
Штучний Інтелект
EfficientViT: Ефективний трансформатор пам’яті для комп’ютерного бачення високої роздільної здатності

Завдяки високій місткості моделі Vision Transformer останнім часом користуються великим успіхом. Незважаючи на свою продуктивність, моделі трансформаторів бачення мають один серйозний недолік: їх надзвичайна обчислювальна майстерність пов’язана з високими витратами на обчислення, і це причина, чому трансформатори зору не є першим вибором для програм реального часу. Щоб вирішити цю проблему, група розробників запустила EfficientViT, сімейство високошвидкісних трансформаторів зору.
Працюючи над EfficientViT, розробники помітили, що швидкість моделей трансформаторів струму часто обмежена неефективними операціями з пам’яттю, особливо поелементними функціями та зміною форми тензорів у MHSA або мережі Multi-Head Self Attention. Щоб усунути ці неефективні операції з пам’яттю, розробники EfficientViT працювали над новим будівельним блоком, використовуючи сендвіч-схему, тобто модель EfficientViT використовує єдину прив’язану до пам’яті мережу Multi-Head Self Attention між ефективними рівнями FFN, що допомагає підвищити ефективність пам’яті та також покращує загальний канал зв’язку. Крім того, модель також виявляє, що карти уваги часто мають високу схожість між головами, що призводить до надмірності обчислень. Щоб вирішити проблему надлишковості, модель EfficientViT представляє каскадний модуль групової уваги, який передає увагу керівникам різними розділами повної функції. Цей метод не тільки допомагає заощадити обчислювальні витрати, але й покращує різноманітність уваги моделі.
Комплексні експерименти, проведені на моделі EfficientViT у різних сценаріях, показують, що EfficientViT перевершує існуючі ефективні моделі для комп'ютерне бачення в той же час досягнувши хорошого компромісу між точністю та швидкістю. Тож давайте зануримося глибше та вивчимо модель EfficientViT трохи глибше.
Вступ до Vision Transformers і EfficientViT
Vision Transformers залишаються одними з найпопулярніших фреймворків у індустрії комп’ютерного зору, оскільки вони пропонують чудову продуктивність і високі обчислювальні можливості. Однак у зв’язку з постійним підвищенням точності та продуктивності моделей трансформаторів бачення зростають також експлуатаційні витрати та накладні витрати на обчислення. Наприклад, поточні моделі, які, як відомо, забезпечують найсучаснішу продуктивність наборів даних ImageNet, таких як SwinV2 і V-MoE, використовують параметри 3B і 14.7B відповідно. Великі розміри цих моделей у поєднанні з обчислювальними витратами та вимогами роблять їх практично непридатними для пристроїв і програм реального часу.
Модель EfficientNet має на меті дослідити, як підвищити продуктивність моделі трансформери зору, а також пошук принципів, що лежать в основі розробки ефективних і ефективних трансформаторних структурних архітектур. Модель EfficientViT базується на існуючих структурах трансформатора бачення, таких як Swim і DeiT, і аналізує три основні фактори, які впливають на швидкість перешкод моделей, включаючи резервування обчислень, доступ до пам’яті та використання параметрів. Крім того, модель відзначає, що швидкість моделей трансформаторів зору обмежена пам’яттю, що означає, що повне використання обчислювальної потужності ЦП/ГП заборонено або обмежено затримкою доступу до пам’яті, що призводить до негативного впливу на швидкість роботи трансформаторів. . Поелементні функції та зміна форми тензора в мережі MHSA або Multi-Head Self Attention є найбільш неефективними операціями з використанням пам’яті. Крім того, модель зазначає, що оптимальне налаштування співвідношення між FFN (мережею прямого зв’язку) і MHSA може допомогти значно скоротити час доступу до пам’яті, не впливаючи на продуктивність. Однак модель також спостерігає деяку надлишковість у картах уваги в результаті схильності голови уваги вивчати подібні лінійні проекції.
Модель є остаточною культивацією знахідок під час дослідницької роботи для EfficientViT. Модель має новий чорний колір із сендвіч-схемою, яка застосовує один шар MHSA, прив’язаний до пам’яті, між шарами Feed Forward Network або FFN. Цей підхід не тільки скорочує час, необхідний для виконання операцій, прив’язаних до пам’яті, у MHSA, але й робить весь процес більш ефективним з використанням пам’яті, дозволяючи більшій кількості рівнів FFN для полегшення зв’язку між різними каналами. Модель також використовує новий модуль CGA або Cascaded Group Attention, який має на меті зробити обчислення більш ефективними за рахунок зменшення обчислювальної надлишковості не лише в заголовках уваги, але також збільшує глибину мережі, що призводить до підвищеної ємності моделі. Нарешті, модель розширює ширину каналу важливих мережевих компонентів, включаючи прогнози вартості, одночасно звужуючи мережеві компоненти з низькою вартістю, як-от приховані розміри в мережах прямого зв’язку, для перерозподілу параметрів у структурі.

Як видно на зображенні вище, фреймворк EfficientViT працює краще, ніж поточні сучасні моделі CNN і ViT, як з точки зору точності, так і швидкості. Але як фреймворку EfficientViT вдалося перевершити деякі сучасні фреймворки? Давайте це з’ясуємо.
EfficientViT: підвищення ефективності трансформаторів зору
Модель EfficientViT має на меті підвищити ефективність існуючих моделей трансформаторів зору, використовуючи три точки зору,
- Обчислювальна надлишковість.
- Доступ до пам'яті.
- Використання параметрів.
Модель має на меті з’ясувати, як наведені вище параметри впливають на ефективність моделей трансформаторів зору та як їх вирішити для досягнення кращих результатів із кращою ефективністю. Поговоримо про них трохи докладніше.
Доступ до пам'яті та ефективність
Одним із важливих факторів, що впливають на швидкість моделі, є накладні витрати на доступ до пам'яті або МАО. Як видно на зображенні нижче, кілька операторів у трансформаторі, включаючи поелементне додавання, нормалізацію та часте переформування, є неефективними операціями з використанням пам’яті, оскільки вони вимагають доступу до різних одиниць пам’яті, що займає багато часу.
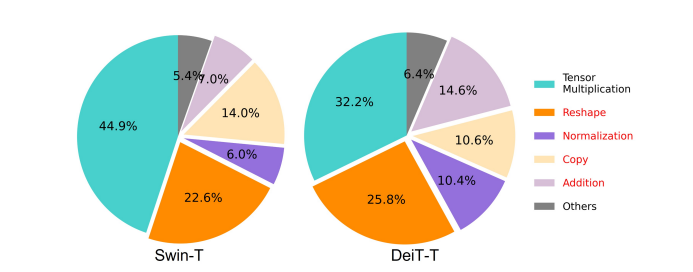
Хоча існують деякі існуючі методи, які можуть спростити стандартні обчислення softmax самоуважності, такі як наближення низького рангу та розріджена увага, вони часто пропонують обмежене прискорення та погіршують точність.
З іншого боку, фреймворк EfficientViT має на меті скоротити вартість доступу до пам’яті за рахунок зменшення кількості неефективних шарів у фреймворку. Модель зменшує масштаби DeiT-T і Swin-T до невеликих підмереж з вищою пропускною здатністю перешкод у 1.25X і 1.5X і порівнює продуктивність цих підмереж із пропорціями рівнів MHSA. Як можна побачити на зображенні нижче, при застосуванні цей підхід підвищує точність шарів MHSA приблизно на 20-40%.

Ефективність обчислень
Рівні MHSA, як правило, вбудовують послідовність введення в кілька підпросторів або заголовків і обчислюють карти уваги окремо, підхід, який, як відомо, підвищує продуктивність. Однак карти уваги недешеві з обчислювальної точки зору, і щоб дослідити витрати на обчислення, модель EfficientViT досліджує, як зменшити надлишкову увагу в менших моделях ViT. Модель вимірює максимальну косинусну подібність кожної головки та решти головок у кожному блоці шляхом навчання моделей DeiT-T і Swim-T зі зменшенням ширини з прискоренням висновку 1.25×. Як можна спостерігати на зображенні нижче, існує велика кількість подібностей між головами уваги, що свідчить про те, що модель бере на себе надлишковість обчислень, оскільки багато голов мають тенденцію вивчати подібні проекції точної повної функції.

Щоб заохотити голови вивчати різні шаблони, модель явно застосовує інтуїтивне рішення, у якому кожна голова отримує лише частину повної функції, техніка, яка нагадує ідею групової згортки. Модель тренує різні аспекти зменшених моделей, які містять модифіковані шари MHSA.
Параметр Ефективність
Звичайні моделі ViT успадкували свої стратегії проектування, такі як використання еквівалентної ширини для проекцій, встановлення коефіцієнта розширення до 4 у FFN та збільшення напору по ступенях від трансформаторів NLP. Конфігурації цих компонентів потрібно ретельно переробити для легких модулів. Модель EfficientViT розгортає структуроване скорочення Тейлора, щоб автоматично знаходити основні компоненти в шарах Swim-T і DeiT-T, а також додатково досліджує основні принципи розподілу параметрів. За певних обмежень ресурсів методи скорочення видаляють неважливі канали та зберігають критичні, щоб забезпечити найвищу можливу точність. На малюнку нижче порівнюється відношення каналів до вбудованих вхідних даних до та після скорочення на фреймворку Swin-T. Було виявлено, що: базова точність: 79.1%; точність обрізки: 76.5%.

Зображення вище вказує на те, що перші два етапи фреймворку зберігають більше розмірів, тоді як останні два етапи зберігають набагато менше розмірів. Це може означати, що типова конфігурація каналу, яка подвоює канал після кожного етапу або використовує еквівалентні канали для всіх блоків, може призвести до значної надмірності в останніх кількох блоках.
Ефективний трансформатор зору: архітектура
На основі даних, отриманих під час вищезазначеного аналізу, розробники працювали над створенням нової ієрархічної моделі, яка пропонує високі швидкості перешкод, EfficientViT модель. Давайте детально розглянемо структуру фреймворку EfficientViT. На малюнку нижче наведено загальне уявлення про структуру EfficientViT.
Будівельні блоки EfficientViT Framework
Будівельний блок для більш ефективної мережі трансформатора зору зображено на малюнку нижче.

Структура складається з каскадного модуля групової уваги, компонування сендвіча з ефективним використанням пам’яті та стратегії перерозподілу параметрів, які зосереджені на покращенні ефективності моделі з точки зору обчислень, пам’яті та параметрів відповідно. Поговоримо про них докладніше.
Сендвіч макет
У моделі використовується новий сендвіч-макет для створення ефективнішого та продуктивнішого блоку пам’яті для каркаса. Сендвіч-схема використовує менше зв’язаних з пам’яттю шарів самоконтролю та використовує більш ефективні для пам’яті мережі прямого зв’язку для зв’язку каналів. Щоб бути більш конкретним, модель застосовує один шар самоуважності для просторового змішування, який затиснутий між шарами FFN. Конструкція не тільки допомагає зменшити споживання часу пам’яті завдяки рівням самоконтролю, але й забезпечує ефективний зв’язок між різними каналами в мережі завдяки використанню рівнів FFN. Модель також застосовує додатковий рівень маркерів взаємодії перед кожним мережевим рівнем прямої подачі за допомогою DWConv або оманливої згортки та підвищує ємність моделі шляхом впровадження індуктивного зміщення локальної структурної інформації.
Каскадна групова увага
Однією з головних проблем із рівнями MHSA є надмірність у заголовках уваги, що робить обчислення більш неефективними. Щоб вирішити цю проблему, модель пропонує CGA або каскадну групову увагу для трансформаторів зору, новий модуль уваги, який черпає натхнення з групових звивин у ефективних CNN. У цьому підході модель подає окремі голови з розділенням повних функцій і, отже, розкладає обчислення уваги явно на голови. Розділення функцій замість передачі повних функцій кожній головці економить обчислення та робить процес ефективнішим, а модель продовжує працювати над підвищенням точності та своєї ємності ще більше, заохочуючи рівні вивчати проекції на об’єктах, які мають більш багату інформацію.

Перерозподіл параметрів
Щоб підвищити ефективність параметрів, модель перерозподіляє параметри в мережі, розширюючи ширину каналу критичних модулів, одночасно зменшуючи ширину каналу не дуже важливих модулів. На основі аналізу Тейлора модель або встановлює невеликі розміри каналу для проекцій у кожній головці на кожному етапі, або модель дозволяє проекціям мати той самий розмір, що й вхідні дані. Коефіцієнт розширення прямої мережі також знижений до 2 з 4, щоб допомогти з надлишковістю параметрів. Запропонована стратегія перерозподілу, яку реалізує фреймворк EfficientViT, виділяє більше каналів для важливих модулів, щоб вони могли краще вивчати представлення у великому просторі, що мінімізує втрату інформації про функції. Крім того, щоб прискорити процес перешкод і ще більше підвищити ефективність моделі, модель автоматично видаляє зайві параметри в неважливих модулях.

Огляд структури EfficientViT можна пояснити на зображенні вище, де частини,
- Архітектура EfficientViT,
- Сендвіч-блок макета,
- Каскадна групова увага.
EfficientViT: мережеві архітектури

Наведене вище зображення підсумовує мережеву архітектуру фреймворку EfficientViT. Модель представляє вбудовування патчів, що перекриваються [20,80, 16], яке вбудовує патчі розміром 16 × 1 у токени розмірності C2, що покращує здатність моделі працювати краще в навчанні візуального представлення низького рівня. Архітектура моделі включає три етапи, на яких кожен етап складається зі запропонованих будівельних блоків інфраструктури EfficientViT, а кількість токенів на кожному рівні підвибірки (4× підвибірка роздільної здатності) зменшується в XNUMX рази. Щоб зробити підвибірку більш ефективною, модель пропонує блок підвибірки, який також має запропоновану структуру сендвіча, за винятком того, що перевернутий залишковий блок замінює рівень уваги, щоб зменшити втрату інформації під час вибірки. Крім того, замість звичайного LayerNorm(LN) модель використовує BatchNorm(BN), оскільки BN можна згортати в попередні лінійні або згорткові шари, що дає їй перевагу в часі виконання перед LN.
Сімейство моделей EfficientViT
Сімейство моделей EfficientViT складається з 6 моделей з різними масштабами глибини та ширини, і для кожного ступеня призначено певну кількість головок. Моделі використовують менше блоків на початкових етапах порівняно з кінцевими етапами, процес, схожий на той, який дотримується платформа MobileNetV3, оскільки процес ранньої обробки з більшою роздільною здатністю займає багато часу. Ширина збільшується на етапах з невеликим коефіцієнтом, щоб зменшити надмірність на наступних етапах. У наведеній нижче таблиці представлені архітектурні деталі сімейства моделей EfficientViT, де C, L і H відносяться до ширини, глибини та кількості головок у певному ступені.

EfficientViT: впровадження моделі та результати
Модель EfficientViT має загальний розмір партії 2,048, створена за допомогою Timm & PyTorch, навчається з нуля протягом 300 епох за допомогою 8 графічних процесорів Nvidia V100, використовує планувальник косинусної швидкості навчання, оптимізатор AdamW і проводить свій експеримент класифікації зображень на ImageNet. -1 тис. Вхідні зображення довільно обрізаються та змінюються до роздільної здатності 224×224. Для експериментів, які включають класифікацію зображень нижче, структура EfficientViT налаштовує модель на 300 епох і використовує оптимізатор AdamW із розміром пакету 256. Модель використовує RetineNet для виявлення об’єктів на COCO та продовжує навчання моделей для наступних 12 епохи з однаковими настройками.
Результати на ImageNet
Щоб проаналізувати продуктивність EfficientViT, її порівнюють із поточними моделями ViT і CNN у наборі даних ImageNet. Результати порівняння представлені на наступному малюнку. Як можна побачити, сімейство моделей EfficientViT у більшості випадків перевершує поточні фреймворки та досягає ідеального компромісу між швидкістю та точністю.

Порівняння з ефективними CNN та ефективними ViT
Модель спочатку порівнює свою продуктивність із ефективними мережами CNN, як-от EfficientNet, і такими фреймворками CNN, як MobileNets. Як можна побачити, у порівнянні з платформами MobileNet моделі EfficientViT отримують кращий показник точності топ-1, водночас працюють у 3.0 та 2.5 рази швидше на процесорі Intel і графічному процесорі V100 відповідно.
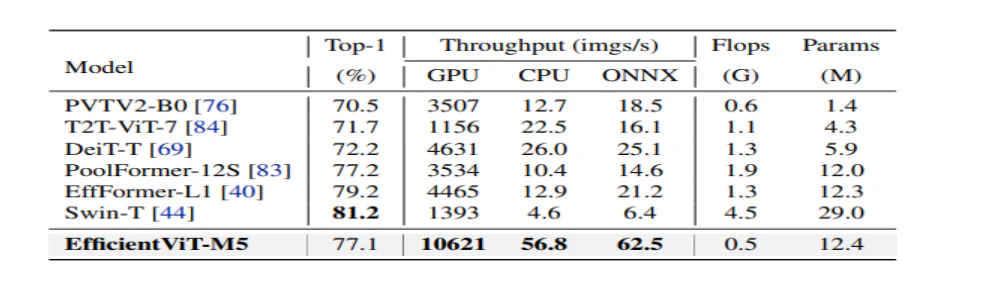
Наведений вище малюнок порівнює продуктивність моделі EfficientViT із сучасними великомасштабними моделями ViT, які працюють на наборі даних ImageNet-1K.
Класифікація зображень за потоком
Модель EfficientViT застосовується для виконання різноманітних подальших завдань для вивчення здібностей моделі до передачі навчання, і на зображенні нижче узагальнено результати експерименту. Як можна спостерігати, моделі EfficientViT-M5 вдається досягти кращих або подібних результатів у всіх наборах даних, зберігаючи при цьому набагато вищу пропускну здатність. Єдиним винятком є набір даних Cars, де модель EfficientViT не забезпечує точності.

Виявлення об'єктів
Щоб проаналізувати здатність EfficientViT виявляти об’єкти, його порівнюють із ефективними моделями завдання виявлення об’єктів COCO, і на зображенні нижче узагальнено результати порівняння.

Заключні думки
У цій статті ми говорили про EfficientViT, сімейство моделей швидкого трансформатора зору, які використовують каскадну групову увагу та забезпечують операції з ефективним використанням пам’яті. Масштабні експерименти, проведені для аналізу продуктивності EfficientViT, показали багатообіцяючі результати, оскільки модель EfficientViT у більшості випадків перевершує поточні моделі CNN і візуального трансформатора. Ми також спробували провести аналіз факторів, які відіграють роль у впливі на швидкість перешкод трансформаторів зору.















