Yapay Zeka
Doğrudan Tercih Optimizasyonu: Eksiksiz Bir Kılavuz

Büyük dil modellerini (LLM'ler) insani değerler ve tercihlerle uyumlu hale getirmek zordur. gibi geleneksel yöntemler İnsan Geri Bildiriminden Güçlendirmeli Öğrenim (RLHF), model çıktılarını iyileştirmek için insan girdilerini entegre ederek yolu açmıştır. Bununla birlikte, RLHF karmaşık ve kaynak yoğun olabilir; önemli miktarda hesaplama gücü ve veri işleme gerektirir. Doğrudan Tercih Optimizasyonu (DPO), bu geleneksel yöntemlere verimli bir alternatif sunan, yeni ve daha akıcı bir yaklaşım olarak ortaya çıkıyor. Optimizasyon sürecini basitleştirerek, DPO yalnızca hesaplama yükünü azaltmakla kalmıyor, aynı zamanda modelin insan tercihlerine hızla uyum sağlama yeteneğini de artırıyor.
Bu rehberde DPO'yu derinlemesine inceleyecek, temellerini, uygulamasını ve pratik uygulamalarını inceleyeceğiz.
Tercihlerin Hizalanması İhtiyacı
DPO'yu anlamak için, LLM'lerin insan tercihleriyle uyumlu hale getirilmesinin neden bu kadar önemli olduğunu anlamak çok önemlidir. Etkileyici yeteneklerine rağmen, geniş veri kümeleri üzerinde eğitim alan LLM'ler bazen tutarsız, önyargılı veya insan değerleriyle uyuşmayan çıktılar üretebilirler. Bu uyumsuzluk çeşitli şekillerde ortaya çıkabilir:
- Güvenli olmayan veya zararlı içerik oluşturmak
- Yanlış veya yanıltıcı bilgi vermek
- Eğitim verilerinde mevcut önyargıların sergilenmesi
Bu sorunları çözmek için araştırmacılar, insan geri bildirimlerini kullanarak LLM'lerde ince ayar yapmak için teknikler geliştirdiler. Bu yaklaşımlardan en öne çıkanı RLHF olmuştur.
RLHF'yi Anlamak: DPO'nun Öncüsü
İnsan Geri Bildiriminden Güçlendirmeli Öğrenme (RLHF), LLM'leri insan tercihleriyle uyumlu hale getirmek için başvurulan yöntem olmuştur. RLHF sürecini karmaşıklıklarını anlamak için parçalara ayıralım:
a) Denetimli İnce Ayar (SFT): Süreç, önceden eğitilmiş bir LLM'nin yüksek kaliteli yanıtlardan oluşan bir veri kümesi üzerinde ince ayarının yapılmasıyla başlar. Bu adım, modelin hedef görev için daha ilgili ve tutarlı çıktılar üretmesine yardımcı olur.
b) Ödül Modelleme: İnsan tercihlerini tahmin etmek için ayrı bir ödül modeli eğitilmiştir. Bu şunları içerir:
- Verilen istemler için yanıt çiftleri oluşturma
- İnsanların hangi yanıtı tercih ettiklerini derecelendirmesini sağlamak
- Bu tercihleri tahmin etmek için bir model eğitmek
c) Takviye Öğrenme: İnce ayarlı LLM daha sonra takviyeli öğrenme kullanılarak daha da optimize edilir. Ödül modeli geri bildirim sağlayarak LLM'nin insan tercihleriyle uyumlu yanıtlar üretmesine rehberlik eder.
RLHF sürecini göstermek için basitleştirilmiş bir Python sözde kodu şöyledir:
Etkili olmasına rağmen RLHF'nin bazı dezavantajları vardır:
- Birden fazla modelin (SFT, ödül modeli ve RL için optimize edilmiş model) eğitilmesini ve sürdürülmesini gerektirir.
- RL süreci kararsız olabilir ve hiperparametrelere karşı duyarlı olabilir
- Hesaplama açısından maliyetlidir, modeller arasında birçok ileri ve geri geçiş gerektirir
Bu sınırlamalar, daha basit, daha verimli alternatifler arayışını motive ederek DPO'nun geliştirilmesine yol açtı.
Doğrudan Tercih Optimizasyonu: Temel Kavramlar

Doğrudan Tercih Optimizasyonu https://arxiv.org/abs/2305.18290
Bu görsel, LLM çıktılarını insan tercihleriyle uyumlu hale getirmeye yönelik iki farklı yaklaşımı karşılaştırmaktadır: İnsan Geri Bildiriminden Güçlendirmeli Öğrenme (RLHF) ve Doğrudan Tercih Optimizasyonu (DPO). RLHF, dil modelinin politikasını yinelemeli geri bildirim döngüleri boyunca yönlendirmek için bir ödül modeline dayanırken, DPO, tercih verilerini kullanarak model çıktılarını doğrudan insan tercihli yanıtlarla eşleştirecek şekilde optimize eder. Bu karşılaştırma, her iki yöntemin güçlü yönlerini ve potansiyel uygulamalarını vurgulayarak, gelecekteki LLM öğrencilerinin insan beklentileriyle daha iyi uyum sağlamak için nasıl eğitilebileceğine dair içgörüler sunar.
DPO'nun arkasındaki temel fikirler:
a) Örtülü Ödül Modellemesi: DPO, dil modelinin kendisini örtülü bir ödül işlevi olarak ele alarak ayrı bir ödül modeline olan ihtiyacı ortadan kaldırır.
b) Politika Tabanlı Formülasyon: DPO, bir ödül işlevini optimize etmek yerine, tercih edilen yanıtların olasılığını en üst düzeye çıkarmak için doğrudan politikayı (dil modeli) optimize eder.
c) Kapalı Form Çözümü: DPO, yinelemeli RL güncelleme ihtiyacını ortadan kaldırarak optimum politikaya kapalı formda çözüm sağlayan matematiksel bir anlayıştan yararlanır.
DPO'nun Uygulanması: Pratik Kod Çözüm Yolu
Aşağıdaki görsel, PyTorch kullanarak DPO kayıp fonksiyonunu uygulayan bir kod parçacığını göstermektedir. Bu fonksiyon, dil modellerinin çıktıları insan tercihlerine göre nasıl önceliklendirdiğini iyileştirmede önemli bir rol oynar. İşte temel bileşenlerin bir dökümü:
- İşlev İmzası:
dpo_lossişlev, politika günlüğü olasılıkları da dahil olmak üzere çeşitli parametreleri alır (pi_logps), referans modeli günlüğü olasılıkları (ref_logps) ve tercih edilen ve tercih edilmeyen tamamlamaları temsil eden endeksler (yw_idxs,yl_idxs). Ek olarak, birbetaparametresi KL cezasının gücünü kontrol eder. - Günlük Olasılığı Çıkarma: Kod, hem politika hem de referans modellerinden tercih edilen ve tercih edilmeyen tamamlamalar için günlük olasılıklarını çıkarır.
- Günlük Oranı Hesaplaması: Tercih edilen ve tercih edilmeyen tamamlamalar için günlük olasılıkları arasındaki fark, hem politika hem de referans modelleri için hesaplanır. Bu oran optimizasyonun yönünü ve büyüklüğünü belirlemede kritik öneme sahiptir.
- Kayıp ve Ödül Hesaplaması: Kayıp şu şekilde hesaplanır:
logsigmoidÖdüller politika ve referans günlüğü olasılıkları arasındaki farkın ölçeklendirilmesiyle belirlenirkenbeta.

PyTorch kullanarak DPO kaybı işlevi
Bu hedeflere nasıl ulaştığını anlamak için DPO'nun ardındaki matematiğe bir göz atalım.
DPO'nun Matematiği
DPO, tercih öğrenme probleminin akıllıca bir yeniden formülasyonudur. İşte adım adım bir dökümü:
a) Başlangıç Noktası: KL-Kısıtlı Ödül Maksimizasyonu
Orijinal RLHF hedefi şu şekilde ifade edilebilir:
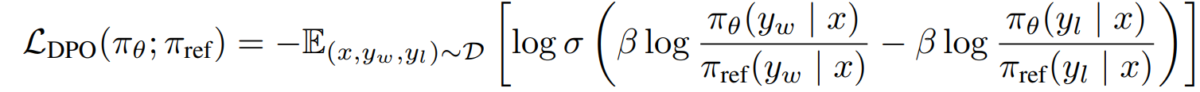
- πθ, optimize ettiğimiz politikadır (dil modeli)
- r(x,y) ödül fonksiyonudur
- πref bir referans politikasıdır (genellikle ilk SFT modeli)
- β KL sapma kısıtlamasının gücünü kontrol eder
b) Optimal Politika Formu: Bu hedefe yönelik en uygun politikanın şu şekilde olduğu gösterilebilir:
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))Burada Z(x) bir normalleştirme sabitidir.
c) Ödül Politikası İkililiği: DPO'nun temel anlayışı, ödül fonksiyonunu en uygun politika açısından ifade etmektir:
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))d) Tercih Modeli Tercihlerin Bradley-Terry modelini takip ettiğini varsayarsak, y1'i y2'ye tercih etme olasılığını şu şekilde ifade edebiliriz:
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))Burada σ lojistik fonksiyondur.
e) DPO Hedefi Ödül politikası ikiliğimizi tercih modeline koyarak DPO hedefine ulaşıyoruz:
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]Bu amaç, RL algoritmalarına gerek kalmadan standart gradyan iniş teknikleri kullanılarak optimize edilebilir.
DPO'nun uygulanması
DPO'nun arkasındaki teoriyi anladığımıza göre, şimdi bunu pratikte nasıl uygulayacağımıza bakalım. Python ve PyTorch bu örnek için:
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair.
"""
# Extract log probabilities for the preferred and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log probabilities for the model and the reference model
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
Zorluklar ve Gelecekteki Yönler
DPO, geleneksel RLHF yaklaşımlarına göre önemli avantajlar sunarken, hâlâ zorluklar ve daha fazla araştırma yapılması gereken alanlar bulunmaktadır:
a) Daha Büyük Modellere Ölçeklenebilirlik:
Dil modellerinin boyutu büyümeye devam ettikçe, DPO'yu yüz milyarlarca parametreye sahip modellere verimli bir şekilde uygulamak açık bir zorluk olmaya devam ediyor. Araştırmacılar aşağıdaki gibi teknikleri araştırıyorlar:
- Verimli ince ayar yöntemleri (örneğin, LoRA, önek ayarı)
- Dağıtılmış eğitim optimizasyonları
- Gradyan kontrol noktası belirleme ve karma hassasiyetli eğitim
LoRA'yı DPO ile kullanma örneği:
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
b) Çoklu Görev ve Az Çekim Uyarlaması:
Sınırlı tercih verileriyle yeni görevlere veya alanlara verimli bir şekilde uyum sağlayabilecek DPO tekniklerinin geliştirilmesi aktif bir araştırma alanıdır. Araştırılan yaklaşımlar şunları içerir:
- Hızlı adaptasyon için meta-öğrenme çerçeveleri
- DPO için istem tabanlı ince ayar
- Öğrenimi genel tercih modellerinden belirli alanlara aktarın
c) Belirsiz veya Çatışan Tercihlerin Ele Alınması:
Gerçek dünyadaki tercih verileri genellikle belirsizlikler veya çelişkiler içerir. Veri Koruma Görevlisi'nin bu tür verilere karşı dayanıklılığını artırmak hayati önem taşır. Potansiyel çözümler şunlardır:
- Olasılıksal tercih modellemesi
- Belirsizlikleri çözmek için aktif öğrenme
- Çoklu aracı tercihi toplama
Olasılıksal tercih modelleme örneği:
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
d) DPO'yu Diğer Hizalama Teknikleriyle Birleştirmek:
DPO'yu diğer hizalama yaklaşımlarıyla entegre etmek daha sağlam ve yetenekli sistemlere yol açabilir:
- Açık kısıtlamaların karşılanması için anayasal yapay zeka ilkeleri
- Karmaşık tercihlerin ortaya çıkarılması için tartışma ve yinelemeli ödül modellemesi
- Temel ödül işlevlerinin çıkarımını yapmak için ters takviyeli öğrenme
DPO'yu anayasal yapay zeka ile birleştirme örneği:
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):
super().__init__(model, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Usage
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement safety checking logic
unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5
constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Pratik Hususlar ve En İyi Uygulamalar
Gerçek dünya uygulamaları için DPO'yu uygularken aşağıdaki ipuçlarını göz önünde bulundurun:
a) Veri kalitesi: Tercih verilerinizin kalitesi çok önemlidir. Veri kümenizin:
- Çok çeşitli girdileri ve istenen davranışları kapsar
- Tutarlı ve güvenilir tercih açıklamalarına sahiptir
- Farklı tercih türlerini dengeler (örneğin, gerçekçilik, güvenlik, stil)
b) Hiperparametre Ayarı: DPO'nun RLHF'den daha az hiper parametresi olsa da ayarlama hala önemlidir:
- β (beta): Tercih memnuniyeti ile referans modelden sapma arasındaki dengeyi kontrol eder. Etrafındaki değerlerle başlayın 0.1-0.5.
- Öğrenme oranı: Standart ince ayardan daha düşük bir öğrenme oranı kullanın; genellikle 1e-6'dan 1e-5'e.
- Parti büyüklüğü: Daha büyük parti boyutları (32-128) genellikle tercih öğrenimi için iyi çalışır.
c) Yinelemeli İyileştirme: DPO yinelemeli olarak uygulanabilir:
- DPO kullanarak başlangıç modelini eğitme
- Eğitilen modeli kullanarak yeni yanıtlar oluşturun
- Bu yanıtlara ilişkin yeni tercih verileri toplayın
- Genişletilmiş veri kümesini kullanarak yeniden eğitin

Doğrudan Tercih Optimizasyonu Performansı
Bu görsel, GPT-4 gibi LLM programlarının performansını, Doğrudan Tercih Optimizasyonu (DPO), Denetimli İnce Ayar (SFT) ve Yakınsal Politika Optimizasyonu (PPO) dahil olmak üzere çeşitli eğitim tekniklerinde insan yargılarıyla karşılaştırmalı olarak göstermektedir. Tablo, GPT-4 çıktılarının, özellikle özetleme görevlerinde, insan tercihleriyle giderek daha uyumlu hale geldiğini ortaya koymaktadır. GPT-4 ve insan değerlendiriciler arasındaki uyum düzeyi, modelin insan değerlendiricilerle neredeyse insan tarafından oluşturulan içerik kadar uyumlu içerik üretme becerisini göstermektedir.
Vaka Çalışmaları ve Uygulamalar
DPO'nun etkinliğini göstermek için gerçek dünyadaki bazı uygulamalara ve bazı varyantlarına bakalım:
- Yinelemeli DPO: Snorkel (2023) tarafından geliştirilen bu değişken, ret örneklemesini DPO ile birleştirerek eğitim verileri için daha hassas bir seçim süreci sağlar. Tercih örneklemesinin birden fazla turu tekrarlanarak model daha iyi genelleştirilebilir ve gürültülü veya önyargılı tercihlere aşırı uyumdan kaçınılabilir.
- halka arz (Yinelemeli Tercih Optimizasyonu): Azar ve ark. tarafından tanıtıldı. (2023), IPO, tercihe dayalı optimizasyonda yaygın bir sorun olan aşırı uyumu önlemek için bir düzenleme terimi ekler. Bu uzantı, modellerin tercihlere bağlı kalma ve genelleme yeteneklerini koruma arasında bir denge kurmasına olanak tanır.
- KTO (Bilgi Aktarımı Optimizasyonu): Ethayarajh ve ark.'nın daha yeni bir çeşidi. (2023), KTO ikili tercihleri tamamen ortadan kaldırır. Bunun yerine, bilgiyi bir referans modelinden politika modeline aktarmaya, insani değerlerle daha sorunsuz ve daha tutarlı bir uyum için optimizasyona odaklanıyor.
- Etki Alanları Arası Öğrenim için Çok Modlu DPO Xu ve diğerleri tarafından. (2024): DPO'nun farklı yöntemler (metin, görüntü ve ses) genelinde uygulandığı ve modelleri farklı veri türleri genelinde insan tercihleriyle hizalamadaki çok yönlülüğünü gösteren bir yaklaşım. Bu araştırma, karmaşık, çok modlu görevleri yerine getirebilecek daha kapsamlı yapay zeka sistemleri oluşturmada DPO'nun potansiyelini vurguluyor.












