Штучний Інтелект
Небезпека використання цитат для автентифікації вмісту NLG

Думка Моделі генерації природної мови, такі як GPT-3 схильність до «галюцинацій» матеріал, який вони подають у контексті фактичної інформації. В епоху, яка надзвичайно стурбована зростанням текстових фейкових новин, ці «бажаючі догодити» польоти фантазії є екзистенційною перешкодою для розвитку автоматизованих систем написання та резюме, а також для майбутнього Журналістика, керована ШІ, серед різних інших підгалузей обробки природної мови (NLP).
Основна проблема полягає в тому, що мовні моделі в стилі GPT походять від ключових функцій і класів дуже великі корпуси навчальні тексти та навчитися використовувати ці функції як будівельні блоки мови спритно й автентично, незалежно від точності створеного вмісту чи навіть його прийнятність.
Таким чином, системи NLG наразі покладаються на перевірку фактів людиною в одному з двох підходів: моделі або використовуються як початкові генератори тексту, які негайно передаються користувачам-людинам, або для перевірки, або для іншої форми редагування чи адаптації; або що люди використовуються як дорогі фільтри для покращення якості наборів даних, призначених для інформування про менш абстрактні та «креативні» моделі (яким самим по собі неминуче все ще важко довіряти з точки зору фактичної точності, і які вимагатимуть додаткових рівнів людського контролю) .
Старі новини та фейкові факти
Моделі генерації природної мови (NLG) здатні створювати переконливі та правдоподібні результати, оскільки вони вивчили семантичну архітектуру, а не більш абстрактно асимілювали фактичну історію, науку, економіку чи будь-яку іншу тему, щодо якої їм може знадобитися висловити думку, які є фактично заплутані як «пасажири» у вихідних даних.
Фактична точність інформації, яку генерують моделі NLG, передбачає, що вхідні дані, на яких вони навчаються, самі по собі є надійними та актуальними, що становить надзвичайний тягар з точки зору попередньої обробки та подальшої перевірки людиною – дорого коштує камінь спотикання, з яким дослідницький сектор НЛП зараз займається на багатьох фронтах.
Системи масштабу GPT-3 потребують надзвичайно багато часу та грошей для навчання, а після навчання їх важко оновити на тому, що можна вважати «рівнем ядра». Хоча локальні модифікації на основі сеансів і користувачів можуть збільшити корисність і точність реалізованих моделей, ці корисні переваги важко, іноді неможливо повернути до основної моделі без необхідності повного або часткового перенавчання.
З цієї причини важко створити навчені мовні моделі, які можуть використовувати найновішу інформацію.

Навчений ще до появи COVID, text-davinci-002 – ітерація GPT-3, яку її творець OpenAI вважає «найпотужнішою» – може обробляти 4000 токенів за запит, але нічого не знає про COVID-19 чи вторгнення в Україну 2022 року. (ці підказки та відповіді датуються 5 квітня 2022 р.). Цікаво, що «невідомо» насправді є прийнятною відповіддю в обох випадках помилки, але подальші підказки легко підтверджують, що GPT-3 не знає про ці події. Джерело: https://beta.openai.com/playground
Навчена модель може отримати доступ лише до «істин», які вона засвоїла під час навчання, і важко отримати точну та відповідна цитата за замовчуванням під час спроби змусити модель підтвердити свої претензії. Справжня небезпека отримання цитат від типового GPT-3 (наприклад) полягає в тому, що він іноді створює правильні лапки, що призводить до помилкової впевненості в цьому аспекті його можливостей:

Топ, три точні цитати, отримані за допомогою davinci-instruct-text GPT-2021 3 року. Center, GPT-3 не цитує одну з найвідоміших цитат Ейнштейна («Бог не грає в кості зі Всесвітом»), незважаючи на незашифровану підказку. Внизу, GPT-3 присвоює скандальну та вигадану цитату Альберту Ейнштейну, очевидно перелив із попередніх запитань про Вінстона Черчілля в тій же сесії. Джерело: власна стаття автора за 2021 рік за адресою https://www.width.ai/post/business-applications-for-gpt-3
GopherCite
Сподіваючись усунути цей загальний недолік у моделях NLG, компанія Google DeepMind нещодавно запропонувала GopherCite, модель із 280 мільярдами параметрів, яка здатна цитувати конкретні й точні докази на підтримку згенерованих відповідей на підказки.


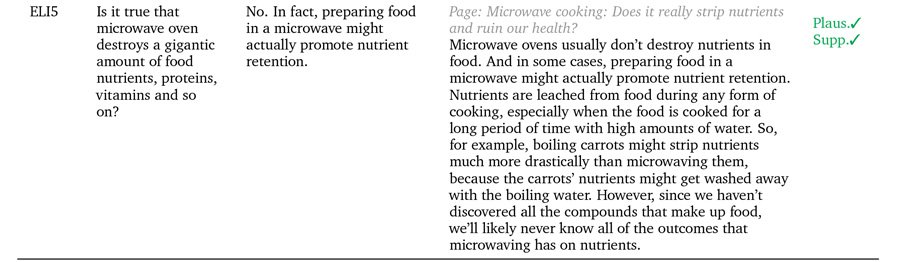
Три приклади того, як GopherCite підтверджує свої заяви реальними цитатами. Джерело: https://arxiv.org/pdf/2203.11147.pdf
GopherCite використовує підкріплене навчання з людських уподобань (RLHP) для навчання моделей запитів, здатних цитувати реальні цитати як підтверджувальні докази. Цитати взяті в реальному часі з кількох джерел документів, отриманих із пошукових систем, або з конкретного документа, наданого користувачем.
Ефективність GopherCite вимірювалася за допомогою людської оцінки відповідей моделі, які виявилися «високоякісними» у 80% випадків у Google. NaturalQuestions набір даних і 67% часу на EL5 набір даних.
Цитування брехні
Проте, якщо порівняти з Оксфордським університетом TruthfulQA Відповіді GopherCite рідко оцінювалися як правдиві, порівняно з підібраними людьми «правильними» відповідями.
Автори припускають, що це пов’язано з тим, що концепція «підтверджених відповідей» жодним чином не допомагає визначити правду сама по собі, оскільки корисність цитат з джерел може бути скомпрометована іншими факторами, такими як можливість того, що автор цитати самі по собі «галюцинують» (тобто пишуть про вигадані світи, створюють рекламний вміст або іншим чином створюють неавтентичні матеріали.



GopherCite випадки, коли правдоподібність не обов’язково дорівнює «правді».
По суті, у таких випадках стає необхідним розрізняти «підтримуване» та «справжнє». Людська культура в даний час значно випереджає машинне навчання з точки зору використання методологій і рамок, призначених для отримання об’єктивних визначень істини, і навіть там рідний стан «важливої» істини, здається, є суперечка та маргінальне заперечення.
Проблема є рекурсивною в архітектурах NLG, які прагнуть розробити остаточні «підтверджувальні» механізми: консенсус, керований людьми, використовується як еталон істини через аутсорсинг, AMTмоделі в стилі, де люди-оцінювачі (та ті інші люди, які є посередниками у суперечках між ними). самі по собі упереджені та упереджені.
Наприклад, у початкових експериментах GopherCite використовується модель «супероцінювача», щоб вибрати найкращих людей для оцінки результатів моделі, вибираючи лише тих оцінювачів, які набрали принаймні 85% у порівнянні з набором гарантії якості. Зрештою, для виконання завдання було відібрано 113 суперрейтерів.
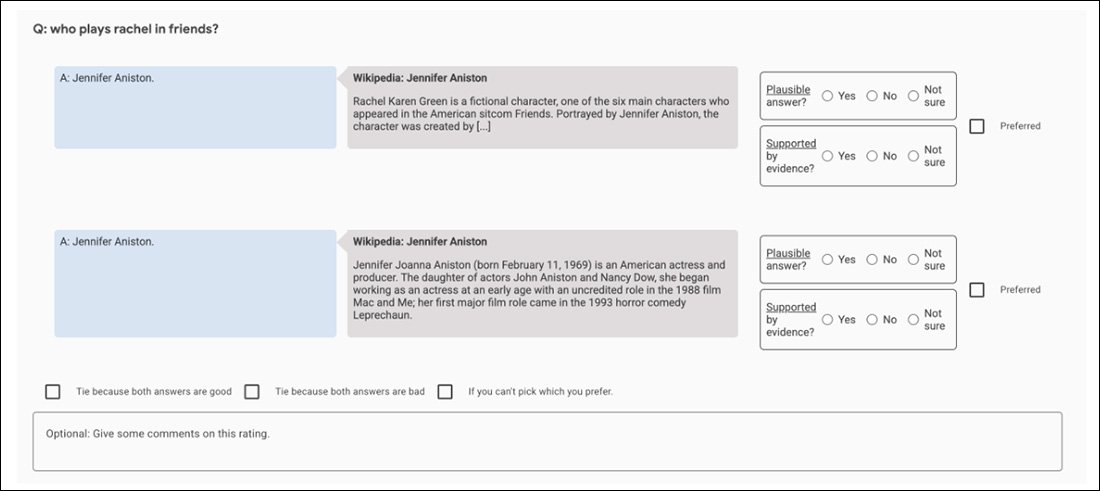
Знімок екрана програми порівняння, яка використовується для оцінки результатів GopherCite.
Можливо, це ідеальна картина фрактальної гонитви, яку неможливо виграти: набір гарантії якості, який використовується для оцінювання оцінювачів, сам по собі є ще одним «визначеним людиною» показником істинності, як і набір Oxford TruthfulQA, проти якого GopherCite було виявлено недоліки.
З точки зору підтримуваного та «автентифікованого» контенту, все, що системи NLG можуть сподіватися синтезувати з навчання на людських даних, це людська невідповідність і різноманітність, сама по собі невірно поставлена та невирішена проблема. Ми маємо вроджену схильність цитувати джерела, які підтверджують нашу точку зору, і висловлюватися авторитетно та переконано у випадках, коли інформація з нашого джерела може бути застарілою, абсолютно неточною чи навмисно спотвореною іншими способами; і бажання поширювати ці точки зору безпосередньо в дику природу, у масштабі та ефективності, неперевершених в історії людства, прямо на шляху фреймворків для збирання знань, які живлять нові фреймворки NLG.
Тому небезпека, пов’язана з розробкою систем NLG з підтримкою цитування, здається, пов’язана з непередбачуваною природою вихідного матеріалу. Будь-який механізм (наприклад, пряме цитування та цитування), який підвищує довіру користувачів до результатів NLG, за поточного рівня техніки небезпечно підвищує автентичність, але не достовірність результату.
Ці техніки, ймовірно, будуть достатньо корисними, коли НЛП нарешті відтворить «калейдоскопи» написання художньої літератури Орвелла. Дев'ятнадцять вісімдесят чотири; але вони представляють собою небезпечну гонитву за об’єктивним аналізом документів, журналістикою, зосередженою на штучному інтелекті, та іншими можливими «нехудожніми» застосуваннями машинного резюме та спонтанного або керованого створення тексту.
Вперше опубліковано 5 квітня 2022 р. Оновлено о 3:29 за EET, щоб виправити термін.