
Штучний Інтелект
Створення мовної моделі в стилі GPT для окремого запитання

Дослідники з Китаю розробили економічний метод для створення систем обробки природної мови у стилі GPT-3, уникаючи при цьому надмірних витрат часу та грошей на навчання масивів даних великого обсягу – зростаючої тенденції, яка в іншому випадку загрожує зрештою витіснити цей сектор штучного інтелекту. для гравців FAANG та інвесторів високого рівня.
Пропонований каркас називається Моделювання мови на основі завдань (TLM). Замість навчання величезної та складної моделі на величезному корпусі з мільярдів слів і тисяч міток і класів, TLM замість цього навчає набагато меншу модель, яка фактично включає запит безпосередньо в модель.

Зліва, типовий гіпермасштабний підхід до мовних моделей великого обсягу; праворуч, тонкий метод TLM для дослідження великого мовного корпусу на основі теми чи питання. Джерело: https://arxiv.org/pdf/2111.04130.pdf
По суті, унікальний алгоритм або модель НЛП створюється для того, щоб відповісти на одне запитання, замість створення величезної та громіздкої загальної мовної моделі, яка може відповісти на більш широкий спектр питань.
Під час тестування TLM дослідники виявили, що новий підхід дає результати, подібні або кращі, ніж попередньо навчені мовні моделі, такі як RoBERTa-Великий, а також гіпермасштабовані системи НЛП, такі як OpenAI GPT-3, Google TRILLION Parameter Switch Transformer Model, Кореї Гіперконюшина, AI21 Labs' Юра 1, і Microsoft Megatron-Turing NLG 530B.
Під час випробувань TLM на восьми класифікаційних наборах даних у чотирьох доменах автори також виявили, що система зменшує навчальні FLOP (операцій з плаваючою комою в секунду) потрібно на два порядки величини. Дослідники сподіваються, що TLM зможе «демократизувати» сектор, який стає все більш елітним, з такими великими моделями НЛП, що їх реально неможливо встановити локально, і натомість, у випадку GPT-3, стояти позаду дорогий і API з обмеженим доступом OpenAI і, тепер Microsoft Azure.
Автори стверджують, що скорочення часу навчання на два порядки зменшує витрати на навчання понад 1,000 графічних процесорів протягом одного дня до лише 8 графічних процесорів протягом 48 годин.
Новий звітом має титул НЛП з нуля без масштабної попередньої підготовки: проста та ефективна структура, і походить від трьох дослідників з Університету Цінхуа в Пекіні та дослідника з китайської компанії з розробки ШІ Recurrent AI, Inc.
Недоступні відповіді
Команда коштувати Навчання ефективних, універсальних мовних моделей дедалі більше характеризується як потенційна «термічна межа» того, до якої міри результативний і точний НЛП може справді поширюватися в культурі.
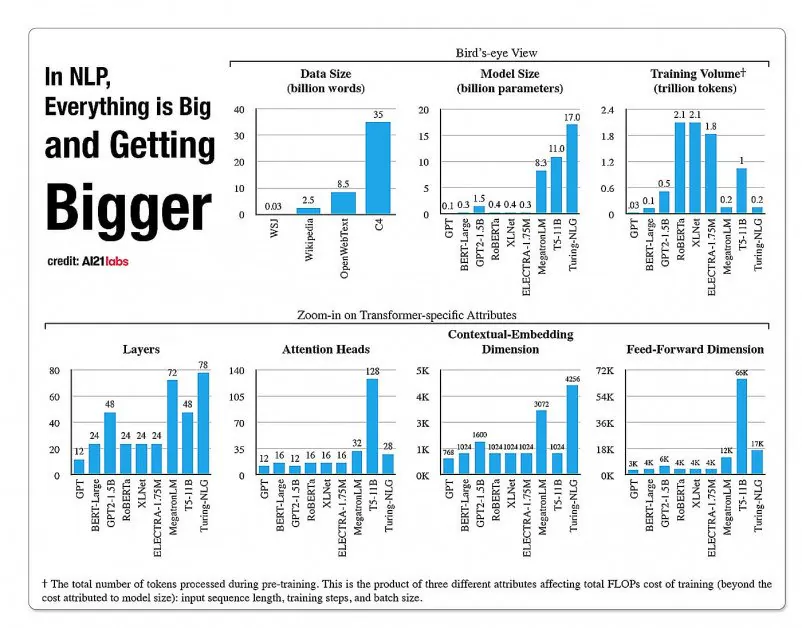
Статистичні дані про зростання фасетів в архітектурах моделей NLP зі звіту A2020 Labs за 121 рік. Джерело: https://arxiv.org/pdf/2004.08900.pdf
У 2019 р. наук розрахований що навчання коштує 61,440 XNUMX доларів США Модель XLNet (як повідомлялося на той час, він перевершує BERT у завданнях NLP) протягом 2.5 днів на 512 ядрах на 64 пристроях, тоді як GPT-3 є оцінка навчання коштувало 12 мільйонів доларів США – у 200 разів більше, ніж витрати на навчання його попередника GPT-2 (хоча нещодавні переоцінки стверджують, що зараз його можна навчити для всього $4,600,000 на найдешевших хмарних графічних процесорах) .
Підмножини даних на основі запитів
Натомість нова запропонована архітектура прагне вивести точні класифікації, мітки та узагальнення, використовуючи запит як своєрідний фільтр для визначення підмножини інформації з великої мовної бази даних, яка буде навчена разом із запитом, щоб надати відповіді на обмежену тему.
Автори стверджують:
«TLM мотивується двома ключовими ідеями. По-перше, люди справляються із завданням, використовуючи лише невелику частину світових знань (наприклад, студентам потрібно переглянути лише кілька розділів серед усіх книг світу, щоб запихати їх на іспит).
«Ми припускаємо, що у великому корпусі є багато надлишків для конкретного завдання. По-друге, навчання керованим міченим даним є набагато більш ефективним для подальшої продуктивності, ніж оптимізація мети мовного моделювання на немічених даних. Базуючись на цих мотиваціях, TLM використовує дані завдання як запити для отримання крихітної підмножини загального корпусу. Після цього виконується спільна оптимізація цілі контрольованого завдання та цілі мовного моделювання з використанням як отриманих даних, так і даних завдання».
Окрім того, що вони роблять високоефективне навчання моделям НЛП доступним, автори бачать ряд переваг у використанні керованих завданнями моделей НЛП. По-перше, дослідники можуть насолоджуватися більшою гнучкістю завдяки спеціальним стратегіям для довжини послідовності, токенізації, налаштування гіперпараметрів і представлення даних.
Дослідники також передбачають розробку гібридних систем майбутнього, які замінять обмежене попереднє навчання PLM (яке в іншому випадку не передбачається в поточній реалізації) проти більшої універсальності та узагальнення проти часу навчання. Вони вважають систему кроком вперед для вдосконалення методів нульового узагальнення в домені.
Тестування та результати
TLM було перевірено на класифікаційні завдання у восьми завданнях у чотирьох сферах: біомедичні науки, новини, огляди та інформатика. Завдання були розділені на високоресурсні та малоресурсні категорії. Завдання з великим ресурсом включали понад 5,000 даних завдань, як-от AGNews та RCT, серед інших; включені завдання з низьким ресурсом ChemProt та ACL-ARC, А також Гіперпартизан набір даних виявлення новин.
Дослідники розробили два навчальні набори під назвою Corpus-BERT і Corpus-RoBERTa, останній у десять разів більший за перший. Експерименти порівнювали загальні попередньо підготовлені моделі мови БЕРТ (від Google) і РоБЕРТА (з Facebook) до нової архітектури.
У документі зазначається, що хоча TLM є загальним методом і має бути більш обмеженим за обсягом і застосовністю, ніж ширші та об’ємні сучасні моделі, він здатний виконувати методи тонкого налаштування, близькі до доменно-адаптивних методів.

Результати порівняння продуктивності TLM із наборами на основі BERT і RoBERTa. Результати містять середній бал F1 за трьома різними шкалами навчання, а також перераховують кількість параметрів, загальну кількість навчальних обчислень (FLOP) і розмір навчального корпусу.
Автори дійшли висновку, що TLM здатний досягти результатів, які можна порівняти або навіть краще, ніж PLM, із суттєвим зменшенням кількості FLOP, що вимагає лише 1/16 частини навчального корпусу. У середньому та великому масштабі TLM, очевидно, може підвищити продуктивність у середньому на 0.59 та 0.24 бала, одночасно зменшуючи розмір навчальних даних на два порядки.
«Ці результати підтверджують, що TLM є високоточним і набагато ефективнішим, ніж PLM. Крім того, TLM отримує більше переваг у ефективності у більшому масштабі. Це вказує на те, що більш масштабні PLM могли бути навчені зберігати більш загальні знання, які не є корисними для конкретного завдання».















