
Штучний Інтелект
InstructIR: високоякісне відновлення зображення за вказівками людини

Зображення може передати багато, але воно також може бути затьмарене різними проблемами, такими як розмиття, серпанок, шум і низький динамічний діапазон. Ці проблеми, які зазвичай називають погіршенням низькорівневого комп’ютерного зору, можуть виникати через складні умови навколишнього середовища, такі як спека чи дощ, або через обмеження самої камери. Відновлення зображення є основною проблемою для комп’ютерного зору, намагаючись відновити високоякісне, чисте зображення з такого погіршення. Відновлення зображення є складним, оскільки може бути кілька рішень для відновлення будь-якого зображення. Деякі підходи націлені на конкретне погіршення, наприклад на зменшення шуму або усунення розмитості чи серпанку.
Незважаючи на те, що ці методи можуть дати хороші результати для певних проблем, їм часто важко узагальнити різні типи деградації. Багато фреймворків використовують загальну нейронну мережу для широкого спектру завдань відновлення зображень, але кожна з цих мереж навчається окремо. Потреба в різних моделях для кожного типу деградації робить цей підхід обчислювально дорогим і трудомістким, що призводить до зосередження уваги на моделях реставрації «Все в одному» в останніх розробках. У цих моделях використовується єдина модель глибокого сліпого відновлення, яка стосується кількох рівнів і типів деградації, часто використовуючи підказки або вектори вказівок, пов’язані з деградацією, для підвищення продуктивності. Незважаючи на те, що моделі All-In-One зазвичай показують багатообіцяючі результати, вони все ще стикаються з проблемами зворотного зв’язку.
InstructIR представляє новаторський підхід у галузі, будучи першим відновлення зображення структура, розроблена для керування моделлю відновлення за допомогою написаних людиною інструкцій. Він може обробляти підказки природної мови для відновлення високоякісних зображень із пошкоджених, враховуючи різні типи погіршень. InstructIR встановлює новий стандарт продуктивності для широкого спектру завдань відновлення зображень, включаючи знебарвлення, усунення шумів, деталізацію, розмиття та покращення зображень із слабким освітленням.
Ця стаття має на меті детально розглянути фреймворк InstructIR, і ми досліджуємо механізм, методологію, архітектуру фреймворку разом із його порівнянням із сучасними фреймворками створення зображень і відео. Тож почнемо.
InstructIR: високоякісне відновлення зображень
Відновлення зображення є фундаментальною проблемою комп’ютерного зору, оскільки воно спрямоване на відновлення високоякісного чистого зображення із зображення, яке демонструє погіршення. У низькорівневому комп’ютерному зорі погіршення — це термін, який використовується для позначення неприємних ефектів, які спостерігаються в зображенні, як-от розмитість у русі, туман, шум, низький динамічний діапазон тощо. Причина, чому відновлення зображення є складною зворотною проблемою, полягає в тому, що для відновлення будь-якого зображення може бути кілька різних рішень. Деякі фреймворки зосереджені на певних деградаціях, як-от зменшення шуму екземпляра або зменшення шуму зображення, тоді як інші можуть більше зосереджуватися на видаленні розмиття чи зняття розмиття, або видаленні туману чи деталі.
Сучасні методи глибокого навчання показали кращу та стабільнішу продуктивність порівняно з традиційними методами відновлення зображень. Ці моделі глибокого навчання відновлення зображень пропонують використовувати нейронні мережі на основі трансформаторів і згорткових нейронних мереж. Ці моделі можна навчити незалежно виконувати різноманітні завдання відновлення зображень, і вони також мають здатність фіксувати локальні та глобальні взаємодії функцій і вдосконалювати їх, що забезпечує задовільну та стабільну продуктивність. Хоча деякі з цих методів можуть адекватно працювати для конкретних типів деградації, зазвичай вони погано екстраполюються на різні типи деградації. Крім того, хоча багато існуючих фреймворків використовують ту саму нейронну мережу для безлічі завдань відновлення зображень, кожна формулювання нейронної мережі навчається окремо. Отже, очевидно, що використання окремої нейронної моделі для кожної можливої деградації є непрактичним і трудомістким, тому останні фреймворки відновлення зображень зосереджені на проксі-серверах відновлення All-In-One.
Універсальні, мультидеградаційні або багатозадачні моделі відновлення зображення набувають популярності в області комп’ютерного зору, оскільки вони здатні відновлювати кілька типів і рівнів деградації в зображенні без необхідності окремого навчання моделей для кожного погіршення. . У комплексних моделях відновлення зображень використовується одна модель глибокого сліпого відновлення зображень для вирішення різних типів і рівнів погіршення зображення. Різні моделі «Все в одному» реалізують різні підходи, щоб скерувати сліпу модель для відновлення погіршеного зображення, наприклад, допоміжну модель для класифікації погіршення або багатовимірні вектори навігації або підказки, щоб допомогти моделі відновити різні типи погіршення в межах зображення.
З огляду на це, ми прийшли до маніпулювання зображеннями на основі тексту, оскільки це було реалізовано кількома фреймворками за останні кілька років для генерації тексту в зображення та завдань редагування зображень на основі тексту. У цих моделях часто використовуються текстові підказки для опису дій або зображень моделі на основі дифузії для створення відповідних зображень. Основним джерелом натхнення для фреймворку InstructIR є фреймворк InstructPix2Pix, який дозволяє моделі редагувати зображення за допомогою інструкцій користувача, які вказують моделі, яку дію потрібно виконати замість текстових міток, описів або підписів до вхідного зображення. У результаті користувачі можуть використовувати природні письмові тексти, щоб вказати моделі, яку дію виконувати, без необхідності надання зразків зображень або додаткових описів зображень.
Базуючись на цих основах, платформа InstructIR є першою в історії моделлю комп’ютерного зору, яка використовує написані людиною інструкції для досягнення відновлення зображення та вирішення зворотних проблем. Для підказок природною мовою модель InstructIR може відновлювати високоякісні зображення з їхніх аналогів із погіршенням якості, а також враховує кілька типів погіршення. Інфраструктура InstructIR здатна забезпечити найсучаснішу продуктивність для широкого спектру завдань відновлення зображення, включаючи знебарвлення зображення, усунення шумів, усунення затемнення, усунення розмиття та покращення зображення в умовах слабкого освітлення. На відміну від існуючих робіт, які досягають відновлення зображення за допомогою вивчених векторів навігацій або вбудовування підказок, структура InstructIR використовує необроблені підказки користувача в текстовій формі. Інфраструктура InstructIR здатна узагальнити відновлення зображень за допомогою написаних інструкцій людини, а єдина модель «все в одному», реалізована InstructIR, охоплює більше завдань відновлення, ніж попередні моделі. На наступному малюнку показано різноманітні зразки відновлення структури InstructIR.

InstructIR: метод і архітектура
За своєю суттю структура InstructIR складається з текстового кодувальника та моделі зображення. У моделі використовується структура NAFNet, ефективна модель відновлення зображення, яка відповідає архітектурі U-Net як модель зображення. Крім того, модель реалізує методи маршрутизації завдань для успішного вивчення кількох завдань за допомогою однієї моделі. Наступний малюнок ілюструє підхід до навчання та оцінювання для структури InstructIR.

Черпаючи натхнення з моделі InstructPix2Pix, структура InstructIR використовує письмові інструкції людини як механізм керування, оскільки користувачеві не потрібно надавати додаткову інформацію. Ці інструкції пропонують виразний і зрозумілий спосіб взаємодії, дозволяючи користувачам вказати точне місце та тип погіршення якості зображення. Крім того, використання підказок користувача замість фіксованих підказок щодо деградації покращує зручність використання та застосування моделі, оскільки вона також може використовуватися користувачами, які не мають необхідного досвіду в області. Щоб забезпечити структуру InstructIR здатністю розуміти різноманітні підказки, модель використовує GPT-4, велику мовну модель для створення різноманітних запитів, із видаленням неоднозначних і незрозумілих підказок після процесу фільтрації.
Кодер тексту
Текстовий кодувальник використовується мовними моделями для зіставлення підказок користувача з вбудованим текстом або векторним представленням фіксованого розміру. Традиційно кодувальник тексту a Модель CLIP є життєво важливим компонентом для створення текстових зображень і моделей обробки текстових зображень для кодування підказок користувача, оскільки структура CLIP перевершує візуальні підказки. Однак у більшості випадків підказки користувача щодо деградації не містять візуального вмісту або не містять його, тому великі кодери CLIP стають марними для таких завдань, оскільки це значно знижує ефективність. Щоб вирішити цю проблему, структура InstructIR вибирає кодувальник речень на основі тексту, який навчено кодувати речення в осмисленому просторі вбудовування. Кодувальники речень попередньо навчені на мільйонах прикладів, але вони компактні та ефективні порівняно з традиційними текстовими кодувальниками на основі CLIP, але мають можливість кодувати семантику різноманітних підказок користувача.
Текстове керівництво
Основним аспектом структури InstructIR є реалізація закодованої інструкції як механізму керування для моделі зображення. Спираючись на це та натхненний маршрутизацією завдань для вивчення багатьох завдань, структура InstructIR пропонує блок побудови інструкцій або ICB, щоб уможливити трансформації конкретних завдань у моделі. Традиційна маршрутизація завдань застосовує двійкові маски для конкретних завдань до функцій каналу. Однак, оскільки структура InstructIR не знає деградації, ця техніка не реалізована безпосередньо. Крім того, для функцій зображення та закодованих інструкцій платформа InstructIR застосовує маршрутизацію завдань і створює маску за допомогою лінійного шару, активованого за допомогою функції Sigmoid, щоб створити набір вагових коефіцієнтів залежно від вбудованих текстів, таким чином отримуючи c-вимірний пер двійкова маска каналу. Модель додатково вдосконалює обумовлені функції за допомогою NAFBlock і використовує NAFBlock і Instruction Conditioned Block для обумовлення функцій як у блоці кодера, так і в блоці декодера.
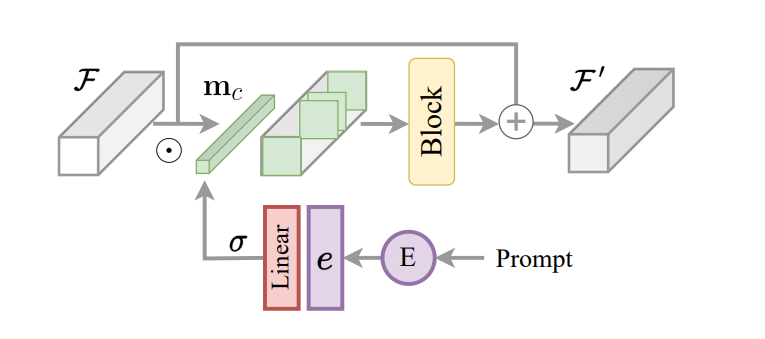
Хоча структура InstructIR явно не обумовлює фільтри нейронної мережі, маска полегшує модель для вибору найбільш релевантних каналів на основі інструкцій зображення та інформації.
InstructIR: впровадження та результати
Модель InstructIR можна наскрізно навчати, а модель зображення не потребує попереднього навчання. Треба навчити лише проекції вбудовування тексту та голову класифікації. Текстовий кодер ініціалізується за допомогою кодувальника BGE, BERT-подібного кодера, який попередньо навчений на величезній кількості контрольованих і неконтрольованих даних для кодування речень загального призначення. Структура InstructIR використовує модель NAFNet як модель зображення, а архітектура NAFNet складається з 4-рівневого кодера-декодера з різною кількістю блоків на кожному рівні. Модель також додає 4 середні блоки між кодером і декодером для подальшого покращення функцій. Крім того, замість конкатенації для пропускаючих з’єднань декодер реалізує додавання, а модель InstructIR реалізує лише ICB або Instruction Conditioned Block для маршрутизації завдань лише в кодері та декодері. Рухаючись далі, модель InstructIR оптимізовано з використанням втрати між відновленим зображенням і чистим зображенням, а перехресна ентропійна втрата використовується для головки класифікації намірів кодера тексту. Модель InstructIR використовує оптимізатор AdamW із розміром пакета 32 і швидкістю навчання 5e-4 протягом майже 500 епох, а також реалізує затухання швидкості навчання косинусного відпалу. Оскільки модель зображення у фреймворку InstructIR містить лише 16 мільйонів параметрів, а існує лише 100 тисяч вивчених параметрів проекції тексту, фреймворк InstructIR можна легко навчити на стандартних графічних процесорах, таким чином зменшуючи обчислювальні витрати та підвищуючи застосовність.
Багаторазові результати деградації
Для багаторазових деградацій і багатозадачних відновлень структура InstructIR визначає дві початкові настройки:
- 3D для моделей із трьома деградаціями для вирішення проблем деградації, як-от дегенерація, шумозаглушення та зневоднення.
- 5D для п’яти моделей деградації для вирішення проблем деградації, як-от усунення шумів зображення, покращення при слабкому освітленні, усунення затемнень, усунення шумів і знебарвлення.
Продуктивність 5D-моделей показано в наведеній нижче таблиці та порівнює її з сучасними моделями відновлення зображень і моделями «все в одному».

Як можна помітити, структура InstructIR із простою моделлю зображення та лише 16 мільйонами параметрів може успішно виконувати п’ять різних завдань відновлення зображення завдяки вказівкам на основі інструкцій і забезпечує конкурентоспроможні результати. У наведеній нижче таблиці показано продуктивність фреймворку на 3D-моделях, і результати можна порівняти з наведеними вище результатами.

Основною особливістю структури InstructIR є відновлення зображення на основі інструкцій, і наступний малюнок демонструє неймовірні можливості моделі InstructIR для розуміння широкого діапазону інструкцій для певного завдання. Крім того, для змагальної інструкції модель InstructIR виконує ідентифікацію, яка не є примусовою.

Заключні думки
Відновлення зображення є фундаментальною проблемою комп’ютерного зору, оскільки воно спрямоване на відновлення високоякісного чистого зображення із зображення, яке демонструє погіршення. У низькорівневому комп’ютерному зорі погіршення — це термін, який використовується для позначення неприємних ефектів, які спостерігаються в зображенні, як-от розмитість у русі, туман, шум, низький динамічний діапазон тощо. У цій статті ми говорили про InstructIR, першу в світі структуру відновлення зображень, яка має на меті керувати моделлю відновлення зображень за допомогою написаних людиною інструкцій. Для підказок природною мовою модель InstructIR може відновлювати високоякісні зображення з їхніх аналогів із погіршенням якості, а також враховує кілька типів погіршення. Інфраструктура InstructIR здатна забезпечити найсучаснішу продуктивність для широкого спектру завдань відновлення зображення, включаючи знебарвлення зображення, усунення шумів, усунення затемнення, усунення розмиття та покращення зображення в умовах слабкого освітлення.















