Trí tuệ nhân tạo
Làm thế nào Stable Diffusion có thể phát triển thành một sản phẩm tiêu dùng chính thống

Một cách iron, Stable Diffusion, khuôn khổ tổng hợp hình ảnh AI mới đã làm thế giới sửng sốt, không phải là ổn định hay thực sự ‘phân tán’ – ít nhất, chưa phải lúc này.
Phạm vi đầy đủ của các khả năng của hệ thống được phân bố trên một loạt các gói thay đổi liên tục từ một số nhà phát triển hoảng loạn trao đổi thông tin và lý thuyết mới nhất trong các cuộc trò chuyện đa dạng trên Discord – và đa số các thủ tục cài đặt cho các gói họ đang tạo hoặc sửa đổi rất xa so với ‘cắm và chơi’.
Thay vào đó, chúng thường đòi hỏi cài đặt dòng lệnh hoặc được điều khiển bởi BAT thông qua GIT, Conda, Python, Miniconda và các khuôn khổ phát triển tiên tiến khác – các gói phần mềm hiếm gặp trong số người tiêu dùng chung đến mức việc cài đặt của chúng thường được đánh dấu bởi các nhà cung cấp phần mềm chống vi-rút và chống malware là bằng chứng của một hệ thống bị xâm phạm.

Chỉ một phần nhỏ của các giai đoạn trong quá trình cài đặt Stable Diffusion tiêu chuẩn hiện yêu cầu. Nhiều phân phối cũng yêu cầu các phiên bản cụ thể của Python, có thể xung đột với các phiên bản đã cài đặt trên máy của người dùng – mặc dù điều này có thể được khắc phục bằng cách cài đặt dựa trên Docker và, ở một mức độ nhất định, thông qua việc sử dụng môi trường Conda.
Các chuỗi tin nhắn trong cả cộng đồng Stable Diffusion SFW và NSFW đều tràn ngập các mẹo và thủ thuật liên quan đến việc hack các tập lệnh Python và cài đặt tiêu chuẩn, để kích hoạt chức năng cải tiến hoặc giải quyết các lỗi phụ thuộc thường xuyên và một loạt các vấn đề khác.
Điều này khiến người tiêu dùng trung bình, quan tâm đến tạo ra hình ảnh tuyệt vời từ các lời nhắc văn bản, gần như hoàn toàn phụ thuộc vào số lượng ngày càng tăng của các giao diện web API được tiền hóa, hầu hết trong số đó cung cấp số lượng hình ảnh được tạo miễn phí tối thiểu trước khi yêu cầu mua token.
Ngoài ra, gần như tất cả các dịch vụ dựa trên web này từ chối xuất ra nội dung NSFW (nhiều trong số đó có thể liên quan đến các chủ đề chung không phải khiêu dâm, chẳng hạn như ‘chiến tranh’) giúp Stable Diffusion khác biệt với các dịch vụ được kiểm duyệt của DALL-E 2 của OpenAI.
‘Photoshop cho Stable Diffusion’
Được thôi thúc bởi những hình ảnh tuyệt vời, gợi cảm hoặc siêu thực mà hàng ngày lấp đầy thẻ hashtag #stablediffusion trên Twitter, điều mà thế giới rộng lớn hơn đang chờ đợi có lẽ là ‘Photoshop cho Stable Diffusion’ – một ứng dụng có thể cài đặt trên nhiều nền tảng, kết hợp các chức năng mạnh mẽ và tốt nhất của kiến trúc Stability.ai, cũng như các đổi mới thông minh của cộng đồng phát triển SD đang nổi lên, mà không có các cửa sổ dòng lệnh trôi nổi, các quy trình cài đặt và cập nhật thay đổi liên tục và các tính năng bị thiếu.
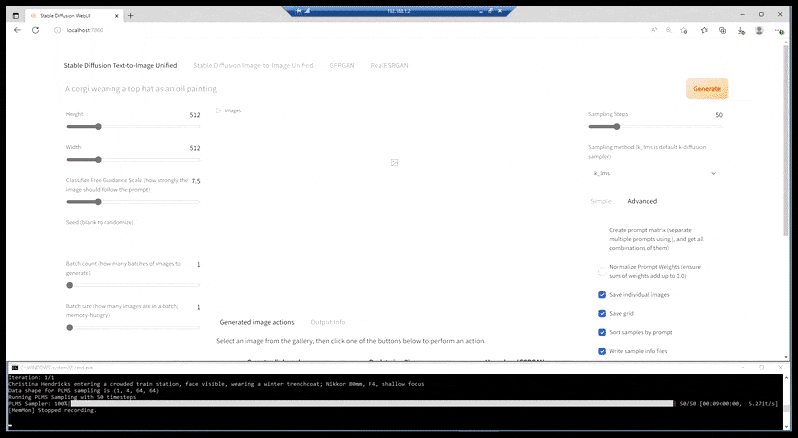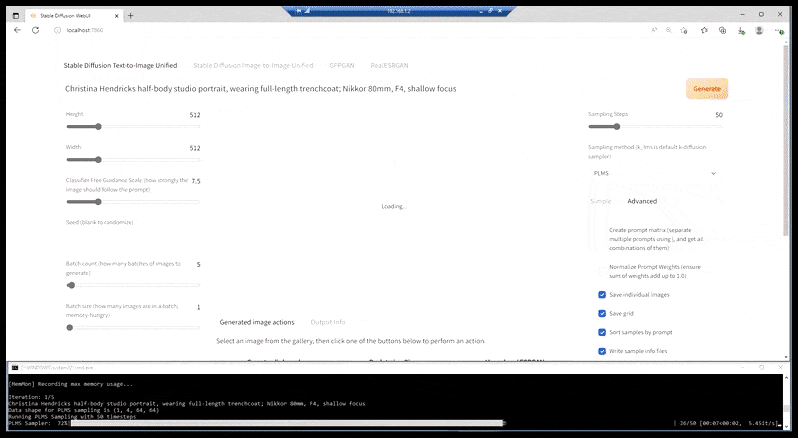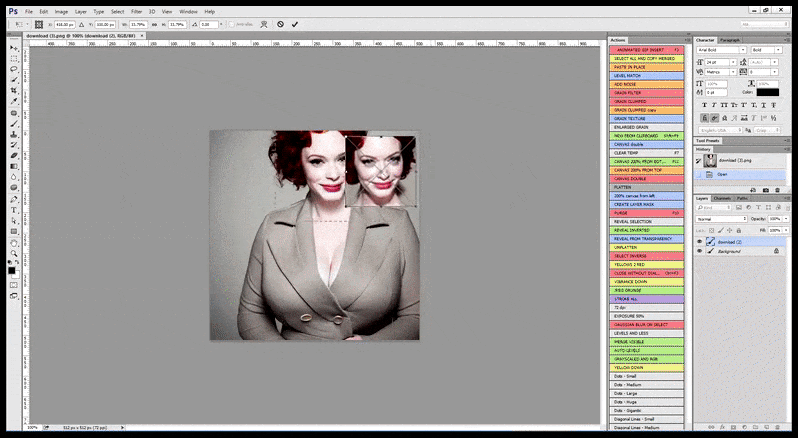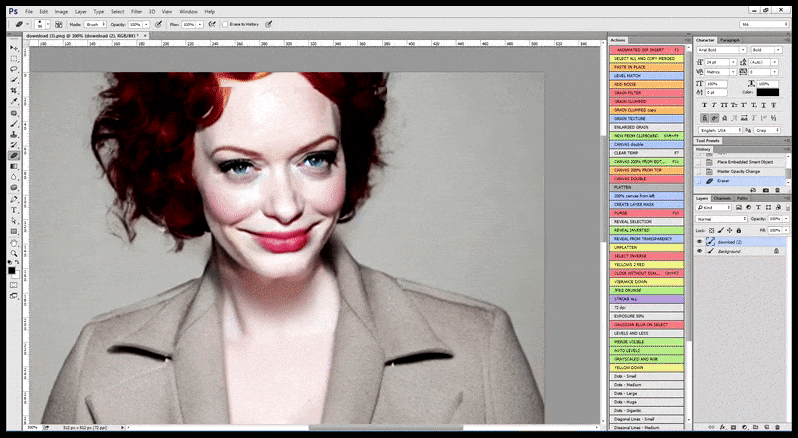
Điều chúng ta hiện có, trong hầu hết các cài đặt có khả năng hơn, là một trang web tinh tế bị kẹp giữa một cửa sổ dòng lệnh bị tách ra, và URL của nó là một cổng localhost:

Tương tự như các ứng dụng tổng hợp CLI như FaceSwap, và DeepFaceLab dựa trên BAT, cài đặt ‘prepack’ của Stable Diffusion cho thấy gốc gác dòng lệnh của nó, với giao diện được truy cập qua một cổng localhost (xem phần trên của hình ảnh trên) giao tiếp với chức năng Stable Diffusion dựa trên CLI.
Không có nghi ngờ, một ứng dụng tinh gọn hơn đang đến. Hiện đã có một số ứng dụng tích hợp dựa trên Patreon có thể được tải xuống, chẳng hạn như GRisk và NMKD (xem hình ảnh dưới đây) – nhưng không có ứng dụng nào trong số đó kết hợp đầy đủ các tính năng mà một số cài đặt Stable Diffusion tiên tiến và ít dễ tiếp cận hơn có thể cung cấp.

Các gói Patreon sớm của Stable Diffusion, được ‘app hóa’ một cách nhẹ nhàng. NMKD là gói đầu tiên tích hợp đầu ra CLI trực tiếp vào GUI.
Hãy cùng xem một ứng dụng Stable Diffusion được đánh bóng và tích hợp hơn có thể trông như thế nào – và những thách thức nào nó có thể gặp phải.
Quy định Pháp lý cho Ứng dụng Stable Diffusion Thương mại Toàn diện
Yếu tố NSFW
Mã nguồn Stable Diffusion đã được phát hành dưới giấy phép cực kỳ permissive không cấm các bản tái triển khai thương mại và các tác phẩm phái sinh được xây dựng rộng rãi từ mã nguồn.
Ngoài số lượng ngày càng tăng của các bản xây dựng Stable Diffusion dựa trên Patreon, cũng như số lượng lớn các plugin ứng dụng đang được phát triển cho Figma, Krita, Photoshop, GIMP và Blender (trong số những người khác), không có lý do thực tế nào khiến một nhà phát triển phần mềm có vốn đầu tư mạnh không thể phát triển một ứng dụng Stable Diffusion tinh tế và mạnh mẽ hơn.
Từ góc độ thị trường, có mọi lý do để tin rằng một số sáng kiến như vậy đã được tiến hành mạnh mẽ.
Tại đây, những nỗ lực như vậy ngay lập tức đối mặt với bài toán về việc liệu ứng dụng có cho phép bộ lọc NSFW bản địa của Stable Diffusion (một mảnh mã), để được tắt.
‘Chôn’ Công tắc NSFW
Mặc dù giấy phép mã nguồn mở của Stability.ai cho Stable Diffusion bao gồm một danh sách các ứng dụng có thể không được sử dụng (có thể bao gồm nội dung khiêu dâm và deepfake), cách duy nhất một nhà cung cấp có thể hiệu quả cấm sử dụng như vậy sẽ là biên dịch bộ lọc NSFW thành một tệp thực thi không rõ nguồn gốc thay vì một tham số trong tệp Python, hoặc áp dụng một phép so sánh tổng kiểm tra trên tệp Python hoặc tệp DLL chứa chỉ thị NSFW, để các bản kết xuất không thể xảy ra nếu người dùng thay đổi cài đặt này.
Điều này sẽ để lại ứng dụng được cho là ‘thiến’ theo cách tương tự như DALL-E 2 hiện tại, giảm sức hấp dẫn thương mại của nó. Ngoài ra, không thể tránh khỏi, các phiên bản ‘được chỉnh sửa’ của các thành phần này (hoặc các yếu tố thời gian chạy Python ban đầu hoặc tệp DLL được biên dịch, như hiện đang được sử dụng trong dòng công cụ tăng cường hình ảnh AI của Topaz) sẽ có khả năng xuất hiện trong cộng đồng torrent / hacking để mở khóa các hạn chế như vậy, chỉ bằng cách thay thế các yếu tố cản trở và vô hiệu hóa bất kỳ yêu cầu tổng kiểm tra nào.
Cuối cùng, nhà cung cấp có thể chọn đơn giản lặp lại cảnh báo của Stability.ai về việc lạm dụng được đặc trưng bởi lần chạy đầu tiên của nhiều phân phối Stable Diffusion hiện tại.
Tuy nhiên, các nhà phát triển mã nguồn mở nhỏ hiện đang sử dụng các tuyên bố từ chối trách nhiệm theo cách này có rất ít để mất so với một công ty phần mềm đã đầu tư đáng kể thời gian và tiền bạc vào việc làm cho Stable Diffusion trở nên toàn diện và dễ tiếp cận – điều này mời gọi sự xem xét sâu sắc hơn.
Trách nhiệm pháp lý về Deepfake
Như chúng tôi đã gần đây lưu ý, cơ sở dữ liệu LAION-aesthetics, một phần của 4,2 tỷ hình ảnh mà các mô hình Stable Diffusion đang được đào tạo, chứa một số lượng lớn hình ảnh của người nổi tiếng, cho phép người dùng tạo ra deepfake, bao gồm cả deepfake khiêu dâm của người nổi tiếng.

Từ bài viết gần đây của chúng tôi, bốn giai đoạn của Jennifer Connelly trong bốn thập kỷ sự nghiệp của cô, được suy ra từ Stable Diffusion.
Đây là một vấn đề riêng biệt và gây tranh cãi hơn so với việc tạo ra ‘trừu tượng’ khiêu dâm (thường không mô tả ‘người thực’), mà các hình ảnh như vậy được suy ra từ nhiều ảnh thực trong tài liệu đào tạo.
Kể từ khi ngày càng nhiều bang của Mỹ và quốc gia đang phát triển, hoặc đã đưa ra, luật chống lại deepfake khiêu dâm, khả năng của Stable Diffusion trong việc tạo ra deepfake của người nổi tiếng có thể có nghĩa là một ứng dụng thương mại có thể không được kiểm duyệt hoàn toàn (tức là có thể tạo ra tài liệu khiêu dâm) có thể vẫn cần một số khả năng để lọc các khuôn mặt của người nổi tiếng.
Một phương pháp sẽ là cung cấp một ‘danh sách đen’ có thể được người dùng tùy chỉnh, bao gồm các thuật ngữ sẽ không được chấp nhận trong một lời nhắc văn bản, liên quan đến tên của người nổi tiếng và các nhân vật hư cấu mà họ có thể liên kết. Giả sử rằng những cài đặt như vậy sẽ cần được đưa vào nhiều ngôn ngữ hơn chỉ là tiếng Anh, vì dữ liệu ban đầu có các ngôn ngữ khác. Một cách tiếp cận khác có thể là tích hợp các hệ thống nhận dạng người nổi tiếng như những hệ thống được phát triển bởi Clarifai.
Có thể cần thiết cho các nhà sản xuất phần mềm để tích hợp các phương pháp như vậy, có thể ban đầu bị tắt, vì điều này có thể giúp ngăn chặn một ứng dụng độc lập Stable Diffusion từ việc tạo ra khuôn mặt của người nổi tiếng, trong khi chờ đợi các luật mới có thể khiến chức năng như vậy trở nên bất hợp pháp.
Một lần nữa, tuy nhiên, chức năng như vậy có thể sẽ bị giải mã và đảo ngược bởi các bên quan tâm; tuy nhiên, nhà sản xuất phần mềm có thể, trong trường hợp đó, tuyên bố rằng đây về cơ bản là hành vi phá hoại không được ủy quyền – miễn là việc đảo ngược kỹ thuật như vậy không được thực hiện một cách quá dễ dàng.
Các Tính năng có thể được Bao gồm
Các chức năng cốt lõi trong bất kỳ phân phối nào của Stable Diffusion sẽ được mong đợi từ bất kỳ ứng dụng thương mại nào có vốn đầu tư mạnh. Những tính năng này bao gồm khả năng sử dụng lời nhắc văn bản để tạo ra hình ảnh phù hợp (văn bản sang hình ảnh); khả năng sử dụng các bản phác thảo hoặc hình ảnh khác làm hướng dẫn cho hình ảnh mới được tạo (hình ảnh sang hình ảnh); phương tiện để điều chỉnh mức độ ‘sáng tạo’ mà hệ thống được hướng dẫn; cách để cân bằng thời gian kết xuất với chất lượng; và các ‘cơ bản’ khác, chẳng hạn như lưu trữ hình ảnh / lời nhắc tự động tùy chọn và tăng tỷ lệ phân giải thường xuyên thông qua RealESRGAN, và ít nhất là ‘sửa mặt’ cơ bản với GFPGAN hoặc CodeFormer.
Đó là một ‘cài đặt vanilla’. Hãy cùng xem một số tính năng tiên tiến hơn đang được phát triển hoặc mở rộng, có thể được tích hợp vào một ứng dụng ‘truyền thống’ đầy đủ của Stable Diffusion.
Đông lạnh Stochastic
Ngay cả khi bạn tái sử dụng một hạt giống từ một bản kết xuất thành công trước đó, thật khó khăn để Stable Diffusion lặp lại chính xác một biến đổi nếu bất kỳ phần nào của lời nhắc hoặc hình ảnh nguồn (hoặc cả hai) được thay đổi cho một bản kết xuất sau.
Đây là một vấn đề nếu bạn muốn sử dụng EbSynth để áp dụng các biến đổi của Stable Diffusion lên video thực trong một cách nhất quán về thời gian – mặc dù kỹ thuật này có thể rất hiệu quả cho các cảnh quay đơn giản:

Chuyển động hạn chế có thể khiến EbSynth trở thành một phương tiện hiệu quả để chuyển đổi các biến đổi của Stable Diffusion thành video thực tế. Nguồn: https://streamable.com/u0pgzd
EbSynth hoạt động bằng cách ngoại suy một số lượng nhỏ ‘bản thay đổi’ khung hình thành video đã được kết xuất thành một loạt tệp hình ảnh (và có thể được lắp ráp lại thành video).

Trong ví dụ này từ trang web EbSynth, một số khung hình từ video đã được vẽ theo cách nghệ thuật. EbSynth sử dụng các khung hình này làm hướng dẫn phong cách để thay đổi toàn bộ video để nó khớp với phong cách được vẽ. Nguồn: https://www.youtube.com/embed/eghGQtQhY38
Trong ví dụ dưới đây, có gần như không có chuyển động nào từ giáo viên yoga vàng thật (bên trái), Stable Diffusion vẫn gặp khó khăn trong việc duy trì một khuôn mặt nhất quán, vì ba hình ảnh được biến đổi thành ‘khung hình chính’ không hoàn toàn giống nhau, ngay cả khi chúng đều chia sẻ cùng một hạt giống số.

Ở đây, ngay cả khi sử dụng cùng một lời nhắc và hạt giống trên tất cả ba biến đổi, và rất ít thay đổi giữa các khung hình nguồn, các cơ bắp của cơ thể thay đổi về kích thước và hình dạng, nhưng quan trọng hơn, khuôn mặt không nhất quán, cản trở sự nhất quán về thời gian trong một bản kết xuất EbSynth tiềm năng.
Mặc dù video SD / EbSynth dưới đây rất sáng tạo, nơi ngón tay của người dùng đã được biến thành (tương ứng) một cặp chân mặc quần và một con vịt, sự không nhất quán của quần áo điển hình cho vấn đề mà Stable Diffusion gặp phải trong việc duy trì sự nhất quán trên các khung hình chính khác nhau, ngay cả khi các khung hình nguồn tương tự nhau và hạt giống nhất quán.

Ngón tay của một người trở thành một người đi và một con vịt, thông qua Stable Diffusion và EbSynth. Nguồn: https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/
Người dùng đã tạo video này bình luận rằng biến đổi vịt, có thể là biến đổi hiệu quả hơn, nếu ít nổi bật và nguyên bản, chỉ yêu cầu một khung hình biến đổi duy nhất, trong khi cần phải kết xuất 50 hình ảnh Stable Diffusion để tạo ra quần áo đi, hiển thị sự không nhất quán về thời gian nhiều hơn. Người dùng cũng lưu ý rằng cần phải thử lại năm lần để đạt được sự nhất quán cho mỗi một trong 50 khung hình chính.
Do đó, sẽ rất có lợi cho một ứng dụng Stable Diffusion toàn diện nếu cung cấp chức năng để bảo tồn các đặc điểm tối đa trên các khung hình chính.
Một khả năng là ứng dụng cho phép người dùng ‘đông lạnh’ mã hóa stochastical cho biến đổi trên mỗi khung hình, điều mà hiện tại chỉ có thể đạt được bằng cách sửa đổi mã nguồn theo cách thủ công. Như ví dụ dưới đây cho thấy, điều này giúp duy trì sự nhất quán về thời gian, mặc dù nó chắc chắn không giải quyết được vấn đề:

Một người dùng Reddit đã biến đổi cảnh quay webcam của mình thành những người nổi tiếng khác bằng cách không chỉ giữ hạt giống (mà bất kỳ triển khai nào của Stable Diffusion đều có thể làm được), mà còn bằng cách đảm bảo rằng tham số stochastic_encode() giống nhau trong mỗi biến đổi. Điều này đã được thực hiện bằng cách sửa đổi mã, nhưng có thể dễ dàng trở thành một công tắc có thể truy cập được bởi người dùng. Rõ ràng, tuy nhiên, nó không giải quyết tất cả các vấn đề về thời gian. Nguồn: https://old.reddit.com/r/StableDiffusion/comments/wyeoqq/turning_img2img_into_vid2vid/
Đảo ngược Văn bản Dựa trên Đám mây
Một giải pháp tốt hơn để tạo ra các nhân vật và đối tượng nhất quán về thời gian là ‘nướng’ chúng vào một Đảo ngược Văn bản – một tệp 5KB có thể được đào tạo trong vài giờ dựa trên chỉ năm hình ảnh được chú thích, có thể được triệu tập bằng một lời nhắc đặc biệt ‘*’, cho phép, ví dụ, một sự xuất hiện nhất quán của các nhân vật mới để bao gồm trong một câu chuyện.

Các hình ảnh được liên kết với các thẻ phù hợp có thể được chuyển đổi thành các thực thể riêng biệt thông qua Đảo ngược Văn bản, và được triệu tập mà không có sự mơ hồ, và trong ngữ cảnh và phong cách phù hợp, bởi các từ khóa đặc biệt. Nguồn: https://huggingface.co/docs/diffusers/training/text_inversion
Các Đảo ngược Văn bản là các tệp phụ của mô hình được đào tạo đầy đủ mà Stable Diffusion sử dụng, và về cơ bản được ‘trượt’ vào quá trình nhắc / triệu tập, để chúng có thể tham gia vào các cảnh được tạo ra từ mô hình, và được hưởng lợi từ cơ sở dữ liệu khổng lồ về các đối tượng, phong cách, môi trường và tương tác của mô hình.
Tuy nhiên, mặc dù một Đảo ngược Văn bản không mất nhiều thời gian để đào tạo, nó đòi hỏi một lượng VRAM lớn; theo các hướng dẫn hiện tại, nằm trong khoảng từ 12 đến 20, thậm chí 40GB.
Vì hầu hết người dùng thông thường không có khả năng có loại GPU mạnh như vậy, các dịch vụ đám mây đã xuất hiện để xử lý hoạt động, bao gồm cả phiên bản Hugging Face. Mặc dù có các triển khai Colab của Google có thể tạo ra các đảo ngược văn bản cho Stable Diffusion, các yêu cầu về VRAM và thời gian có thể khiến chúng trở nên thách thức đối với người dùng Colab miễn phí.
Đối với một ứng dụng Stable Diffusion đầy đủ và có vốn đầu tư mạnh, việc chuyển quá trình nặng này sang máy chủ đám mây của công ty dường như là một chiến lược kiếm tiền rõ ràng (giả sử rằng một ứng dụng Stable Diffusion miễn phí hoặc chi phí thấp được thấm nhuần bởi các chức năng không miễn phí như vậy, điều này có vẻ có khả năng trong nhiều ứng dụng sẽ xuất hiện từ công nghệ này trong 6-9 tháng tới).
Ngoài ra, quá trình phức tạp của việc chú thích và định dạng hình ảnh và văn bản được gửi có thể được tự động hóa trong một môi trường tích hợp. Yếu tố ‘nghiện’ tiềm năng của việc tạo ra các yếu tố duy nhất có thể khám phá và tương tác với thế giới rộng lớn của Stable Diffusion dường như có khả năng gây nghiện, cả cho những người đam mê chung và người dùng trẻ.
Trọng số Lời nhắc Linh hoạt
Có nhiều triển khai hiện tại cho phép người dùng gán trọng số cao hơn cho một phần của lời nhắc văn bản dài, nhưng công cụ này thay đổi khá nhiều giữa chúng, và thường khó sử dụng hoặc không trực quan.
Fork Stable Diffusion rất phổ biến của AUTOMATIC1111, ví dụ, có thể giảm hoặc tăng giá trị của một từ lời nhắc bằng cách đặt nó trong các dấu ngoặc đơn (để giảm thiểu) hoặc nhiều dấu ngoặc (để giảm thiểu) hoặc dấu ngoặc vuông để nhấn mạnh thêm.

Dấu ngoặc vuông và / hoặc dấu ngoặc đơn có thể biến bữa sáng của bạn trong phiên bản này của trọng số lời nhắc Stable Diffusion, nhưng đó là một cơn ác mộng về cholesterol dù sao.
Các phiên bản khác của Stable Diffusion sử dụng dấu chấm than để nhấn mạnh, trong khi các phiên bản linh hoạt nhất cho phép người dùng gán trọng số cho từng từ trong lời nhắc thông qua GUI.
Hệ thống cũng nên cho phép trọng số lời nhắc âm – không chỉ cho những người hâm mộ kinh dị, mà vì có thể có những điều bí ẩn ít gây sốc và thú vị hơn trong không gian tiềm ẩn của Stable Diffusion mà ngôn ngữ hạn chế của chúng ta không thể triệu tập.
Outpainting
Ngay sau khi Stable Diffusion được mở mã nguồn, OpenAI đã cố gắng – phần lớn là vô ích – để giành lại một số ánh hào quang của DALL-E 2 bằng cách đưa ra ‘outpainting’, cho phép người dùng mở rộng hình ảnh vượt ra ngoài ranh giới của nó với logic ngữ nghĩa và tính hợp lý về mặt thị giác.
Tự nhiên, điều này đã được thực hiện trong các hình thức khác nhau cho Stable Diffusion, cũng như trong Krita, và chắc chắn nên được bao gồm trong một phiên bản toàn diện, kiểu Photoshop của Stable Diffusion.
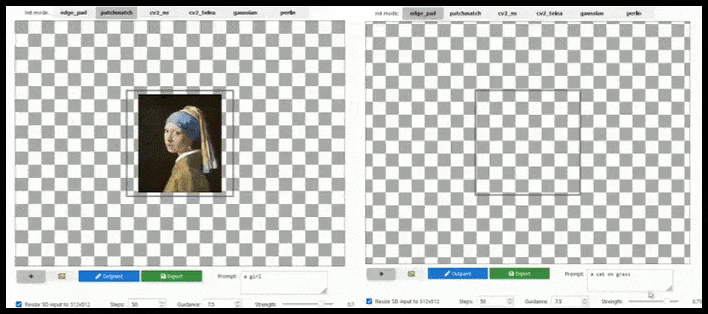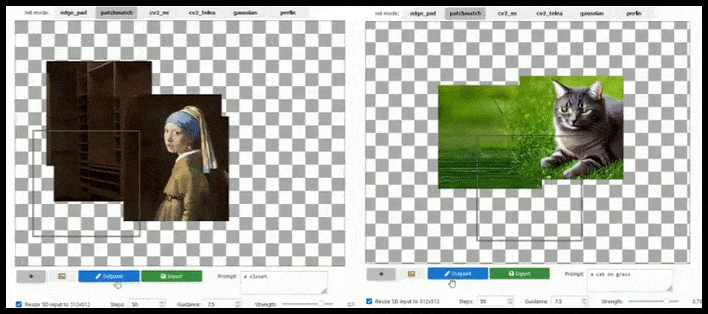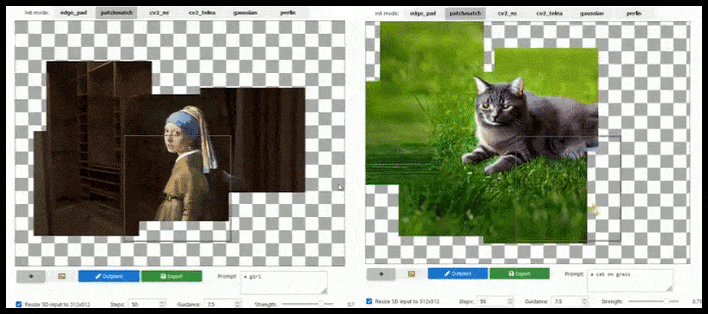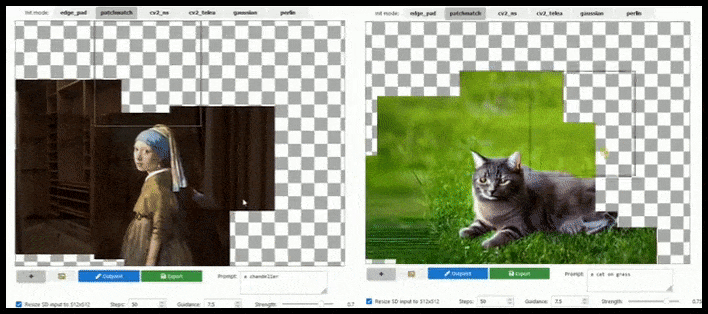
Tăng tỷ lệ phân giải dựa trên ô có thể mở rộng một bản kết xuất 512×512 tiêu chuẩn gần như vô hạn, miễn là lời nhắc, hình ảnh hiện có và logic ngữ nghĩa cho phép. Nguồn: https://github.com/lkwq007/stablediffusion-infinity
Vì Stable Diffusion được đào tạo trên hình ảnh 512x512px (và vì một số lý do khác), nó thường cắt đầu (hoặc các bộ phận cơ thể quan trọng khác) của các đối tượng người, ngay cả khi lời nhắc rõ ràng chỉ ra ‘tập trung vào đầu’, v.v..

Các ví dụ điển hình về ‘cắt đầu’ của Stable Diffusion; nhưng outpainting có thể đưa George trở lại vào bức tranh.
Bất kỳ triển khai outpainting nào của loại được minh họa trong hình ảnh động trên (được dựa độc quyền trên các thư viện Unix, nhưng nên có thể được nhân bản trên Windows) cũng nên được công cụ hóa như một phương tiện chữa cháy một cú nhấp / lời nhắc để khắc phục vấn đề này.
Hiện tại, một số người dùng mở rộng canvas của các hình ảnh ‘cắt đầu’ lên, lấp đầy khu vực đầu một cách thô và sử dụng img2img để hoàn thành bản kết xuất bị hỏng.
Mặt nạ Hiệu quả hiểu bối cảnh
Mặt nạ có thể là một vấn đề cực kỳ khó đoán trong Stable Diffusion, tùy thuộc vào fork hoặc phiên bản cụ thể.
Thường xuyên, nơi mà mặt nạ được áp dụng một cách nhất quán, khu vực được chỉ định thường bị sơn lại với nội dung không tính đến toàn bộ ngữ cảnh của hình ảnh.
Trong một lần, tôi đã mặt nạ các mống mắt của một hình ảnh khuôn mặt và cung cấp lời nhắc ‘mắt xanh’ như một lời nhắc mặt nạ – chỉ để phát hiện ra rằng tôi dường như đang nhìn qua hai mắt người được cắt ra tại một hình ảnh xa về một con sói có vẻ ngoài không quen thuộc. Tôi nghĩ mình may mắn khi đó không phải là Frank Sinatra.
Chỉnh sửa ngữ nghĩa cũng có thể được thực hiện bằng cách xác định nhiễu đã tạo ra hình ảnh ban đầu, cho phép người dùng giải quyết các yếu tố cấu trúc cụ thể trong một bản kết xuất mà không can thiệp vào phần còn lại của hình ảnh:

Thay đổi một yếu tố trong hình ảnh mà không cần mặt nạ truyền thống và không thay đổi nội dung liền kề, bằng cách xác định nhiễu đã tạo ra hình ảnh ban đầu và giải quyết các phần của nó đã góp phần vào khu vực mục tiêu. Nguồn: https://old.reddit.com/r/StableDiffusion/comments/xboy90/a_better_way_of_doing_img2img_by_finding_the/
Phương pháp này dựa trên mẫu K-Diffusion.
Bộ lọc Ngữ nghĩa cho sai lầm Vật lý
Như chúng tôi đã đề cập trước đó, Stable Diffusion có thể thường xuyên thêm hoặc bớt chân, chủ yếu do vấn đề dữ liệu và thiếu sót trong các chú thích đi kèm với các hình ảnh đã đào tạo nó.

Giống như đứa trẻ nghịch ngợm đó đã đưa lưỡi ra trong bức ảnh tập thể của trường, những tội ác sinh học của Stable Diffusion không phải lúc nào cũng rõ ràng ngay lập tức, và bạn có thể đã đăng ảnh đại diện AI mới nhất của mình lên Instagram trước khi bạn nhận thấy bàn tay hoặc chân bị tan chảy.
Nó rất khó để sửa các lỗi như vậy đến mức sẽ rất hữu ích nếu một ứng dụng Stable Diffusion đầy đủ có chứa một số hệ thống nhận dạng giải phẫu học sử dụng phân đoạn ngữ nghĩa để tính toán liệu hình ảnh đến có các khiếm khuyết giải phẫu nghiêm trọng (như trong hình ảnh trên) hay không, và loại bỏ nó để lấy bản kết xuất mới trước khi trình bày nó cho người dùng.

Tất nhiên, bạn có thể muốn kết xuất nữ thần Kali, hoặc Tiến sĩ Bát, hoặc thậm chí cứu một phần không bị ảnh hưởng của một hình ảnh bị ảnh hưởng bởi chân, vì vậy tính năng này nên là một tùy chọn bật / tắt.
Nếu người dùng có thể chấp nhận khía cạnh telemetry, những sai lầm như vậy thậm chí có thể được truyền tải một cách vô danh trong một nỗ lực học liên bang tập thể có thể giúp các mô hình trong tương lai cải thiện sự hiểu biết của chúng về logic giải phẫu.
Tự động Cải thiện Khuôn mặt Dựa trên LAION
Như tôi đã lưu ý trong bài viết trước của tôi về ba điều Stable Diffusion có thể giải quyết trong tương lai, nó không nên để lại cho bất kỳ phiên bản nào của GFPGAN để cố gắng ‘cải thiện’ các khuôn mặt được kết xuất trong các bản kết xuất lần đầu.
Các ‘cải tiến’ của GFPGAN rất chung chung, thường xuyên làm suy yếu bản dạng của cá nhân được mô tả, và hoạt động chỉ trên một khuôn mặt đã được kết xuất kém, vì nó đã nhận được không nhiều thời gian xử lý hoặc sự chú ý hơn bất kỳ phần nào khác của hình ảnh.
Do đó, một chương trình chuyên nghiệp cho Stable Diffusion nên có khả năng nhận dạng khuôn mặt (với một thư viện tiêu chuẩn và tương đối nhẹ như YOLO), áp dụng toàn bộ sức mạnh của GPU có sẵn để kết xuất lại khuôn mặt, và sau đó trộn khuôn mặt được cải thiện vào bản kết xuất toàn bộ ngữ cảnh ban đầu, hoặc lưu nó riêng để tái tạo thủ công. Hiện tại, đây là một hoạt động khá ‘tay’.
Trong trường hợp Stable Diffusion đã được đào tạo trên số lượng hình ảnh đủ của một người nổi tiếng, có thể tập trung toàn bộ khả năng của GPU vào một bản kết xuất sau của khuôn mặt của hình ảnh được kết xuất, điều này thường là một cải tiến đáng chú ý – và, không giống như GFPGAN, dựa trên dữ liệu được đào tạo LAION, chứ không chỉ điều chỉnh các pixel được kết xuất.
Tìm kiếm LAION trong Ứng dụng
Kể từ khi người dùng bắt đầu nhận ra rằng tìm kiếm cơ sở dữ liệu LAION để khám phá các khái niệm, người và chủ đề có thể chứng minh là một trợ giúp cho việc sử dụng Stable Diffusion tốt hơn, một số trình khám phá LAION trực tuyến đã được tạo, bao gồm haveibeentrained.com.

Chức năng tìm kiếm tại haveibeentrained.com cho phép người dùng khám phá các hình ảnh cung cấp năng lượng cho Stable Diffusion, và khám phá xem các đối tượng, người hoặc ý tưởng mà họ có thể muốn triệu tập từ hệ thống có khả năng được đào tạo vào nó hay không. Các hệ thống như vậy cũng hữu ích để khám phá các thực thể liền kề, chẳng hạn như cách các người nổi tiếng được nhóm lại, hoặc ‘ý tưởng tiếp theo’ dẫn từ ý tưởng hiện tại. Nguồn: https://haveibeentrained.com/?search_text=bowl%20of%20fruit
Mặc dù các cơ sở dữ liệu web này thường tiết lộ một số thẻ đi kèm với hình ảnh, quá trình tổng quát hóa diễn ra trong quá trình đào tạo mô hình có nghĩa là không có khả năng một hình ảnh cụ thể nào có thể được triệu tập bằng cách sử dụng thẻ của nó làm lời nhắc.
Ngoài ra, việc loại bỏ ‘từ dừng’ và thực hành stemming và lemmatization trong Xử lý Ngôn ngữ Tự nhiên có nghĩa là nhiều cụm từ được hiển thị đã bị chia nhỏ hoặc bị loại bỏ trước khi được đào tạo vào Stable Diffusion.
Tuy nhiên, cách các nhóm thẩm mỹ liên kết trong các giao diện này có thể dạy người dùng cuối rất nhiều về logic (hoặc có thể là ‘tính cách’) của Stable Diffusion, và chứng minh là một trợ giúp cho việc tạo ra hình ảnh tốt hơn.
Kết luận
Có nhiều tính năng khác mà tôi muốn thấy trong một triển khai bản địa trên máy tính để bàn của Stable Diffusion, chẳng hạn như phân tích hình ảnh bản địa dựa trên CLIP, cho phép người dùng suy ra các cụm từ và từ mà hệ thống sẽ tự nhiên liên kết với hình ảnh nguồn, hoặc bản kết xuất.
Ngoài ra, việc tăng tỷ lệ phân giải dựa trên ô thực sự sẽ là một bổ sung được chào đón, vì ESRGAN gần như là một công cụ thô như GFPGAN. May mắn thay, các kế hoạch tích hợp triển khai txt2imghd của GOBIG đang nhanh chóng biến điều này thành hiện thực trên các phân phối, và dường như là một lựa chọn rõ ràng cho một phiên bản trên máy tính để bàn.
Một số yêu cầu phổ biến khác từ các cộng đồng Discord ít thu hút tôi, chẳng hạn như từ điển lời nhắc tích hợp và danh sách các phong cách và nghệ sĩ có thể áp dụng, mặc dù một cuốn sổ tay trong ứng dụng hoặc từ vựng có thể tùy chỉnh sẽ có vẻ là một bổ sung hợp lý.
Tương tự, các hạn chế hiện tại của hoạt hình tập trung vào con người trong Stable Diffusion, mặc dù đã được khởi động bởi CogVideo và các dự án khác, vẫn còn rất sơ khai, và phụ thuộc vào nghiên cứu thượng游 về các yếu tố thời gian liên quan đến chuyển động của con người.
Đối với bây giờ, video Stable Diffusion nghiêm ngặt psychedelic, mặc dù nó có thể có một tương lai gần sáng sủa hơn trong lĩnh vực búp bê deepfake, thông qua EbSynth và các sáng kiến chuyển đổi văn bản sang video tương đối mới (và đáng chú ý là sự thiếu vắng các người được tổng hợp hoặc ‘biến đổi’ trong video quảng cáo mới nhất của Runway).
Một chức năng hữu ích khác sẽ là khả năng truyền hình ảnh một cách minh bạch giữa các ứng dụng, một tính năng đã được thiết lập từ lâu trong trình chỉnh sửa kết cấu của Cinema4D, trong số các triển khai tương tự khác. Với điều này, bạn có thể dễ dàng chuyển hình ảnh giữa các ứng dụng và sử dụng mỗi ứng dụng để thực hiện các biến đổi mà nó giỏi.
Cuối cùng, và có lẽ quan trọng nhất, một chương trình đầy đủ trên máy tính để bàn của Stable Diffusion nên không chỉ có thể dễ dàng chuyển đổi giữa các điểm kiểm tra (tức là các phiên bản của mô hình cơ bản cung cấp năng lượng cho hệ thống), mà còn có thể cập nhật các Đảo ngược Văn bản tùy chỉnh đã hoạt động với các phiên bản phát hành mô hình trước, nhưng có thể bị hỏng bởi các phiên bản mô hình sau (như các nhà phát triển tại Discord chính thức đã chỉ ra có thể là trường hợp).
Ironically, tổ chức ở vị trí tốt nhất để tạo ra một tập hợp mạnh mẽ và tích hợp như vậy các công cụ cho Stable Diffusion, Adobe, đã liên minh mạnh mẽ với Sáng kiến Tính xác thực Nội dung đến mức có vẻ như một bước lùi về quan hệ công chúng nếu công ty đó không làm suy yếu khả năng tạo ra của Stable Diffusion một cách triệt để, và thay vào đó định vị nó như một sự tiến hóa tự nhiên của các cổ phần đáng kể của nó trong nhiếp ảnh cổ phiếu.
Được xuất bản lần đầu vào ngày 15 tháng 9 năm 2022.












