
Trí tuệ nhân tạo
Máy dò Deepfake theo đuổi nền tảng mới: Các mô hình và GAN khuếch tán tiềm ẩn

Ý kiến Gần đây, cộng đồng nghiên cứu phát hiện deepfake, kể từ cuối năm 2017 hầu như chỉ tập trung vào tự động mã hóa- dựa trên khuôn khổ được công chiếu vào thời điểm đó trước sự kinh ngạc của công chúng (và mất tinh thần), đã bắt đầu quan tâm đến các kiến trúc ít trì trệ hơn, bao gồm khuếch tán tiềm ẩn các mô hình chẳng hạn như DALL-E2 và Khuếch tán ổn định, cũng như đầu ra của Mạng đối thủ sáng tạo (GAN). Ví dụ, vào tháng XNUMX, UC Berkeley công bố kết quả về nghiên cứu phát triển máy dò cho đầu ra của DALL-E 2 đang chiếm ưu thế lúc bấy giờ.
Điều dường như đang thúc đẩy mối quan tâm ngày càng tăng này là bước tiến hóa đột ngột về khả năng và tính khả dụng của các mô hình khuếch tán tiềm ẩn vào năm 2022, với nguồn đóng và quyền truy cập hạn chế. phát hành của DALL-E 2 vào mùa xuân, tiếp theo vào cuối mùa hè bởi sự giật gân mở tìm nguồn cung ứng of Stable Diffusion bởi sự ổn định.ai.
GAN cũng đã được nghiên cứu lâu dài trong bối cảnh này, mặc dù ít mạnh mẽ hơn, vì nó là rất khó khăn để sử dụng chúng để tái tạo người dựa trên video một cách thuyết phục và công phu; ít nhất, so với các gói mã hóa tự động đáng kính hiện nay như Hoán đổi khuôn mặt và DeepFaceLab – và người anh em phát trực tiếp sau này, DeepFaceSống.
Hình ảnh chuyển động
Trong cả hai trường hợp, yếu tố khích lệ dường như là triển vọng của một giai đoạn nước rút phát triển tiếp theo cho video tổng hợp. Đầu tháng 2022 – và mùa hội nghị lớn của năm XNUMX – được đặc trưng bởi một loạt các giải pháp bất ngờ và bất ngờ cho nhiều lỗi tổng hợp video lâu nay khác nhau: Facebook đã sớm có phát hành mẫu nền tảng chuyển văn bản thành video của riêng mình, Google Research đã nhanh chóng nhấn chìm sự hoan nghênh ban đầu đó bằng cách công bố kiến trúc Imagen-to-Video T2V mới, có khả năng xuất ra cảnh quay độ phân giải cao (mặc dù chỉ thông qua mạng nâng cấp 7 lớp).
Nếu bạn tin rằng loại thứ này có ba phần, thì hãy xem xét cả lời hứa bí ẩn của stable.ai rằng 'video sẽ ra mắt' trên Stable Diffusion, có vẻ như vào cuối năm nay, trong khi Runway, nhà đồng phát triển của Stable Diffusion có thực hiện một lời hứa tương tự, mặc dù không rõ liệu chúng có đang đề cập đến cùng một hệ thống hay không. Các tin nhắn bất hòa từ Giám đốc điều hành của Ổn định Emad Mostaque cũng đã hứa 'âm thanh, video [và] 3d'.
Điều gì xảy ra với việc cung cấp một số sản phẩm hoàn toàn mới? khung tạo âm thanh (một số dựa trên khuếch tán tiềm ẩn) và một mô hình khuếch tán mới có thể tạo ra chuyển động nhân vật chân thực, ý tưởng rằng các khung 'tĩnh' như GAN và bộ khuếch tán cuối cùng sẽ thay thế chúng để hỗ trợ điều chỉnh đến các khung hoạt hình bên ngoài đang bắt đầu đạt được sức hút thực sự.
Nói tóm lại, có vẻ như thế giới đang gặp khó khăn của các video deepfake dựa trên bộ mã hóa tự động, vốn chỉ có thể thay thế một cách hiệu quả phần trung tâm của khuôn mặt, vào thời điểm này năm sau có thể bị lu mờ bởi một thế hệ công nghệ mới có khả năng làm giả sâu dựa trên sự khuếch tán – các cách tiếp cận mã nguồn mở, phổ biến với khả năng giả mạo chân thực không chỉ toàn bộ cơ thể mà còn toàn bộ cảnh.
Vì lý do này, có lẽ, cộng đồng nghiên cứu chống deepfake đang bắt đầu coi trọng việc tổng hợp hình ảnh và nhận ra rằng nó có thể phục vụ nhiều mục đích hơn là chỉ tạo ra ảnh hồ sơ LinkedIn giả mạo; và rằng nếu tất cả các không gian tiềm ẩn khó chữa của chúng có thể thực hiện được về mặt chuyển động thời gian là để hoạt động như một trình kết xuất kết cấu thực sự tuyệt vời, điều đó thực sự có thể là quá đủ.
Blade Runner
Hai bài báo mới nhất lần lượt đề cập đến khuếch tán tiềm ẩn và phát hiện deepfake dựa trên GAN, lần lượt là: DE-FAKE: Phát hiện và ghi nhận các hình ảnh giả được tạo bởi các mô hình khuếch tán chuyển văn bản thành hình ảnh, sự hợp tác giữa Trung tâm Bảo mật Thông tin và Salesforce của CISPA Helmholtz; Và BLADERUNNER: Biện pháp đối phó nhanh đối với các khuôn mặt StyleGAN tổng hợp (do AI tạo), từ Adam Dorian Wong tại Phòng thí nghiệm Lincoln của MIT.
Trước khi giải thích phương pháp mới của mình, bài viết sau sẽ dành một chút thời gian để kiểm tra các cách tiếp cận trước đó để xác định xem một hình ảnh có được tạo bởi GAN hay không (bài báo đề cập cụ thể đến dòng StyleGAN của NVIDIA).
Phương pháp 'Brady Bunch' - có lẽ là một tài liệu tham khảo vô nghĩa đối với bất kỳ ai không xem TV vào những năm 1970 hoặc những người đã bỏ lỡ các bộ phim chuyển thể từ những năm 1990 - xác định nội dung giả mạo GAN dựa trên các vị trí cố định mà các phần cụ thể của khuôn mặt GAN chắc chắn sẽ chiếm giữ, do tính chất thuộc lòng và khuôn mẫu của 'Quy trình sản xuất'.

Phương pháp 'Brady Bunch' được đề xuất bởi một webcast từ viện SANS vào năm 2022: một trình tạo khuôn mặt dựa trên GAN sẽ thực hiện sắp xếp các đặc điểm khuôn mặt nhất định một cách không chắc chắn, bên dưới nguồn gốc của ảnh, trong một số trường hợp nhất định. Nguồn: https://arxiv.org/ftp/arxiv/papers/2210/2210.06587.pdf
Một dấu hiệu hữu ích khác đã biết là StyleGAN thường xuyên không có khả năng hiển thị nhiều khuôn mặt (hình ảnh đầu tiên bên dưới), nếu cần, cũng như sự thiếu tài năng trong việc phối hợp phụ kiện (hình ảnh ở giữa bên dưới) và xu hướng sử dụng đường chân tóc để bắt đầu một sự ngẫu hứng. mũ (hình ảnh thứ ba bên dưới).

Phương pháp thứ ba mà nhà nghiên cứu thu hút sự chú ý là lớp phủ ảnh (một ví dụ có thể được nhìn thấy trong bài báo tháng XNUMX của chúng tôi về chẩn đoán rối loạn sức khỏe tâm thần do AI hỗ trợ), sử dụng phần mềm 'pha trộn hình ảnh' tổng hợp, chẳng hạn như chuỗi CombineZ để ghép nhiều hình ảnh thành một hình ảnh duy nhất, thường tiết lộ những điểm tương đồng cơ bản trong cấu trúc – một dấu hiệu tổng hợp tiềm năng.

Kiến trúc được đề xuất trong bài báo mới có tiêu đề (có thể chống lại tất cả các lời khuyên SEO) Blade Runner, tham khảo Kiểm tra Voight-Kampff xác định xem các nhân vật phản diện trong loạt phim khoa học viễn tưởng có phải là 'giả mạo' hay không.
Quy trình này bao gồm hai giai đoạn, giai đoạn đầu tiên là bộ phân tích PapersPlease, có thể đánh giá dữ liệu được thu thập từ các trang web có khuôn mặt GAN đã biết như thispersondoesnotexist.com hoặc created.photos.

Mặc dù có thể kiểm tra phiên bản rút gọn của mã tại GitHub (xem bên dưới), một số chi tiết được cung cấp về mô-đun này, ngoại trừ OpenCV và DLIB được sử dụng để phác thảo và phát hiện khuôn mặt trong tài liệu thu thập được.
Mô-đun thứ hai là Giữa chúng ta máy dò. Hệ thống được thiết kế để tìm kiếm vị trí đặt mắt phối hợp trong ảnh, một tính năng liên tục của đầu ra khuôn mặt của StyleGAN, điển hình trong kịch bản 'Brady Bunch' được nêu chi tiết ở trên. AmongUs được cung cấp bởi một máy dò 68 mốc tiêu chuẩn.

Chú thích điểm trên khuôn mặt thông qua Nhóm hiểu biết hành vi thông minh (IBUG), có mã vẽ biểu đồ mốc trên khuôn mặt được sử dụng trong gói Blade Runner.
Giữa chúng ta phụ thuộc vào các mốc được đào tạo trước dựa trên tọa độ 'Brady bundle' đã biết từ PapersPlease và được thiết kế để sử dụng đối với các mẫu trực tiếp trên web của hình ảnh khuôn mặt dựa trên StyleGAN.
Blade Runner, tác giả đề xuất, là một giải pháp plug-and-play dành cho các công ty hoặc tổ chức thiếu nguồn lực để phát triển các giải pháp nội bộ cho loại phát hiện deepfake được xử lý ở đây và là 'biện pháp ngăn chặn thời gian cho các biện pháp đối phó lâu dài hơn'.
Trên thực tế, trong lĩnh vực bảo mật đầy biến động và phát triển nhanh chóng này, không có nhiều or các giải pháp đám mây sẵn có của nhà cung cấp mà một công ty có nguồn lực hạn chế hiện có thể tin tưởng sử dụng.
Mặc dù Blade Runner hoạt động kém trước đeo kính Những người giả mạo StyleGAN, đây là một vấn đề tương đối phổ biến trên các hệ thống tương tự, vốn đang mong đợi có thể đánh giá các đường phân định bằng mắt làm điểm tham chiếu cốt lõi, bị che khuất trong những trường hợp như vậy.
Một phiên bản rút gọn của Blade Runner đã được phát hành để mở mã nguồn trên GitHub. Đã tồn tại một phiên bản sở hữu nhiều tính năng hơn, phiên bản này có thể xử lý nhiều ảnh, thay vì một ảnh duy nhất cho mỗi hoạt động của kho lưu trữ nguồn mở. Ông nói, tác giả dự định cuối cùng sẽ nâng cấp phiên bản GitHub lên cùng một tiêu chuẩn, nếu thời gian cho phép. Anh ấy cũng thừa nhận rằng StyleGAN có khả năng phát triển vượt ra ngoài những điểm yếu đã biết hoặc hiện tại của nó và phần mềm cũng sẽ cần phải phát triển song song.
KHỬ GIẢ
Kiến trúc DE-FAKE không chỉ nhằm mục đích đạt được 'phát hiện phổ quát' cho các hình ảnh được tạo bởi các mô hình khuếch tán chuyển văn bản thành hình ảnh, mà còn cung cấp một phương pháp để phân biệt cái nào mô hình khuếch tán tiềm ẩn (LD) tạo ra hình ảnh.
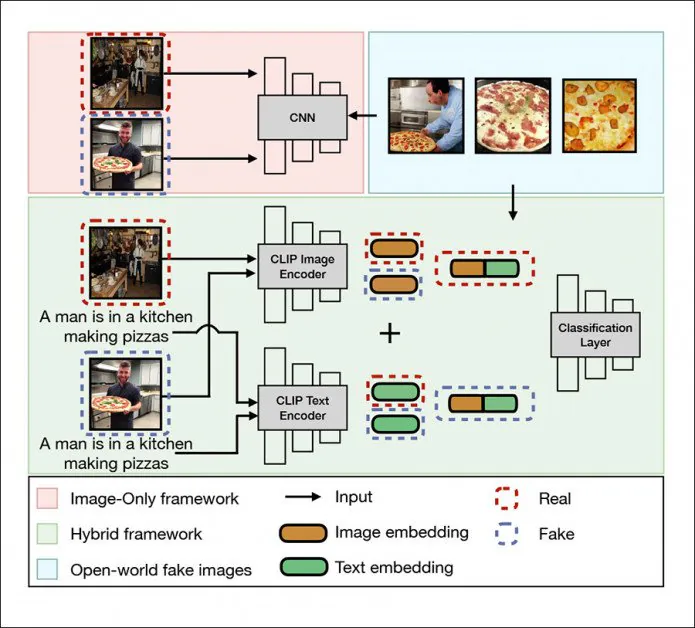
Khung phát hiện phổ quát trong DE-FAKE giải quyết các hình ảnh cục bộ, khung kết hợp (màu xanh lá cây) và hình ảnh thế giới mở (màu xanh lam). Nguồn: http://export.arxiv.org/pdf/2210.06998
Thành thật mà nói, tại thời điểm này, đây là một nhiệm vụ khá dễ dàng, vì tất cả các mô hình LD phổ biến – nguồn đóng hoặc nguồn mở – đều có những đặc điểm nổi bật đáng chú ý.
Ngoài ra, hầu hết đều chia sẻ một số điểm yếu chung, chẳng hạn như khuynh hướng chặt đầu, vì cách tùy ý rằng các hình ảnh được quét trên web không phải hình vuông được nhập vào bộ dữ liệu khổng lồ cung cấp năng lượng cho các hệ thống như DALL-E 2, Stable Diffusion và MidJourney:

Các mô hình khuếch tán tiềm ẩn, giống như tất cả các mô hình thị giác máy tính, yêu cầu đầu vào có định dạng vuông; nhưng quá trình quét web tổng hợp cung cấp dữ liệu LAION5B không cung cấp 'tính năng bổ sung sang trọng' như khả năng nhận dạng và lấy nét trên khuôn mặt (hoặc bất kỳ thứ gì khác) và cắt bớt hình ảnh một cách khá thô bạo thay vì đệm chúng ra (điều này sẽ giữ lại toàn bộ nguồn hình ảnh, nhưng ở độ phân giải thấp hơn). Sau khi được huấn luyện, những 'cây trồng' này sẽ được chuẩn hóa và rất thường xuyên xảy ra ở đầu ra của các hệ thống khuếch tán tiềm ẩn như Khuếch tán ổn định. Nguồn: https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac và Khuếch tán ổn định.
DE-FAKE nhằm mục đích không phụ thuộc vào thuật toán, một mục tiêu đã ấp ủ từ lâu của các nhà nghiên cứu chống deepfake bộ mã hóa tự động và, ngay bây giờ, là một mục tiêu khá khả thi đối với các hệ thống LD.
Kiến trúc sử dụng Đào tạo trước hình ảnh-ngôn ngữ tương phản của OpenAI (CLIP) thư viện đa phương thức – một yếu tố thiết yếu trong Khuếch tán ổn định và nhanh chóng trở thành trung tâm của làn sóng hệ thống tổng hợp hình ảnh/video mới – như một cách để trích xuất các phần nhúng từ hình ảnh LD 'giả mạo' và huấn luyện bộ phân loại trên các mẫu và lớp quan sát được.
Trong một kịch bản 'hộp đen' hơn, trong đó các khối PNG chứa thông tin về quá trình tạo từ lâu đã bị loại bỏ bởi quá trình tải lên và vì các lý do khác, các nhà nghiên cứu sử dụng Salesforce khung BLIP (cũng là thành phần trong ít nhất một phân phối của Khuếch tán Ổn định) để thăm dò 'một cách mù quáng' các hình ảnh về cấu trúc ngữ nghĩa có khả năng xảy ra của các lời nhắc đã tạo ra chúng.

Các nhà nghiên cứu đã sử dụng Khuếch tán ổn định, Khuếch tán tiềm ẩn (bản thân nó là một sản phẩm riêng biệt), GLIDE và DALL-E 2 để đưa vào bộ dữ liệu đào tạo và thử nghiệm tận dụng MSCOCO và Flickr30k.
Thông thường, chúng tôi sẽ xem xét khá toàn diện kết quả thí nghiệm của các nhà nghiên cứu về một khuôn khổ mới; nhưng trên thực tế, những phát hiện của DE-FAKE dường như hữu ích hơn với tư cách là chuẩn mực trong tương lai cho các lần lặp lại sau này và các dự án tương tự, thay vì là thước đo có ý nghĩa về thành công của dự án, khi xem xét môi trường không ổn định mà nó đang hoạt động và hệ thống mà nó đang hoạt động. đang cạnh tranh trong các thử nghiệm của bài báo đã gần ba năm tuổi - từ khi bối cảnh tổng hợp hình ảnh mới thực sự ra đời.

Hai hình ảnh ngoài cùng bên trái: khuôn khổ trước đó 'bị thách thức', bắt nguồn từ năm 2019, có thể dự đoán là kém hiệu quả hơn so với DE-FAKE (hai hình ảnh ngoài cùng bên phải) trên bốn hệ thống LD được thử nghiệm.
Kết quả của nhóm cực kỳ tích cực vì hai lý do: có rất ít công việc trước đó để so sánh nó (và không có công việc nào đưa ra sự so sánh công bằng, tức là chỉ bao gồm mười hai tuần kể từ khi Khuếch tán ổn định được phát hành thành nguồn mở).
Thứ hai, như đã đề cập ở trên, mặc dù lĩnh vực tổng hợp hình ảnh LD đang phát triển với tốc độ cấp số nhân, nhưng nội dung đầu ra của các dịch vụ hiện tại sẽ tự đánh dấu bản thân một cách hiệu quả bằng cách loại bỏ các thiếu sót và độ lệch tâm về cấu trúc (và rất dễ đoán) của chính nó – nhiều trong số đó có khả năng được khắc phục, ít nhất là trong trường hợp Khuếch tán ổn định, bằng cách phát hành điểm kiểm tra 1.5 hoạt động tốt hơn (tức là mô hình được đào tạo 4GB cung cấp năng lượng cho hệ thống).
Đồng thời, Ổn định đã chỉ ra rằng nó có lộ trình rõ ràng cho V2 và V3 của hệ thống. Với các sự kiện gây chú ý trong ba tháng qua, bất kỳ sự trì trệ nào của công ty đối với OpenAI và những người chơi cạnh tranh khác trong không gian tổng hợp hình ảnh có thể đã bị bốc hơi, có nghĩa là chúng ta cũng có thể mong đợi một tốc độ tiến bộ nhanh tương tự trong lĩnh vực tổng hợp hình ảnh. không gian tổng hợp hình ảnh nguồn đóng.
Xuất bản lần đầu vào ngày 14 tháng 2022 năm XNUMX.















