Góc nhìn Anderson
Những Nguy Cơ Của Việc Sử Dụng Trích Dẫn Để Xác Thực Nội Dung NLG

Ý Kiến Mô hình Tạo ngôn ngữ tự nhiên (NLG) như GPT-3 có thể “hoang tưởng” vật liệu mà chúng trình bày trong bối cảnh thông tin thực tế. Trong một thời đại quan tâm đặc biệt đến sự phát triển của tin tức giả dựa trên văn bản, những “sự bay bổng” này của trí tưởng tượng đại diện cho một chướng ngại vật tồn tại đối với sự phát triển của các hệ thống viết và tóm tắt tự động, và đối với tương lai của báo chí dựa trên trí tuệ nhân tạo, trong số các lĩnh vực phụ khác của Xử lý ngôn ngữ tự nhiên (NLP).
Vấn đề trung tâm là các mô hình ngôn ngữ kiểu GPT lấy các tính năng và lớp chính từ các tập dữ liệu đào tạo rất lớn và học cách sử dụng các tính năng này như các khối xây dựng của ngôn ngữ một cách khéo léo và chân thực, bất kể độ chính xác của nội dung được tạo ra, hoặc thậm chí khả năng chấp nhận của nó.
Các hệ thống NLG do đó hiện phụ thuộc vào việc xác minh thông tin của con người theo một trong hai cách tiếp cận: các mô hình được sử dụng như các máy tạo văn bản hạt giống được truyền ngay đến người dùng, hoặc để xác minh hoặc một số hình thức chỉnh sửa hoặc thích nghi khác; hoặc con người được sử dụng như các bộ lọc tốn kém để cải thiện chất lượng của các tập dữ liệu nhằm thông báo cho các mô hình ít trừu tượng và “sáng tạo” hơn (mà trong chính nó vẫn khó tin cậy về độ chính xác của thông tin, và sẽ yêu cầu thêm các lớp giám sát của con người).
Tin Cũ và Sự Thật Giả
Mô hình NLG có khả năng tạo ra đầu ra thuyết phục và hợp lý vì chúng đã học kiến trúc ngữ nghĩa, chứ không phải là hấp thụ một cách trừu tượng hơn lịch sử thực sự, khoa học, kinh tế, hoặc bất kỳ chủ đề nào khác mà chúng có thể được yêu cầu phát biểu, những thứ này hiệu quả được “đính kèm” trong dữ liệu nguồn.
Độ chính xác của thông tin mà các mô hình NLG tạo ra giả định rằng đầu vào mà chúng được đào tạo là đáng tin cậy và cập nhật, điều này đặt ra một gánh nặng phi thường về việc tiền xử lý và xác minh dựa trên con người – một chướng ngại vật tốn kém mà lĩnh vực nghiên cứu NLP đang giải quyết trên nhiều mặt trận.
Các hệ thống quy mô GPT-3 đòi hỏi một lượng thời gian và tiền bạc khổng lồ để đào tạo, và một khi được đào tạo, chúng khó cập nhật ở mức “lõi” có thể coi là cơ bản. Mặc dù các sửa đổi cục bộ dựa trên phiên và người dùng có thể tăng cường tiện ích và độ chính xác của các mô hình được triển khai, những lợi ích hữu ích này khó có thể chuyển giao trở lại mô hình cốt lõi mà không cần đào tạo lại toàn bộ hoặc một phần.
Do đó, việc tạo ra các mô hình ngôn ngữ được đào tạo để tận dụng thông tin mới nhất là rất khó khăn.

Được đào tạo trước cả sự kiện COVID, text-davinci-002 – phiên bản GPT-3 được coi là ‘khả năng nhất’ bởi người tạo OpenAI – có thể xử lý 4000 token mỗi yêu cầu, nhưng không biết gì về COVID-19 hoặc cuộc xâm lược Ukraine năm 2022 (các lời nhắc và phản hồi này là từ ngày 5 tháng 4 năm 2022). Thú vị, ‘không biết’ thực sự là một câu trả lời chấp nhận được trong cả hai trường hợp thất bại, nhưng các lời nhắc tiếp theo dễ dàng thiết lập rằng GPT-3 không biết về những sự kiện này. Nguồn: https://beta.openai.com/playground
Một mô hình được đào tạo chỉ có thể truy cập vào ‘sự thật’ mà nó nội hóa tại thời điểm đào tạo, và rất khó để có được một câu trích dẫn chính xác và phù hợp khi cố gắng xác minh các tuyên bố của mô hình. Sự nguy hiểm thực sự của việc lấy trích dẫn từ GPT-3 mặc định (ví dụ) là đôi khi nó tạo ra các trích dẫn chính xác, dẫn đến sự tự tin sai lầm vào khía cạnh này của khả năng của nó:

Trên cùng, ba trích dẫn chính xác được lấy từ davinci-instruct-text GPT-3 năm 2021. Giữa, GPT-3 không thể trích dẫn một trong những câu nói nổi tiếng nhất của Einstein (“Thượng đế không chơi trò chơi với vũ trụ”), mặc dù lời nhắc không bí ẩn. Dưới cùng, GPT-3 gán một trích dẫn bê bối và hư cấu cho Albert Einstein, rõ ràng là tràn từ các câu hỏi trước về Winston Churchill trong cùng một phiên. Nguồn: Bài viết của tác giả năm 2021 tại https://www.width.ai/post/business-applications-for-gpt-3
GopherCite
Hy vọng giải quyết điểm yếu chung này trong các mô hình NLG, DeepMind của Google gần đây đã đề xuất GopherCite, một mô hình 280 tỷ tham số có khả năng trích dẫn bằng chứng cụ thể và chính xác để hỗ trợ các phản hồi được tạo ra cho các lời nhắc.



Ba ví dụ về GopherCite hỗ trợ các tuyên bố của nó với các trích dẫn thực sự. Nguồn: https://arxiv.org/pdf/2203.11147.pdf
GopherCite tận dụng học tăng cường từ sở thích của con người (RLHP) để đào tạo các mô hình truy vấn có khả năng trích dẫn trích dẫn thực sự làm bằng chứng hỗ trợ. Các trích dẫn được rút ra trực tiếp từ nhiều nguồn tài liệu thu được từ công cụ tìm kiếm, hoặc từ một tài liệu cụ thể do người dùng cung cấp.
Hiệu suất của GopherCite được đo lường thông qua đánh giá của con người về phản hồi của mô hình, được tìm thấy là ‘chất lượng cao’ 80% thời gian trên tập dữ liệu NaturalQuestions của Google, và 67% thời gian trên tập dữ liệu ELI5.
Trích Dẫn Sự Thật Giả
Tuy nhiên, khi được thử nghiệm trên TruthfulQA của Đại học Oxford, phản hồi của GopherCite hiếm khi được đánh giá là trung thực, so với các câu trả lời ‘đúng’ do con người biên tập.
Các tác giả cho rằng điều này là do khái niệm ‘các câu trả lời được hỗ trợ’ không định nghĩa sự thật theo cách khách quan, vì sự hữu ích của các trích dẫn nguồn có thể bị ảnh hưởng bởi các yếu tố khác, chẳng hạn như khả năng tác giả của trích dẫn là ‘hoang tưởng’ (tức là viết về thế giới hư cấu, tạo nội dung quảng cáo, hoặc hư cấu không chân thực theo những cách khác).



Các trường hợp GopherCite mà tính hợp lý không nhất thiết tương đương với ‘sự thật’.
Hiệu quả, điều cần thiết là phải phân biệt giữa ‘hỗ trợ’ và ‘đúng’ trong những trường hợp như vậy. Văn hóa con người hiện đang vượt xa học máy trong việc sử dụng các phương pháp và khuôn khổ được thiết kế để có được định nghĩa khách quan về sự thật, và ngay cả ở đó, trạng thái ‘thật’ dường như là tranh cãi và phủ nhận.
Vấn đề này là đệ quy trong các kiến trúc NLG tìm kiếm các cơ chế ‘chứng minh’ xác định: sự đồng thuận của con người được ép buộc vào dịch vụ như một chuẩn mực của sự thật thông qua các mô hình AMT kiểu ‘được thuê ngoài’, nơi các đánh giá viên của con người (và những người khác trung gian tranh chấp giữa họ) là phần tư và thiên vị.
Ví dụ, các thí nghiệm GopherCite ban đầu sử dụng mô hình ‘siêu đánh giá’ để chọn những người dùng tốt nhất để đánh giá đầu ra của mô hình, chọn chỉ những người đánh giá đã đạt được ít nhất 85% so với một tập hợp đảm bảo chất lượng. Cuối cùng, 113 siêu đánh giá viên đã được chọn cho nhiệm vụ.
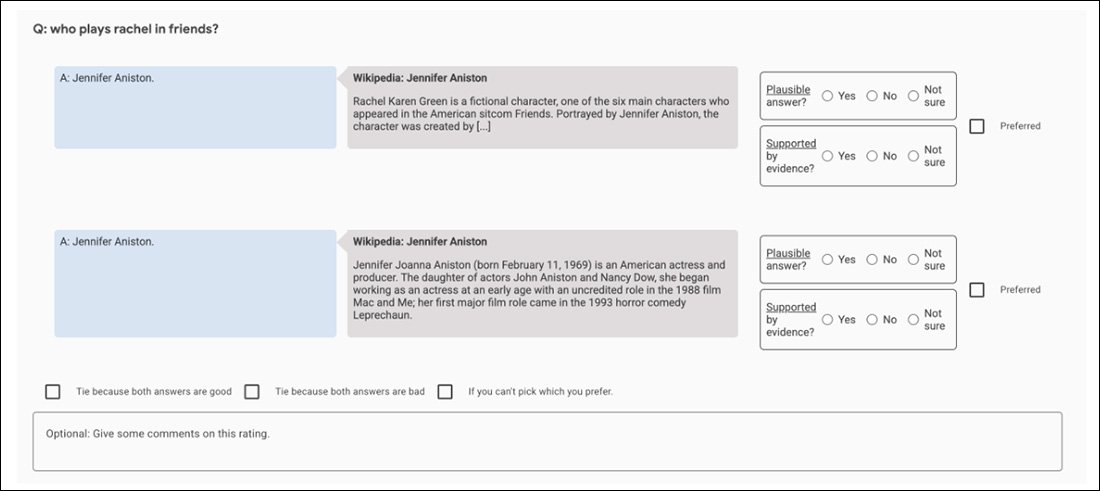
Ảnh chụp màn hình của ứng dụng so sánh được sử dụng để giúp đánh giá đầu ra của GopherCite.
Điều này có thể được coi là một bức tranh hoàn hảo về một cuộc theo đuổi phân hình không thể thắng: tập hợp đảm bảo chất lượng được sử dụng để đánh giá các đánh giá viên là một phép đo ‘được con người xác định’ khác về sự thật, cũng như tập hợp TruthfulQA của Oxford mà GopherCite đã được tìm thấy là không đủ.
Về nội dung được hỗ trợ và ‘xác thực’, tất cả những gì các hệ thống NLG có thể hy vọng tổng hợp từ việc đào tạo trên dữ liệu của con người là sự đa dạng và bất đồng của con người, điều này tự nó là một vấn đề không được đặt ra và không được giải quyết. Chúng ta có xu hướng trích dẫn các nguồn hỗ trợ quan điểm của mình và nói một cách có thẩm quyền và chắc chắn trong các trường hợp thông tin nguồn của chúng ta có thể đã lỗi thời, hoàn toàn không chính xác hoặc được đại diện một cách không trung thực theo những cách khác; và có khuynh hướng khuếch tán những quan điểm này trực tiếp vào tự nhiên, với quy mô và hiệu quả chưa từng có trong lịch sử, ngay vào đường đi của các khuôn khổ thu thập kiến thức nuôi các khuôn khổ NLG mới.
Do đó, nguy cơ liên quan đến sự phát triển của các hệ thống NLG được hỗ trợ bởi trích dẫn dường như gắn liền với bản chất không thể đoán trước của tài liệu nguồn. Bất kỳ cơ chế nào (như trích dẫn trực tiếp và trích dẫn) làm tăng sự tự tin của người dùng vào đầu ra NLG là, ở trạng thái hiện tại của nghệ thuật, đang thêm một cách nguy hiểm vào tính xác thực, nhưng không phải là tính chính xác của đầu ra.
Các kỹ thuật như vậy có khả năng hữu ích khi NLP cuối cùng tái tạo các ‘kaleidoscopes’ của Orwell trong Nineteen Eighty-Four; nhưng chúng đại diện cho một sự theo đuổi nguy hiểm đối với phân tích tài liệu khách quan, báo chí dựa trên trí tuệ nhân tạo, và các ứng dụng ‘phi hư cấu’ khác của tóm tắt máy và tạo văn bản tự phát hoặc hướng dẫn.
Được xuất bản lần đầu vào ngày 5 tháng 4 năm 2022. Cập nhật lúc 3:29 chiều EET để sửa đổi thuật ngữ.












