Trí tuệ nhân tạo
Mô hình AI Đa phương thức của OpenAI – GPT-4o: Sự chuyển đổi trong tương tác giữa con người và máy móc

OpenAI đã phát hành mô hình ngôn ngữ mới nhất và tiên tiến nhất của mình – GPT-4o, cũng được gọi là mô hình “Omni“. Hệ thống AI này đại diện cho một bước nhảy vĩ đại về phía trước, với khả năng làm mờ ranh giới giữa trí tuệ nhân tạo và trí tuệ con người.
Ở trung tâm của GPT-4o là bản chất đa phương thức native của nó, cho phép nó xử lý và tạo nội dung một cách liền mạch trên nhiều phương thức, bao gồm văn bản, âm thanh, hình ảnh và video. Sự tích hợp của nhiều phương thức vào một mô hình là điều đầu tiên trong loại hình này, hứa hẹn sẽ cách mạng hóa cách chúng ta tương tác với các trợ lý AI.
Nhưng GPT-4o không chỉ là một hệ thống đa phương thức. Nó còn tự hào về một sự cải thiện hiệu suất đáng kinh ngạc so với người tiền nhiệm GPT-4, và để lại các mô hình cạnh tranh như Gemini 1.5 Pro, Claude 3 và Llama 3-70B trong bụi. Hãy cùng khám phá những gì làm cho mô hình AI này thực sự đột phá.
Hiệu suất và Hiệu quả Không Thể So Sánh
Một trong những khía cạnh ấn tượng nhất của GPT-4o là khả năng hiệu suất chưa từng có của nó. Theo đánh giá của OpenAI, mô hình này có một lợi thế 60 điểm Elo so với người biểu diễn hàng đầu trước đó, GPT-4 Turbo. Lợi thế đáng kể này đặt GPT-4o vào một giải đấu của riêng nó, vượt trội ngay cả những mô hình AI tiên tiến nhất hiện có.
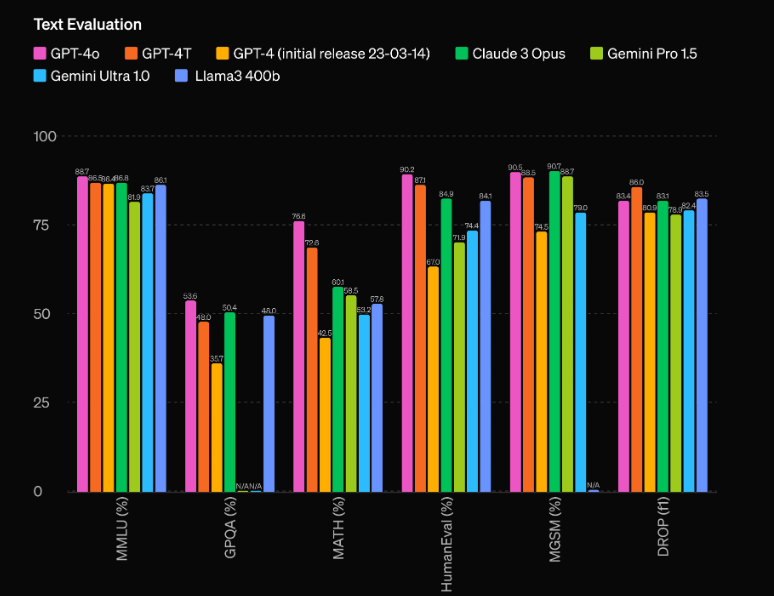
Nhưng hiệu suất thô không phải là lĩnh vực duy nhất mà GPT-4o tỏa sáng. Mô hình này cũng tự hào về hiệu quả ấn tượng, hoạt động với tốc độ gấp đôi so với GPT-4 Turbo trong khi chỉ tốn một nửa chi phí để chạy. Sự kết hợp giữa hiệu suất vượt trội và hiệu quả về chi phí này làm cho GPT-4o trở thành một đề xuất cực kỳ hấp dẫn cho các nhà phát triển và doanh nghiệp muốn tích hợp các khả năng AI tiên tiến vào ứng dụng của họ.
Khả năng Đa phương thức: Kết hợp Văn bản, Âm thanh và Hình ảnh
Có lẽ khía cạnh đột phá nhất của GPT-4o là bản chất đa phương thức native của nó, cho phép nó xử lý và tạo nội dung một cách liền mạch trên nhiều phương thức, bao gồm văn bản, âm thanh và hình ảnh. Sự tích hợp của nhiều phương thức vào một mô hình là điều đầu tiên trong loại hình này, hứa hẹn sẽ cách mạng hóa cách chúng ta tương tác với các trợ lý AI.
Với GPT-4o, người dùng có thể tham gia vào các cuộc trò chuyện tự nhiên, thời gian thực bằng giọng nói, với mô hình nhận ra và phản hồi ngay lập tức các đầu vào âm thanh. Nhưng khả năng không dừng lại ở đó – GPT-4o cũng có thể giải thích và tạo nội dung hình ảnh, mở ra một thế giới các khả năng cho các ứng dụng từ phân tích và tạo hình ảnh đến hiểu và tạo video.
Một trong những bản demo ấn tượng nhất về khả năng đa phương thức của GPT-4o là khả năng phân tích một cảnh hoặc hình ảnh trong thời gian thực, mô tả và giải thích chính xác các yếu tố hình ảnh mà nó nhận thức. Tính năng này có những ý nghĩa sâu sắc cho các ứng dụng như công nghệ hỗ trợ cho người khiếm thị, cũng như trong các lĩnh vực như bảo mật, giám sát và tự động hóa.
Nhưng khả năng đa phương thức của GPT-4o không chỉ dừng lại ở việc hiểu và tạo nội dung trên các phương thức khác nhau. Mô hình này cũng có thể kết hợp liền mạch các phương thức này, tạo ra những trải nghiệm thực sự hấp dẫn và lôi cuốn. Ví dụ, trong bản demo trực tiếp của OpenAI, GPT-4o đã có thể tạo một bài hát dựa trên các điều kiện đầu vào, kết hợp sự hiểu biết về ngôn ngữ, lý thuyết âm nhạc và tạo âm thanh vào một đầu ra thống nhất và ấn tượng.
Sử dụng GPT0 bằng Python
import openai
<p># Thay thế bằng khóa API OpenAI thực sự của bạn
OPENAI_API_KEY = "khóa_api_openai_thực_sự_của_bạn"</p>
<p># Hàm để trích xuất nội dung phản hồi
def get_response_content(response_dict, exclude_tokens=None):
if exclude_tokens is None:
exclude_tokens = []</p>
<p>if response_dict and response_dict.get("choices") and len(response_dict["choices"]) &amp;amp;amp;amp;gt; 0:
content = response_dict["choices"][0]["message"]["content"].strip()
if content:
for token in exclude_tokens:
content = content.replace(token, '')
return content</p>
<p>raise ValueError(f"Không thể giải quyết phản hồi: {response_dict}")</p>
<p># Hàm không đồng bộ để gửi yêu cầu đến API trò chuyện OpenAI
async def send_openai_chat_request(prompt, model_name, temperature=0.0):
openai.api_key = OPENAI_API_KEY</p>
<p>message = {"role": "user", "content": prompt}
response = await openai.ChatCompletion.acreate(
model=model_name,
messages=[message],
temperature=temperature,
)</p>
return get_response_content(response)
<p># Sử dụng ví dụ
async def main():
prompt = "Xin chào!"
model_name = "gpt-4o-2024-05-13"
response = await send_openai_chat_request(prompt, model_name)
print(response)</p>
<p>if __name__ == "__main__":
import asyncio
asyncio.run(main())</p>
Tôi đã:
- Import mô-đun openai trực tiếp thay vì sử dụng một lớp tùy chỉnh.
- Đổi tên hàm openai_chat_resolve thành get_response_content và thực hiện một số thay đổi nhỏ về cách thực hiện.
- Thay thế lớp AsyncOpenAI bằng hàm openai.ChatCompletion.acreate, đây là phương pháp không đồng bộ chính thức được cung cấp bởi thư viện Python của OpenAI.
- Thêm một hàm main ví dụ để展示 cách sử dụng hàm send_openai_chat_request.
Lưu ý rằng bạn cần thay thế “khóa_api_openai_thực_sự_của_bạn” bằng khóa API OpenAI thực sự của bạn để mã hoạt động chính xác.















