lấy từ nghiên cứu AI 2019 của Facebook (xem dưới), chúng ta thấy bốn giai đoạn của chụp volumetric: nhiều camera thu được hình ảnh/hình ảnh; kiến trúc mã hóa/giải mã (hoặc các kiến trúc khác) tính toán và kết hợp mối quan hệ giữa các điểm nhìn; các thuật toán ray-marching tính toán các voxels (hoặc các đơn vị hình học không gian XYZ khác) của mỗi điểm trong không gian volumetric; và (trong hầu hết các bài báo gần đây) quá trình đào tạo diễn ra để tổng hợp một thực thể hoàn chỉnh có thể được điều khiển trong thời gian thực.
Đây là giai đoạn đào tạo rộng lớn và nặng về dữ liệu này đã giữ tổng hợp xem mới khỏi phạm vi của thời gian thực hoặc bắt kịp.
Sự thật rằng Tổng hợp Xem mới tạo ra một bản đồ 3D hoàn chỉnh của một không gian volumetric có nghĩa là nó tương đối đơn giản để khâu các điểm này lại với nhau thành một lưới CG truyền thống, hiệu quả捕获 và diễn đạt một con người CG (hoặc bất kỳ đối tượng nào khác tương đối bị giới hạn) trên đường bay.
Các phương pháp sử dụng NeRF dựa trên các đám mây điểm và bản đồ độ sâu để tạo ra các nội suy giữa các điểm nhìn thưa thớt của các thiết bị chụp:

NeRF có thể tạo ra độ sâu volumetric thông qua tính toán bản đồ độ sâu, chứ không phải tạo ra lưới CG. Nguồn: https://www.youtube.com/watch?v=JuH79E8rdKc
Mặc dù NeRF có khả năng tính toán lưới, nhưng hầu hết các triển khai không sử dụng điều này để tạo ra các cảnh volumetric.
Ngược lại, cách tiếp cận của Implicit Differentiable Renderer (IDR) được xuất bản bởi Viện Khoa học Weizmann vào tháng 10 năm 2020, dựa trên việc khai thác thông tin lưới 3D được tạo tự động từ mảng camera:

Các ví dụ về các bản chụp IDR được chuyển đổi thành lưới CG tương tác. Nguồn: https://www.youtube.com/watch?v=C55y7RhJ1fE
Mặc dù NeRF thiếu khả năng ước tính hình dạng của IDR, nhưng IDR không thể sánh với chất lượng hình ảnh của NeRF, và cả hai đều yêu cầu tài nguyên rộng lớn để đào tạo và thu thập (mặc dù các đổi mới gần đây trong NeRF đang bắt đầu địa chỉ vấn đề này).

Tấm giá đỡ camera tùy chỉnh của NLR với 16 camera GoPro HERO7 và 6 camera Back-Bone H7PRO trung tâm. Để渲染 ‘thời gian thực’, những camera này hoạt động với tốc độ tối thiểu 60fps. Nguồn: https://arxiv.org/pdf/2103.11571.pdf
Thay vào đó, Rendering Lumigraph Neural sử dụng SIREN (Mạng lưới Đại diện Sinusoidal) để kết hợp các điểm mạnh của mỗi cách tiếp cận vào khuôn khổ của nó, nhằm tạo ra đầu ra có thể sử dụng trực tiếp trong các đường ống đồ họa thời gian thực hiện có.
SIREN đã được sử dụng cho các triển khai tương tự trong suốt năm qua, và hiện đại diện cho một gọi API phổ biến cho các Colabs của người đam mê trong các cộng đồng tổng hợp hình ảnh; tuy nhiên, sự đổi mới của NLR là áp dụng SIREN cho việc giám sát hình ảnh đa góc nhìn hai chiều, điều này gây khó khăn do mức độ mà SIREN tạo ra đầu ra quá phù hợp hơn là tổng quát.
Sau khi lưới CG được trích xuất từ các hình ảnh mảng, lưới được raster hóa thông qua OpenGL, và các vị trí đỉnh của lưới được ánh xạ đến các pixel phù hợp, sau đó trộn của các bản đồ đóng góp được tính toán.
Lưới kết quả được tổng quát hóa và đại diện hơn so với NeRF (xem hình dưới), yêu cầu ít tính toán hơn, và không áp dụng chi tiết quá mức vào các khu vực (như da mặt mịn) mà không thể được hưởng lợi từ nó:

Nguồn: https://arxiv.org/pdf/2103.11571.pdf
Về mặt tiêu cực, NLR vẫn chưa có khả năng chiếu sáng động hoặc chiếu sáng lại, và đầu ra bị giới hạn ở các bản đồ bóng và các yếu tố chiếu sáng khác được thu được tại thời điểm chụp. Các nhà nghiên cứu dự định sẽ giải quyết vấn đề này trong các công việc tương lai.
Ngoài ra, bài báo thừa nhận rằng các hình dạng được tạo ra bởi NLR không chính xác như một số cách tiếp cận thay thế, chẳng hạn như Lựa chọn Xem Pixel cho Stereo đa góc nhìn không cấu trúc, hoặc nghiên cứu của Viện Weizmann được đề cập trước đó.
Sự trỗi dậy của Tổng hợp Hình ảnh Volumetric
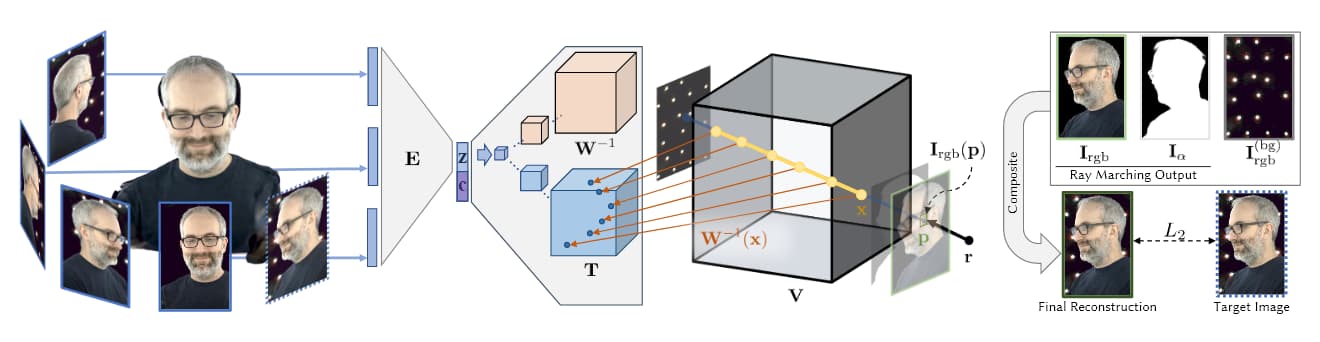
Ý tưởng tạo ra các thực thể 3D từ một loạt ảnh giới hạn với các mạng lưới thần kinh đã có từ trước NeRF, với các bài báo tầm nhìn từ năm 2007 hoặc trước đó. Vào năm 2019, bộ phận nghiên cứu AI của Facebook đã tạo ra một bài báo nghiên cứu quan trọng, Neural Volumes: Learning Dynamic Renderable Volumes from Images, lần đầu tiên cho phép các giao diện phản hồi cho các con người tổng hợp được tạo bởi máy học dựa trên chụp volumetric.

Nghiên cứu của Facebook năm 2019 đã cho phép tạo ra một giao diện người dùng phản hồi cho một người volumetric. Nguồn: https://research.fb.com/publications/neural-volumes-learning-dynamic-renderable-volumes-from-images/













{kind=link}