Trí tuệ nhân tạo
Adobe Research Mở Rộng Chỉnh Sửa Mặt Bằng Disentangled GAN

Không khó để hiểu tại sao sự trộn lẫn là một vấn đề trong tổng hợp hình ảnh, vì nó thường là một vấn đề trong các lĩnh vực khác của cuộc sống; ví dụ, việc loại bỏ nghệ tây khỏi cà ri khó hơn nhiều so với việc loại bỏ dưa chuột muối khỏi bánh hamburger, và gần như không thể loại bỏ độ ngọt khỏi một tách cà phê. Một số thứ chỉ đến trong gói.
Tương tự như vậy, sự trộn lẫn là một chướng ngại vật đối với các kiến trúc tổng hợp hình ảnh muốn lý tưởng như tách biệt các tính năng và khái niệm khác nhau khi sử dụng học máy để tạo hoặc chỉnh sửa khuôn mặt (hoặc chó, tàu, hoặc bất kỳ lĩnh vực nào khác).
Nếu bạn có thể tách biệt các sợi như tuổi, giới tính, màu tóc, màu da, tình cảm, và như vậy, bạn sẽ có những khởi đầu của công cụ và tính linh hoạt trong một khuôn khổ có thể tạo và chỉnh sửa hình ảnh khuôn mặt ở mức độ hạt nhỏ, mà không kéo theo những “hành khách” không mong muốn vào những chuyển đổi này.

Ở mức trộn lẫn tối đa (trên bên trái), tất cả những gì bạn có thể làm là thay đổi hình ảnh của một mạng lưới GAN đã học thành hình ảnh của một người khác.
Đây hiệu quả là sử dụng công nghệ tầm nhìn máy tính AI mới nhất để đạt được điều gì đó đã được giải quyết bằng các phương tiện khác hơn ba thập kỷ trước.
Với một mức độ tách biệt nào đó (‘Tách biệt Trung bình’ trong hình ảnh trên), có thể thực hiện các thay đổi dựa trên phong cách như màu tóc, biểu cảm, ứng dụng mỹ phẩm và xoay đầu hạn chế, trong số những thứ khác.

Nguồn: FEAT: Face Editing with Attention, February 2022, https://arxiv.org/pdf/2202.02713.pdf
Đã có một số nỗ lực trong hai năm qua để tạo ra các môi trường chỉnh sửa khuôn mặt tương tác cho phép người dùng thay đổi các đặc điểm khuôn mặt với các thanh trượt và các tương tác UI truyền thống, trong khi giữ nguyên các tính năng cốt lõi của khuôn mặt mục tiêu khi thực hiện các bổ sung hoặc thay đổi. Tuy nhiên, điều này đã chứng minh là một thách thức do sự trộn lẫn tính năng/phong cách trong không gian tiềm ẩn của GAN.
Ví dụ, đặc điểm kính thường bị trộn lẫn với đặc điểm tuổi, có nghĩa là thêm kính có thể “làm già” khuôn mặt, trong khi việc già đi khuôn mặt có thể thêm kính, tùy thuộc vào mức độ tách biệt của các tính năng cấp cao (xem ‘Kiểm tra’ dưới đây để biết các ví dụ).
Đáng chú ý nhất, gần như không thể thay đổi màu tóc và các khía cạnh tóc khác mà không tính toán lại các sợi tóc và sự sắp xếp, điều này tạo ra hiệu ứng “nóng”, chuyển tiếp.

Nguồn: InterFaceGAN Demo (CVPR 2020), https://www.youtube.com/watch?v=uoftpl3Bj6w
Di Chuyển Latent-to-Latent GAN
Một bài báo mới do Adobe dẫn đầu được gửi cho WACV 2022 cung cấp một cách tiếp cận mới cho các vấn đề cơ bản trong một bài báo có tiêu đề Latent to Latent: A Learned Mapper for Identity Preserving Editing of Multiple Face Attributes in StyleGAN-generated Images.

Tài liệu bổ sung từ bài báo Latent to Latent: A Learned Mapper for Identity Preserving Editing of Multiple Face Attributes in StyleGAN-generated Images. Ở đây, chúng ta thấy rằng các đặc điểm cơ bản trong khuôn mặt đã học không bị kéo vào các thay đổi không liên quan. Xem video nhúng đầy đủ ở cuối bài viết để có chi tiết và độ phân giải tốt hơn. Nguồn: https://www.youtube.com/watch?v=rf_61llRH0Q
Bài báo này được dẫn đầu bởi Nhà khoa học ứng dụng Adobe Siavash Khodadadeh, cùng với bốn nhà nghiên cứu Adobe khác và một nhà nghiên cứu từ Bộ phận Khoa học Máy tính tại Đại học Central Florida.
Bài báo này thú vị một phần vì Adobe đã hoạt động trong không gian này trong một thời gian, và rất hấp dẫn khi tưởng tượng chức năng này sẽ đi vào một dự án Creative Suite trong vài năm tới; nhưng chủ yếu vì kiến trúc được tạo cho dự án này có một cách tiếp cận khác nhau để duy trì tính toàn vẹn trực quan trong một trình chỉnh sửa khuôn mặt GAN khi các thay đổi đang được áp dụng.
Các tác giả tuyên bố:
‘[Chúng] đào tạo một mạng lưới thần kinh để thực hiện một biến đổi tiềm ẩn-to-tiềm ẩn tìm mã hóa tiềm ẩn tương ứng với hình ảnh có thuộc tính đã thay đổi. Vì kỹ thuật này là một-shot, nó không dựa trên một đường dẫn tuyến tính hoặc không tuyến tính của sự thay đổi dần dần của các thuộc tính.
‘Bằng cách đào tạo mạng lưới từ đầu đến cuối trên toàn bộ đường ống tạo, hệ thống có thể thích nghi với không gian tiềm ẩn của các kiến trúc tạo ra sẵn. Các thuộc tính bảo tồn, chẳng hạn như duy trì bản sắc của người, có thể được mã hóa dưới dạng tổn thất đào tạo.
‘Một khi mạng lưới tiềm ẩn-to-tiềm ẩn đã được đào tạo, nó có thể được tái sử dụng cho các hình ảnh tùy ý mà không cần đào tạo lại.’
Điều này cuối cùng có nghĩa là kiến trúc được đề xuất đến với người dùng trong một trạng thái hoàn thiện. Nó vẫn cần chạy một mạng lưới thần kinh trên tài nguyên địa phương, nhưng các hình ảnh mới có thể được ‘thả vào’ và sẵn sàng để thay đổi gần như ngay lập tức, vì khuôn khổ này được tách biệt đủ để không cần đào tạo lại hình ảnh cụ thể.
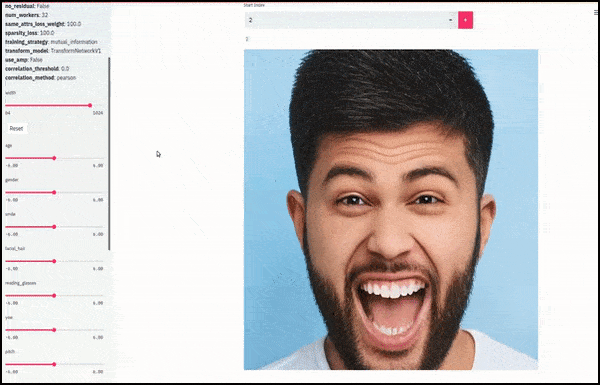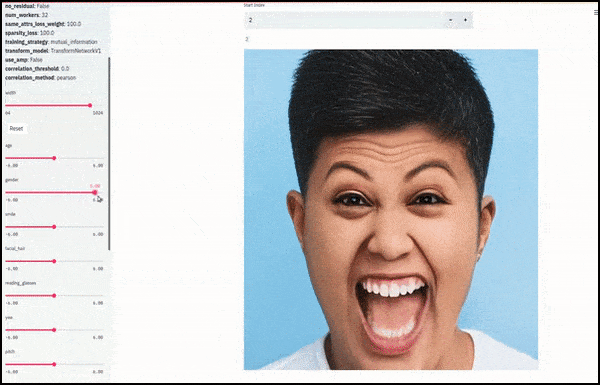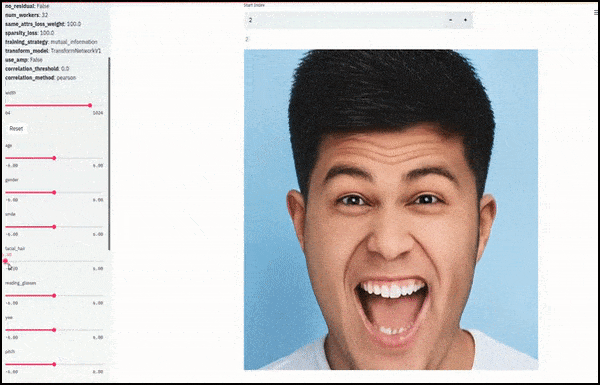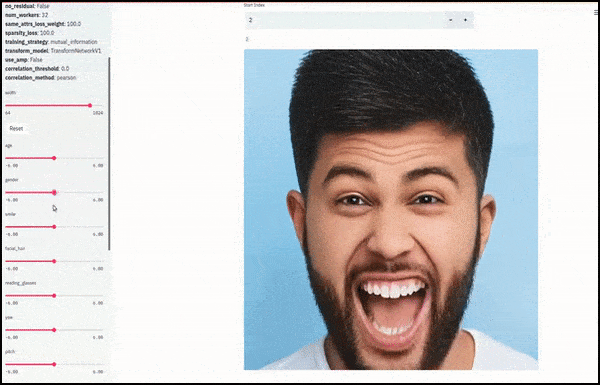
Giới tính và râu được thay đổi khi các thanh trượt vẽ các đường ngẫu nhiên và tùy ý qua không gian tiềm ẩn, không chỉ ‘chà giữa các điểm cuối’. Xem video nhúng ở cuối bài viết để có nhiều biến đổi hơn với độ phân giải tốt hơn.
Trong số các thành tựu chính trong công việc là khả năng của mạng lưới ‘đóng băng’ bản sắc trong không gian tiềm ẩn bằng cách thay đổi chỉ thuộc tính trong vector mục tiêu, và cung cấp ‘các điều khoản sửa chữa’ để bảo tồn bản sắc đang được biến đổi.
Về cơ bản, mạng lưới được đề xuất này được nhúng trong một kiến trúc rộng lớn hơn điều khiển tất cả các yếu tố được xử lý, những yếu tố này sẽ đi qua các thành phần đã được đào tạo trước với trọng số bị đóng băng sẽ không tạo ra các hiệu ứng phụ không mong muốn trên các biến đổi.
Vì quá trình đào tạo dựa trên các bộ ba có thể được tạo ra bởi một hình ảnh hạt giống (dưới đảo ngược GAN) hoặc một mã hóa tiềm ẩn ban đầu, toàn bộ quá trình đào tạo là không giám sát, với các hành động mặc định của các hệ thống ghi nhãn và chăm sóc thông thường trong các hệ thống như vậy hiệu quả được tích hợp vào kiến trúc. Trên thực tế, hệ thống mới này sử dụng các bộ phân tích thuộc tính sẵn có:
‘[Số] thuộc tính mà mạng lưới của chúng tôi có thể kiểm soát độc lập chỉ bị giới hạn bởi khả năng của bộ nhận diện(s) – nếu một người có bộ nhận diện cho một thuộc tính, chúng tôi có thể thêm nó vào các khuôn mặt tùy ý. Trong các thí nghiệm của chúng tôi, chúng tôi đã đào tạo mạng lưới tiềm ẩn-to-tiềm ẩn để cho phép điều chỉnh 35 thuộc tính khuôn mặt khác nhau, nhiều hơn bất kỳ phương pháp nào trước đó.’
Hệ thống này bao gồm một biện pháp bảo vệ bổ sung chống lại các biến đổi ‘hiệu ứng phụ’ không mong muốn: trong trường hợp không có yêu cầu thay đổi thuộc tính, mạng lưới tiềm ẩn-to-tiềm ẩn sẽ ánh xạ một vector tiềm ẩn đến chính nó, tăng thêm sự ổn định của bản sắc mục tiêu.
Nhận Dạng Khuôn Mặt
Một vấn đề lặp lại với các trình chỉnh sửa khuôn mặt GAN và mã hóa/giải mã dựa trên các năm qua là các biến đổi áp dụng có xu hướng làm giảm sự tương đồng. Để chống lại điều này, dự án Adobe sử dụng một mạng lưới nhận dạng khuôn mặt nhúng gọi là FaceNet làm một bộ phân biệt.

Kiến trúc dự án, xem phía dưới bên trái để bao gồm FaceNet. Nguồn: Latent to Latent: A Learned Mapper for Identity Preserving Editing of Multiple Face Attributes in StyleGAN-generated Images, OpenAccess.
(Về một lưu ý cá nhân, đây dường như là một bước tiến khuyến khích hướng tới việc tích hợp các hệ thống nhận dạng khuôn mặt và thậm chí nhận dạng biểu cảm chuẩn vào các mạng lưới tạo, có thể là cách tiếp cận tốt nhất để vượt qua sự ánh xạ pixel-to-pixel mù đang chiếm ưu thế trong các kiến trúc deepfake hiện tại với chi phí của sự trung thực biểu cảm và các lĩnh vực quan trọng khác trong lĩnh vực tạo khuôn mặt.)
Truy Cập Tất Cả Các Khu Vực trong Không Gian Tiềm Ẩn
Một tính năng ấn tượng khác của khuôn khổ này là khả năng di chuyển tùy ý giữa các biến đổi tiềm năng trong không gian tiềm ẩn, theo ý muốn của người dùng. Một số hệ thống trước đây cung cấp các giao diện khám phá thường để lại người dùng thực sự ‘chà’ giữa các đường thời gian biến đổi tính năng cố định – ấn tượng, nhưng thường khá tuyến tính hoặc quy định.

Từ Improving GAN Equilibrium by Raising Spatial Awareness: ở đây người dùng chà qua một loạt các điểm chuyển tiếp tiềm năng giữa hai vị trí không gian tiềm ẩn, nhưng trong giới hạn của các vị trí không gian tiềm ẩn đã được đào tạo trước. Để áp dụng các loại biến đổi khác dựa trên cùng một vật liệu, cần phải cấu hình lại và/hoặc đào tạo lại. Nguồn: https://genforce.github.io/eqgan/
Ngoài việc có thể tiếp nhận hoàn toàn các hình ảnh người dùng mới, người dùng cũng có thể ‘đóng băng’ thủ công các yếu tố mà họ muốn bảo tồn trong quá trình biến đổi. Theo cách này, người dùng có thể đảm bảo rằng (ví dụ) các nền không thay đổi, hoặc mắt được giữ mở hoặc đóng.
Dữ Liệu
Mạng lưới phân tích thuộc tính được đào tạo trên ba mạng lưới: FFHQ, CelebAMask-HQ, và một mạng lưới được tạo ra cục bộ, GAN, thu được bằng cách lấy mẫu 400.000 vector từ không gian Z của StyleGAN-V2.
Các hình ảnh ngoài phân phối (OOD) đã được lọc đi, và các thuộc tính được trích xuất sử dụng Face API của Microsoft, với tập dữ liệu hình ảnh kết quả được chia 90/10, để lại 721.218 hình ảnh đào tạo và 72.172 hình ảnh kiểm tra để so sánh.
Kiểm Tra
Mặc dù mạng lưới thử nghiệm ban đầu được cấu hình để hỗ trợ 35 biến đổi tiềm năng, nhưng chúng đã được giảm xuống còn tám để thực hiện các kiểm tra tương tự so với các khuôn khổ có thể so sánh InterFaceGAN, GANSpace, và StyleFlow.
Tám thuộc tính được chọn là Tuổi, Trọc, Râu, Biểu cảm, Giới tính, Kính, Góc, và Yaw. Cần phải tái cấu trúc các khuôn khổ cạnh tranh cho một số thuộc tính trong tám thuộc tính không được cung cấp trong phân phối ban đầu, chẳng hạn như thêm trọc và râu vào InterFaceGAN.
Như dự kiến, một mức độ trộn lẫn cao hơn xảy ra trong các kiến trúc cạnh tranh. Ví dụ, trong một thử nghiệm, InterFaceGAN và StyleFlow đều thay đổi giới tính của đối tượng khi được yêu cầu áp dụng tuổi:

Hai trong số các khuôn khổ cạnh tranh đã cuộn một thay đổi giới tính vào biến đổi ‘tuổi’, cũng thay đổi màu tóc mà không có yêu cầu trực tiếp của người dùng.
Ngoài ra, hai trong số các đối thủ cạnh tranh đã tìm thấy rằng kính và tuổi là những khía cạnh không thể tách rời:

Kính và màu tóc thay đổi được đưa vào miễn phí!
Không phải là một chiến thắng đồng đều cho nghiên cứu: như có thể thấy trong video đính kèm ở cuối bài viết, khuôn khổ này là kém hiệu quả nhất khi cố gắng ngoại suy các góc đa dạng (yaw), trong khi GANSpace có một kết quả chung tốt hơn cho tuổi và việc áp dụng kính. Khung tiềm ẩn-to-tiềm ẩn đã liên kết với GANSpace và StyleFlow về việc thêm góc (góc của đầu).

Kết quả được tính toán dựa trên việc hiệu chỉnh bộ phát hiện khuôn mặt MTCNN. Kết quả thấp hơn là tốt hơn.
Để biết thêm chi tiết và độ phân giải tốt hơn của các ví dụ, hãy kiểm tra video đi kèm của bài báo dưới đây.
https://www.youtube.com/watch?v=rf_61llRH0Q
Được xuất bản lần đầu tiên vào ngày 16 tháng 2 năm 2022.













{kind=link}