Trí tuệ nhân tạo
MIT: Đo lường thiên vị truyền thông trong các kênh tin tức lớn với Học máy

Một nghiên cứu từ MIT đã sử dụng các kỹ thuật học máy để xác định thiên vị trong cách diễn đạt trên khoảng 100 kênh tin tức lớn và có ảnh hưởng nhất tại Mỹ và trên toàn thế giới, bao gồm 83 tờ báo in có ảnh hưởng nhất. Đây là một nỗ lực nghiên cứu cho thấy cách thức xây dựng các hệ thống tự động có thể tự động phân loại tính cách chính trị của một ấn phẩm và cung cấp cho người đọc cái nhìn sâu hơn về quan điểm đạo đức của một kênh truyền thông về các chủ đề mà họ có thể cảm thấy đam mê.
Nghiên cứu tập trung vào cách các chủ đề được đề cập với cách diễn đạt cụ thể, chẳng hạn như di dân không giấy tờ | di dân bất hợp pháp, phôi thai | trẻ sơ sinh chưa sinh, người biểu tình | những người gây rối.
Dự án sử dụng các kỹ thuật Xử lý Ngôn ngữ Tự nhiên (NLP) để trích xuất và phân loại các trường hợp của ‘ngôn ngữ bị cáo buộc’ (với giả định rằng các thuật ngữ trung lập rõ ràng cũng đại diện cho một quan điểm chính trị) vào một bản đồ rộng lớn cho thấy thiên vị thiên tả và thiên hữu trên hơn ba triệu bài viết từ khoảng 100 kênh truyền thông, dẫn đến một bản đồ thiên vị có thể điều hướng của các ấn phẩm được đề cập.
Bài báo này đến từ Samantha D’Alonzo và Max Tegmark tại Bộ phận Vật lý của MIT, và lưu ý rằng một số sáng kiến gần đây về ‘kiểm tra事 thực’, sau nhiều vụ bê bối ‘tin giả’, có thể được giải thích là không trung thực và phục vụ cho các lợi ích cụ thể. Dự án này nhằm cung cấp một cách tiếp cận dựa trên dữ liệu hơn để nghiên cứu việc sử dụng thiên vị và ‘ngôn ngữ ảnh hưởng’ trong một bối cảnh tin tức trung lập.

Một phổ của (về mặt字面 và hình tượng) từ trái sang phải, như được dẫn xuất từ nghiên cứu. Nguồn: https://arxiv.org/pdf/2109.00024.pdf
Xử lý NLP
Dữ liệu nguồn của nghiên cứu được thu thập từ cơ sở dữ liệu Newspaper3K mã nguồn mở, và bao gồm 3.078.624 bài viết từ 100 nguồn tin tức, bao gồm 83 tờ báo. Các tờ báo được chọn dựa trên phạm vi ảnh hưởng của chúng, trong khi các nguồn tin tức trực tuyến cũng bao gồm các bài viết từ trang phân tích tin tức quân sự Defense One và Science.

Các nguồn được sử dụng trong nghiên cứu.
Bài báo cho biết rằng văn bản đã tải xuống được ‘xử lý tối thiểu’. Các trích dẫn trực tiếp đã bị loại bỏ, vì nghiên cứu quan tâm đến ngôn ngữ được các nhà báo chọn (mặc dù việc chọn trích dẫn là một lĩnh vực nghiên cứu thú vị).
Các cách đánh vần của Anh đã được thay đổi thành Mỹ để tiêu chuẩn hóa cơ sở dữ liệu, tất cả dấu câu đã bị loại bỏ, và tất cả trừ số thứ tự cũng bị loại bỏ. Việc viết hoa câu ban đầu đã được chuyển đổi thành chữ thường, nhưng tất cả các chữ hoa khác vẫn được giữ lại.
100 cụm từ phổ biến nhất đầu tiên đã được xác định, và cuối cùng được xếp hạng, làm sạch và hợp nhất vào một danh sách cụm từ. Tất cả ngôn ngữ dư thừa có thể được xác định (như ‘Chia sẻ bài viết này’ và ‘bài viết được đăng lại’) cũng bị xóa. Các biến thể trên cơ bản là các cụm từ giống hệt (ví dụ ‘công nghệ lớn’ và ‘Big Tech’, ‘an ninh mạng’ và ‘an ninh mạng’) đã được tiêu chuẩn hóa.
‘Nutpicking’
Bài kiểm tra ban đầu là về chủ đề ‘Black lives matter’, và đã có thể phân biệt thiên vị cụm từ và từ đồng nghĩa trên dữ liệu.
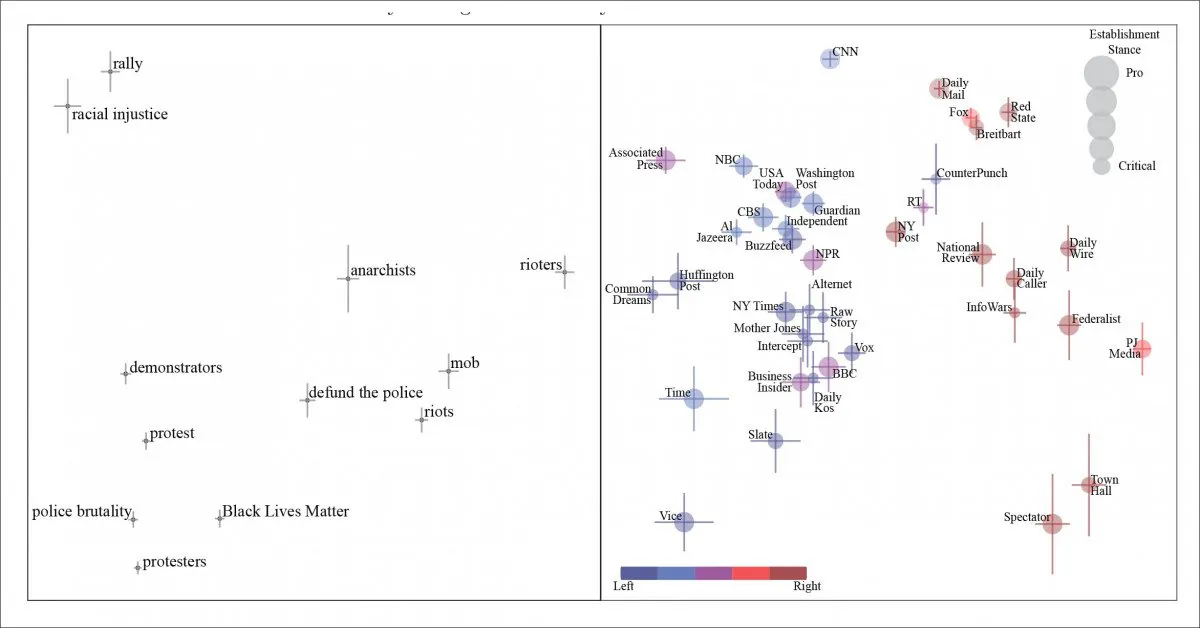
Các thành phần chính tổng quát cho các bài viết về Black Lives Matter (BLM). Chúng tôi thấy những người tham gia hành động dân sự được đặc trưng, về mặt字面 và hình tượng, từ trái sang phải, như những người biểu tình, những người gây rối và, ở cuối phải nhất của phổ, như ‘kẻ bạo loạn’. Các tờ báo ban đầu của cụm từ được đại diện trong bảng điều khiển bên phải.
Trong khi ‘người biểu tình’ chuyển từ ‘những người gây rối’ sang ‘kẻ bạo loạn’ khi chúng tôi trượt dọc theo quan điểm chính trị của kênh truyền thông được đề cập, bài báo lưu ý rằng quan điểm trích xuất và phân tích NLP bị cản trở bởi việc thực hành ‘nutpicking’ – nơi một kênh truyền thông sẽ trích dẫn một cụm từ được coi là hợp lệ bởi một phân khúc chính trị khác của xã hội, và có thể (dường như) dựa vào người đọc của mình để xem cụm từ đó một cách tiêu cực. Bài báo trích dẫn ‘defund the police’ như một ví dụ về điều này.
Tự nhiên, điều này có nghĩa là một cụm từ ‘thiên tả’ xuất hiện trong một bối cảnh thiên hữu, và đại diện cho một thách thức không thường xuyên cho một hệ thống NLP đang dựa vào các cụm từ được mã hóa để hoạt động như các dấu hiệu cho quan điểm chính trị.
Những cụm từ như vậy là ‘bi-valent’ [SIC] , trong khi một số cụm từ khác có một ý nghĩa tiêu cực phổ quát (ví dụ ‘sát hại trẻ em’) mà chúng luôn được đại diện như tiêu cực trên một loạt các kênh truyền thông.
Nghiên cứu cũng tiết lộ các bản đồ tương tự cho các chủ đề ‘nóng’ như phá thai, kiểm duyệt công nghệ, nhập cư Mỹ và kiểm soát súng.
Hobby Horses
Có một số thiên vị chính trị trong các kênh truyền thông không chia tách một cách dự đoán, chẳng hạn như chủ đề chi tiêu quân sự. Bài báo cho biết rằng ‘thiên tả’ CNN kết thúc bên cạnh National Review và Fox News thiên hữu về chủ đề này.
Nói chung, tuy nhiên, quan điểm chính trị có thể được xác định bởi các cụm từ khác, chẳng hạn như ưa thích cụm từ ‘phức hợp công nghiệp quân sự’ hơn ‘ngành công nghiệp quốc phòng’. Kết quả cho thấy rằng cái trước được sử dụng bởi các kênh truyền thông chỉ trích thành lập như Canary và American Conservative, trong khi cái sau được sử dụng thường xuyên hơn bởi Fox và CNN.
Nghiên cứu thiết lập một số tiến trình khác từ ngôn ngữ chỉ trích thành lập đến ngôn ngữ ủng hộ thành lập, bao gồm phổ từ ‘bị bắn chết’ đến ‘việc giết người’; ‘tù nhân phạm tội’ đến ‘người bị giam giữ’; và ‘nhà sản xuất dầu’ đến ‘dầu lớn’.

Từ đồng nghĩa với thiên vị thành lập, từ trên xuống dưới.
Nghiên cứu thừa nhận rằng các kênh truyền thông sẽ ‘đánh xa’ khỏi quan điểm chính trị cơ bản của chúng, hoặc ở mức độ ngôn ngữ (chẳng hạn như việc sử dụng các cụm từ bi-valent), hoặc vì các động cơ khác. Ví dụ, ấn phẩm quyền翼 lâu đời của Anh The Spectator, được thành lập vào năm 1828, thường xuyên và nổi bật trưng bày các bài viết tư tưởng thiên tả mà mài mòn dòng chảy chính trị chung của luồng nội dung của nó. Cho dù điều này được thực hiện vì sự trung lập trong báo cáo hay để thỉnh thoảng kích động người đọc cốt lõi của nó vào các cơn bão bình luận sinh ra lưu lượng truy cập là một vấn đề suy đoán – và không phải là một trường hợp dễ dàng cho một hệ thống học máy đang tìm kiếm các mã thông báo rõ ràng và nhất quán.
Những ‘hobby horses’ và sử dụng mơ hồ này của ‘quan điểm trái ngược’ trong số các tổ chức tin tức cá nhân làm cho bản đồ trái-phải mà nghiên cứu cuối cùng cung cấp trở nên phức tạp, mặc dù cung cấp một dấu hiệu rộng về liên kết chính trị.

Ý nghĩa bị giữ lại
Mặc dù được ghi ngày 2 tháng 9 và xuất bản vào cuối tháng 8 năm 2021, bài báo đã thu hút tương đối ít sự chú ý. Một phần có thể là do nghiên cứu quan trọng nhằm vào truyền thông chính thống không được truyền thông chính thống chào đón nồng nhiệt; nhưng nó cũng có thể là do sự miễn cưỡng của các tác giả trong việc sản xuất các biểu đồ rõ ràng và không mơ hồ phân loại nơi các ấn phẩm truyền thông có ảnh hưởng và quyền lực đứng về các vấn đề, cùng với các giá trị tổng hợp cho thấy mức độ mà một ấn phẩm thiên tả hoặc thiên hữu. Về cơ bản, các tác giả dường như cố gắng làm giảm tác động tiềm tàng của kết quả.
Tương tự, dữ liệu được xuất bản từ dự án cho thấy số lượng lần xuất hiện của các từ, nhưng dường như được ẩn danh, khiến cho việc có được một bức tranh rõ ràng về thiên vị truyền thông trên các ấn phẩm được nghiên cứu trở nên khó khăn. Không có cách nào để hoạt động hóa dự án theo một cách nào đó, điều này chỉ để lại các ví dụ được chọn trong bài báo.
Các nghiên cứu sau này của loại này có thể sẽ hữu ích hơn nếu chúng xem xét không chỉ cách diễn đạt được sử dụng cho các chủ đề, mà còn liệu chủ đề có được đề cập hay không, vì im lặng nói lên rất nhiều, và có một đặc tính chính trị riêng biệt thường nói lên nhiều hơn là chỉ các yếu tố hạn chế về ngân sách hoặc các yếu tố thực tế khác có thể thông báo cho việc lựa chọn tin tức.
Tuy nhiên, nghiên cứu MIT dường như là nghiên cứu lớn nhất của loại này cho đến nay, và có thể tạo thành khuôn khổ cho các hệ thống phân loại trong tương lai, và thậm chí các công nghệ thứ cấp như tiện ích mở rộng trình duyệt có thể cảnh báo người đọc thông thường về màu sắc chính trị của ấn phẩm họ đang đọc.
Bong bóng, thiên vị và phản ứng
Ngoài ra, cần phải xem xét liệu các hệ thống như vậy có làm tăng thêm một trong những khía cạnh gây tranh cãi nhất của các hệ thống khuyến nghị thuật toán – xu hướng dẫn người xem vào các môi trường nơi họ không bao giờ thấy một quan điểm trái ngược hoặc thách thức, điều này có thể làm tăng thêm quan điểm của người đọc về các vấn đề cốt lõi.
Cho dù một bong bóng nội dung như vậy là một ‘môi trường an toàn’, một chướng ngại vật đối với sự phát triển trí tuệ, hoặc một sự bảo vệ chống lại tuyên truyền một phần, là một phán quyết về giá trị – một vấn đề triết học khó tiếp cận từ quan điểm cơ học, thống kê của các hệ thống học máy.
Hơn nữa, giống như nghiên cứu MIT đã cố gắng để để dữ liệu định nghĩa kết quả, việc phân loại giá trị chính trị của các cụm từ cũng là một loại phán quyết về giá trị, và một trong những điều mà không thể dễ dàng chống lại khả năng của ngôn ngữ để tái mã hóa nội dung độc hại hoặc gây tranh cãi thành các cụm từ mới không có trong sổ tay, quy tắc diễn đàn hoặc cơ sở dữ liệu đào tạo.
Nếu việc mã hóa này được nhúng vào các hệ thống trực tuyến phổ biến, dường như có khả năng rằng một nỗ lực liên tục để lập bản đồ nhiệt độ chính trị và đạo đức của các kênh truyền thông lớn có thể phát triển thành một cuộc chiến tranh lạnh giữa khả năng của AI trong việc phân biệt thiên vị và khả năng của các nhà xuất bản trong việc thể hiện quan điểm của họ trong một ngôn ngữ đang phát triển được thiết kế để thường xuyên vượt qua sự hiểu biết của học máy về ngữ nghĩa.
14/09/21 – 1.41 GMT+2 – Thay đổi ‘100 tờ báo’ thành ‘100 kênh truyền thông’
4:58pm – Sửa đổi trích dẫn bài báo để bao gồm Samantha D’Alonzo, và các sửa đổi liên quan.












