Prompt Mühendisliği
ChatGPT & İleri Düzeyli Prompt Mühendisliği: AI Evrimini Sürdürmek

OpenAI, devrim niteliğinde araçlar geliştirmede önemli bir rol oynamıştır, bunlar arasında OpenAI Gym gibi eğitim için tasarlanan takviye algoritmaları ve GPT-n modelleri bulunmaktadır. DALL-E gibi AI modelleri de dikkat çekmektedir, bu model metinsel girdilerden resimler oluşturur. OpenAI’nin ChatGPT adlı modeli, Büyük Dil Modelleri alanında önemli bir örnek olarak dikkat çekmektedir.
GPT-4: Prompt Mühendisliği
ChatGPT, sohbet botu manzarasını değiştirdi, kullanıcı girdilerine insan benzeri yanıtlar sunarak ve uygulamalarını çeşitli alanlara yayarak – yazılım geliştirme ve testten iş iletişimine, hatta şiir yaratmaya kadar.
İşletmeler ve bireyler elinde, GPT-4 gibi modeller, matematik ve biyoloji gibi konularda uzmanlaşmış sınırsız bir bilgi kaynağı olarak hizmet verebilir. Bu tür gelişmiş ve erişilebilir AI modelleri, iş, öğrenme ve yaratıcılık geleceğini yeniden tanımlamaya hazırdır.

GPT-4 gibi üretken modeller, mevcut girdilere dayanarak yeni verileri üretebilir. Bu ayırt edici özellik, metin, resim, müzik ve video üretimi dahil çeşitli görevleri üstlenmelerine olanak tanır.
OpenAI modelleri ve ChatGPT bağlamında, bir.prompt kullanıcıların modellere sağladığı girdi olarak tanımlanır, genellikle metin形式inde. Prompts, bu modeller tarafından üretilen çıktıyı kontrol etmenin birincil moyenidir, bu nedenle başarılı ve ilgili sohbetler için çok önemlidir.
Prompt Kalitesinin Etkisi
İyi tanımlanmış promt’ler, AI sistemleriyle faydalı ve anlamlı sohbetlere girmenin anahtarıdır. Kötü tanımlanmış promt’ler, kullanıcı için yararlı olmayan ve hatta yanlış içeriğe yol açabilecek çıktılara neden olabilir.
Prompt kalitesinin etkisini göstermek için, ChatGPT’ye verilen iki farklı promt’i karşılaştıralım. İlk promt, kötü tanımlanmış ve önceden bilgi varsayan, kullanıcı için potentially yararsız bir yanıt oluşturur. Öte yandan, ikinci promt daha fazla bağlam ve örnek sağlar, daha ilgili ve anlaşılabilir bir yanıt garantiler.
Prompt 1: “Bana Konvolüsyonel Sinir Ağları hakkında bilgi verin.”
Yanıt 1: “Konvolüsyonel Sinir Ağları (CNN’ler), tam bağlantılı katmanlardan ve havuzlama katmanlarından oluşan çok katmanlı perceptron ağlarıdır. Bunlar genellikle görüntü tanıma görevlerinde kullanılır. Süreç, girdi resimlerine filtreler uygulamayı ve bunları havuzlama katmanları kullanarak küçültmeyi içerir.”
Prompt 2: “Konvolüsyonel Sinir Ağları hakkında bilgi almak istiyorum, ancak Yapay Sinir Ağları hakkında önceden hiçbir bilgim yok. Lütfen bir başlangıç dostu açıklama yapın ve CNN’lerin görüntü tanıma görevlerinde nasıl kullanıldığına bir örnek verin.”
Yanıt 2: “Konvolüsyonel Sinir Ağları (CNN’ler), esas olarak görüntü tanıma görevleri için kullanılan bir tür sinir ağıdır. Diğer sinir ağlarından farklı olarak, bunlar convolutional katmanlar ve havuzlama katmanlarını kullanarak resimleri işlerler. Bir kedi resmi olduğunu düşünün. CNN’ler, filtreleri uygulayarak ve resimleri havuzlama katmanları kullanarak küçülterek, resimdeki farklı özellikleri, Örneğin, bıyıkları, kulakları ve kuyruğu, tanıyabilir. Bu işlem, CNN’lerin resimdeki nesneleri tanımak için son derece etkili olmasını sağlar.”
İki yanıtı karşılaştırdığımızda, iyi tanımlanmış bir promt’in daha ilgili ve kullanıcı dostu bir yanıt ile sonuçlandığı açıkça görülür. Prompt tasarımı ve mühendisliği, AI modellerinin çıktı kalitesini optimize etmeye yönelik büyüyen disiplinlerdir.
Bu makalenin sonraki bölümlerinde, Büyük Dil Modellerini (LLM’ler) rafine etmeye yönelik gelişmiş metodolojilere, Örneğin prompt mühendisliği teknikleri ve taktiklerine dalacağız. Bunlar, few-shot öğrenme, ReAct, zincir-düşünce, RAG ve daha fazlasını içerir.
İleri Düzeyli Mühendislik Teknikleri
Devam etmeden önce, LLM’lerle ilgili bir ana sorun olan ‘halüsinasyon’ hakkında bilgi sahibi olmak önemlidir. LLM’ler bağlamında ‘halüsinasyon’, bu modellerin gerçeklik veya verilen girdi bağlamına dayanmayan, ancak makul görünen çıktılar üretme eğilimini ifade eder.
Bu sorun, bir savunma avukatının ChatGPT’yi yasal araştırma için kullanmasıyla ilgili recent bir dava ile vurgulandı. AI aracı, halüsinasyon problemi nedeniyle başarısız oldu ve var olmayan yasal davaları引用 etti. Bu yanlış adım, prosedür sırasında önemli sonuçlar doğurdu ve güvenilirliği zayıflattı. Bu olay, AI sistemlerinde ‘halüsinasyon’ sorununu ele alma ihtiyacını vurgulamaktadır.
LLM’lerin bu yönlerini geliştirmeyi amaçlayan prompt mühendisliği tekniklerine bakışımız, bunların verimliliğini ve güvenliğini artırarak, bilgi çıkarımı gibi yenilikçi uygulamalara yol açmaktadır. Ayrıca, LLM’leri dış araçlar ve veri kaynaklarıyla entegre etmeyi kolaylaştırarak, potansiyel kullanımlarının kapsamını genişletmektedir.
Sıfır ve Az-Shot Öğrenme: Örnekle Optimizasyon
Üretken Ön-Eğitimli Transformerler (GPT-3), ‘az-shot öğrenme’ kavramını tanıtarak, önemli bir dönemeç noktası olarak kabul edilebilir. Bu yöntem, kapsamlı fine-tuning gerektirmeden etkili bir şekilde çalışabilme kabiliyeti nedeniyle oyun değiştiriciydi. GPT-3 çerçevesi, “Dil Modelleri Az-Shot Öğrencilerdir” adlı makalede tartışılmaktadır, burada yazarlar, modelin çeşitli kullanım örneklerinde, özel veri setleri veya kod gerekmeden nasıl başarılı olduğunu göstermektedir.
Fine-tuning, sürekli bir çaba gerektirir ve değişen kullanım örneklerini çözmek için kullanılır, ancak az-shot modeller, daha geniş bir uygulama yelpazesine daha kolay uyum sağlar. Fine-tuning bazı durumlarda güçlü çözümler sunabilir, ancak ölçekte pahalı olabilir, bu nedenle az-shot modellerin kullanımı, özellikle prompt mühendisliği ile entegre edildiğinde, daha pratik bir yaklaşım olabilir.
Imagine English’i Fransızca’ya çevirmeye çalışıyorsunuz. Az-shot öğrenmede, GPT-3’e birkaç çeviri örneği gibi “sea otter -> loutre de mer” sağlar. GPT-3, gelişmiş bir model olarak, daha sonra doğru çevirileri sağlayabilir. Sıfır-shot öğrenmede, hiçbir örnek verilmez ve GPT-3 hala İngilizce’yi Fransızca’ya etkili bir şekilde çevirebilir.
‘Az-shot öğrenme’ terimi, modelin öğrenmek için sınırlı sayıda örneğe sahip olduğu fikrine dayanır. Bu bağlamda ‘öğrenme’, modelin parametrelerini veya ağırlıklarını güncelleme anlamına gelmez, ancak modelin performansını etkiler.

GPT-3 Paper’den Az-Shot Öğrenme
Sıfır-shot öğrenme, bu kavramı bir adım öteye taşır. Sıfır-shot öğrenmede, modelde görev tamamlama örnekleri sağlanmaz. Model, yalnızca ilk eğitimine dayanarak iyi performans göstermesi beklenir, bu nedenle bu metod, açık alan soru-cevap senaryoları gibi ChatGPT için idealdir.
Çoklu örnek senaryolarında, bir model sıfır-shot öğrenmede başarılı olabilir ve az-shot veya tek-shot örneklerle de iyi performans gösterebilir. Bu yetenek, büyük modellerin çeşitli alanlarda potansiyel uygulamalarını artırmaktadır.
Sıfır-shot öğrenme yöntemleri giderek daha yaygın hale gelmektedir. Bu yöntemler, eğitim sırasında görülmemiş nesneleri tanıyabilme kabiliyetleriyle karakterize edilir. İşte bir Few-Shot Prompt örneği:
"Aşağıdaki İngilizce cümleleri Fransızca'ya çevirin:
'sea otter' Fransızca'da 'loutre de mer'
'sky' Fransızca'da 'ciel'
'cloud' Fransızca'da neye karşılık gelir?"
Modeli birkaç örnek ve ardından bir soru ile yönlendirerek, istenen çıktıyı üretmesini sağlayabiliriz. Bu durumda, GPT-3 muhtemelen ‘cloud’ü Fransızca’da ‘nuage’ olarak doğru bir şekilde çevirecektir.
Prompt mühendisliğinin çeşitli nüanslarına ve model performansı sırasında optimize edilmesindeki rolüne daha derinlemesine bakacağız. Ayrıca, maliyet etkili ve ölçeklenebilir çözümler oluşturmak için nasıl etkili bir şekilde kullanılabileceğini inceleyeceğiz.
GPT modellerindeki prompt mühendisliği tekniklerinin karmaşıklığını daha da keşfettikçe, son makalemiz ‘ChatGPT’de Prompt Mühendisliğine İlişkin Temel Kılavuz‘ı vurgulamak önemlidir. Bu kılavuz, çeşitli kullanım örneklerinde AI modellerini etkili bir şekilde yönlendirmek için stratejalar sağlar.
Önceki tartışmalarımızda, büyük dil modelleri (LLM’ler) için temel prompt yöntemlerini, yani sıfır-shot ve az-shot öğrenmeyi, ayrıca talimat prompting’i ele aldık. Bu teknikleri ustalıkla kullanmak, burada keşfedeceğimiz prompt mühendisliğinin daha karmaşık zorluklarını gezinmek için çok önemlidir.
Az-shot öğrenme, çoğu LLM’nin sınırlı bağlam penceresi nedeniyle sınırlı olabilir. Ayrıca, uygun önlemler alınmazsa, LLM’ler potansiyel olarak zararlı çıktı üretebilir. Ayrıca, birçok model, akıl yürütme görevleriyle veya çok adımlı talimatları takip etmekte zorluk çekebilir.
Bu kısıtlamalar göz önüne alındığında, zorlu görevleri çözmek için LLM’leri kullanmanın yolu, daha gelişmiş LLM’ler geliştirmek veya mevcut olanları rafine etmek olabilir, ancak bu önemli bir çaba gerektirebilir. Bu nedenle, soru ortaya çıkıyor: Mevcut modelleri daha iyi problem çözme için nasıl optimize edebiliriz?
Aynı derecede ilginç olan, bu tekniğin Unite AI’nin ‘AI Sanatı Ustalık: Midjourney ve Prompt Mühendisliğine İlişkin Kısa Bir Kılavuz‘ adlı makalesinde nasılcreative uygulamalarla etkileşime girdiğinin keşfedilmesidir, burada AI ve sanatın birleşiminin nasıl göz kamaştırıcı sanata yol açabileceği açıklanmaktadır.
Zincir-Düşünce Prompting
Zincir-düşünce prompting, büyük dil modellerinin (LLM’ler) içkin özerk özelliklerini kullanır, bunlar bir dizi içindeki sonraki kelimeyi öngörme konusunda uzmandır. Modeli düşünce sürecini açıklamaya促lemek, daha kapsamlı, metodik bir fikir üretimi ile sonuçlanır, bu da doğru bilgilere yakın bir şekilde hizalanır. Bu hizalama, modelin bilgiyi düşünceli ve sıralı bir şekilde işleme ve sunma eğiliminden kaynaklanır, tıpkı bir insan uzmanının karmaşık bir kavramı dinleyiciye adım adım açıklaması gibi. Basit bir ifade, “Adım adım açıklamaya çalış” genellikle bu daha ayrıntılı ve ayrıntılı çıktıyı tetiklemek için yeterlidir.
Sıfır-Shot Zincir-Düşünce Prompting
Geleneksel CoT prompting, önceden eğitim gerektirirken, bir ortaya çıkan alan sıfır-shot CoT prompting’tir. Bu yaklaşım, Kojima et al. (2022) tarafından ortaya atıldı ve orijinal promt’e “Adım adım düşünelim” ifadesini ekler.
Gelişmiş bir promt oluşturalım, burada ChatGPT, AI ve NLP araştırma makalelerinden ana noktaları özetlemeye görevlendirilsin.
Bu gösteride, modelin karmaşık bilgileri akademik metinlerden anlamlandırma ve özetleme yeteneğini kullanacağız. Az-shot öğrenme yaklaşımını kullanarak, ChatGPT’yi AI ve NLP araştırma makalelerinden ana noktaları özetlemeye öğreteceğiz:
1. Makale Başlığı: "Dikkat Her Şeydir"
Ana Nokta: Transformer modelini tanıttı, dizi dönüştürme görevleri için tekrarlayan katmanlara kıyasla dikkat mekanizmalarının önemini vurguladı.
2. Makale Başlığı: "BERT: Derin Bidirektif Transformerlerin Dil Anlama için Ön Eğitimi"
Ana Nokta: BERT'i tanıttı, derin bidirektif modellerin ön eğitiminin çeşitli NLP görevlerinde devlet-sanat sonuçlar elde etmede etkinliğini gösterdi.
Şimdi, bu örneklerin bağlamında, aşağıdaki makalenin ana noktalarını özetleyin:
Makale Başlığı: "Büyük Dil Modellerinde Prompt Mühendisliği: Bir İnceleme"
Bu promt, sadece bir düşünce zinciri kullanmakla kalmaz, aynı zamanda az-shot öğrenme yaklaşımını da modeli yönlendirmek için kullanır. AI ve NLP alanlarına odaklanarak, ChatGPT’yi karmaşık bir işlem olan araştırma makalelerini özetlemeye görevlendirir.
ReAct Prompt
ReAct, veya “Reason and Act”, Google tarafından “ReAct: Dil Modellerinde Akıl Yürütme ve Eylemi Birleştirme” adlı makalede tanıtıldı ve dil modellerinin bir görevle etkileşim şeklini devrimleştirerek, modeli hem sözel akıl yürütme izlerini hem de görev özgüllüğü eylemlerini dinamik olarak üretmeye teşvik etti.
Bir insan aşçıyı mutfakta hayal edin: onlar sadece bir dizi eylem gerçekleştirmez (sebze kesme, su kaynatma, malzeme karıştırma), aynı zamanda iç konuşma veya akıl yürütme yapar (“şimdi sebze doğranmış, şimdi tencereyi ocağa koyacağım”). Bu sürekli zihinsel diyalog, süreci planlamada, ani değişikliklere uyum sağlamada (“zeytinyağı yok, yağ kullanacağım”) ve görev sırasını hatırlamada yardımcı olur. ReAct, bu insan yeteneğini taklit eder, modelin yeni görevleri hızlı bir şekilde öğrenmesini ve insan gibi kararlar almasını sağlar.
ReAct, Chain-of-Thought (CoT) sistemlerinin ortak bir sorunu olan halüsinasyonu ele alır. CoT, etkili bir teknik olmasına rağmen, dış dünya ile etkileşime girme yeteneğinden yoksundur, bu da gerçeklikten uzaklaştırma ve hata yayılmasıyla sonuçlanabilir. ReAct ise, dış kaynaklarla etkileşime girerek bu soruna çözüm getirir, böylece sistemin akıl yürütmelerini doğrulamasına ve dış dünyadan alınan en son bilgilerle bilgisini güncellemesine olanak tanır.
ReAct’ın temel çalışması, HotpotQA gibi bir görevde açıklanabilir. Model, bir soru aldığında, soruyu yönetilebilir parçalara ayırır ve bir eylem planı oluşturur. Model, bir akıl yürütme izi (düşünce) üretir ve ilgili bir eylem belirler. Apple Remote hakkında Wikipedia’da bilgi aramaya karar verebilir (eylem) ve elde edilen bilgilerle anlayışını günceller (gözlem). Düşünce-eylem-gözlem adımlarının birden fazla tekrarıyla, ReAct, akıl yürütmeyi desteklemek için bilgi alabilir ve bir sonraki adımda ne alması gerektiğini güncelleyerek, görevi çözmek için gereken adımları gerçekleştirir.
Not:
HotpotQA , Wikipedia’dan türetilen ve AI sistemlerini karmaşık akıl yürütmeye eğitmek için tasarlanmış 113k soru-cevap çiftinden oluşan bir veri kümesidir. Öte yandan, CommonsenseQA 2.0, oyunlaştırma yoluyla oluşturulan ve AI modellerini yanıltmaya yönelik 14,343 evet/hayır sorusundan oluşur.
Süreç şöyle olabilir:
- Düşünce: “Apple Remote ve uyumlu cihazları araştırmam gerekiyor.”
- Eylem: “Apple Remote uyumlu cihazlar”ı dış bir kaynakta arar.
- Gözlem: Arama sonuçlarından Apple Remote ile uyumlu cihazların listesini alır.
- Düşünce: “Arama sonuçlarına göre, Apple Remote’un dışında da programı kontrol edebilecek diğer cihazlar var.”
Sonuç, dış dünya ile etkileşime dayalı, akıl yürütme temelli bir süreçtir, bu da daha doğru ve güvenilir yanıtlara yol açar.

Dört prompting yönteminin karşılaştırılması – Standart, Zincir-Düşünce, Eylem-Sadece ve ReAct, HotpotQA ve AlfWorld’de çözme (https://arxiv.org/pdf/2210.03629.pdf)
ReAct ajanlarının tasarımı, bu yeteneği nedeniyle uzmanlaşmış bir görevdir. Örneğin, bir sohbet aracı, ReAct modelinin temelini oluşturur ve sohbet belleği entegre ederek daha zengin etkileşimler sağlar. Ancak, bu görevin karmaşıklığı, Langchain gibi araçlarla basitleştirilir, bu da bu ajanların tasarımını standartlaştırır.
Baglam-Dostu Prompting
‘Baglam-Dostu Prompting için Büyük Dil Modelleri‘ makalesi, LLM’lerin bilgi temelli NLP görevilerinde önemli başarılar göstermesine rağmen, parametrik bilgiye aşırı bağımlılıkları, bağlamsal görevlerde yanılmalara yol açabileceğini vurgulamaktadır. Örneğin, bir dil modeli, eğitim verisi 2022 Dünya Kupası’ndan önceyse ve bağlam, Fransa’nın turnuvayı kazandığını belirtirse, model, önceden öğrendiği bilgiye dayanarak yanlış cevaplar verebilir.
Bu problem, bilgi çatışması olarak bilinen durumlarda belirgindir, burada bağlam, modelin önceden öğrendiği bilginin farklı olduğu gerçekleri içerir. Bir LLM, önceden 2018 Dünya Kupası kazananı hakkında bilgi sahibi ise ve bağlam, yeni kazanan hakkında bilgi içeriyorsa, model, önceden öğrendiği bilgiye dayanarak yanlış cevaplar verebilir.
Diğer bir sorun, bağlamın yeterli bilgi içermediği ve doğru cevap vermekte zorlandığı ‘tahmin ile birlikte tahmin’ durumudur. Örneğin, bir LLM, Microsoft’un kurucusu hakkında bilgi verilmesi gereken bir bağlamda, yeterli bilgi yoksa, cevap vermekte zorlanabilir.
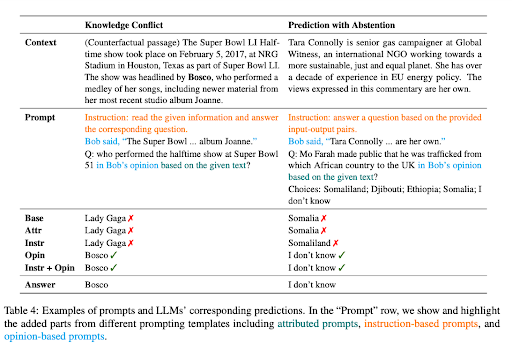
Bilgi Çatışması ve Çekilmenin Gücü Örnekleri
Bu senaryolarda LLM’lerin bağlamsal doğruluğunu artırmak için, araştırmacılar çeşitli prompting stratejileri önerdiler. Bu stratejiler, LLM’lerin yanıtlarını bağlama daha duyarlı hale getirmeyi amaçlar.
Bir strateji, promt’leri görüş olarak sormaktır, burada bağlam, bir anlatıcının ifadesi olarak yorumlanır ve soru, bu anlatıcının görüşü ile ilgilidir. Bu yaklaşım, LLM’nin dikkatini sunulan bağlama odaklar, önceden öğrendiği bilgilere başvurmak yerine.
Prompt’lere karşıt örnekler eklemek de, bilgi çatışması durumlarında bağlamsal doğruluğu artırmak için etkili bir yol olarak tanımlanmıştır. Bu örnekler, yanlış gerçekleri sunar ve modeli, bağlama dikkat ederek doğru yanıtlar üretmeye yönlendirir.
Talimat İnce Ayarlaması
Talimat ince ayarlaması, modeli spesifik talimatlar ile eğiten bir denetimli öğrenme aşamasıdır, Örneğin “Şafak ve gün batımı arasındaki farkı açıklayın.” Talimat, uygun bir cevap ile eşleştirilir, Örneğin “Şafak, güneşin sabah ufukta görünmeye başladığı andır, gün batımı ise güneşin akşam ufukta kaybolduğu andır.” Bu metod ile model, talimatlara uymayı ve bunları uygulamayı öğrenir.
Bu yaklaşım, LLM’leri promt etme şeklimizi önemli ölçüde etkiler, prompting stilinde radikal bir değişikliğe yol açar. Talimat ile ince ayarlanmış bir LLM, sıfır-shot görevleri hemen gerçekleştirebilir, sorunsuz görev performansı sağlar. Model henüz ince ayarlanmamışsa, birkaç örnek içeren bir az-shot öğrenme yaklaşımı gerekebilir, promt’e birkaç örnek ekleyerek modeli istenilen yanıta yönlendirmek için.
“Talimat Uyarlaması ile GPT-4” makalesi, GPT-4’ü kullanarak talimat-uyma verilerini LLM’leri ince ayarlamak için kullanma girişimini tartışmaktadır. 52.000 benzersiz talimat-uyma girişinden oluşan zengin bir veri kümesi kullandılar, hem İngilizce hem de Çince.
Veri kümesi, talimat ayarlamasında önemli bir rol oynamaktadır, özellikle LLaMA modelleri gibi açık kaynaklı LLM’lerin eğitilmesinde. Bu, sıfır-shot performansını geliştirerek, yeni görevlerde daha iyi sonuçlar elde edilmesini sağlar. Önemli projeler gibi Stanford Alpaca, Self-Instruct ayarlamasını etkili bir şekilde kullanmış, gelişmiş talimat-uyma öğretmen modelleri tarafından üretilen verileri kullanarak LLM’leri insan niyetine hizalamayı başarmıştır.

Talimat ayarlaması araştırmalarının birincil amacı, LLM’lerin sıfır-shot ve az-shot genellemelerini artırmaktır. Daha fazla veri ve model ölçeği, değerli içgörüler sağlayabilir. Mevcut GPT-4 veri boyutu 52K ve temel LLaMA model boyutu 7 milyar parametre ile, daha fazla GPT-4 talimat-uyma verisi toplamak ve bunu diğer veri kaynaklarıyla birleştirmek, daha büyük LLaMA modellerini eğitmek için büyük bir potansiyel vardır.
Yıldızlı Bağlam Promt’leri
‘Yıldızlı Bağlam Promt’leri’ kavramı, AI modeline ek bir bağlam katmanı sağlamak için belirli bilgileri girdi içinde etiketlemeyi içerir. Bu etiketler, AI için yol işaretleri gibi çalışır, bağlamı doğru bir şekilde yorumlamasını ve ilgili ve gerçek bir yanıt üretmesini sağlar.
Bir arkadaşınızla bir konu hakkında sohbet ettiğinizi hayal edin, Örneğin “satranç”. Bir ifade yapın ve sonra bunu bir referans ile etiketleyin, Örneğin “(kaynak: Wikipedia)”. Şimdi, arkadaşınız, yani AI modeli, bilgilerin nereden geldiğini bilir. Bu yaklaşım, AI’nın yanıtlarını daha güvenilir hale getirmeyi amaçlar, böylece yanlış gerçeklerin üretilme riskini azaltır.
Yıldızlı bağlam promt’lerinin benzersiz bir yönü, AI modellerinin ‘bağlamsal zekasını’ geliştirme potansiyelidir. Örneğin, makale, bu yöntemi çeşitli konulardan alınan bir dizi soru kullanarak gösterir, Bunlar, özetlenmiş Wikipedia makaleleri ve yeni yayınlanmış bir kitabın bölümleridir. Sorular etiketlenir, AI modeline ek bağlam sağlar.
Bu ek bağlam, yanıtların sadece doğru değil, aynı zamanda verilen bağlama uygun olmasını sağlamak için son derece yararlı olabilir, böylece AI’nın çıktısı daha güvenilir hale gelir.
SONUÇ: Vaat Edici Tekniklere ve Gelecek Yönlerine Bir Bakış
OpenAI’nin ChatGPT’si, Büyük Dil Modellerinin (LLM’ler) karmaşık görevleri şaşırtıcı bir verimlilikle çözebileceği potansiyeli sergiler. Az-shot öğrenme, ReAct prompting, zincir-düşünce ve STaR gibi gelişmiş teknikler, bu potansiyeli çeşitli uygulamalar boyunca kullanmamızı sağlar. Bu metodolojilerin nüanslarına daha derinlemesine bakarken, AI manzarasını şekillendirmekte ve insan-makine etkileşimlerini zenginleştirmekte nasıl etkili olduklarını keşfediyoruz.
Güvenilirlik ve güvenlik gibi zorluklara rağmen, bu AI modelleri, doğru prompt mühendisliği ile dönüşümsel araçlar olarak kanıtlanmıştır. Talimat ince ayarlaması, bağlamsal doğruluk ve dış veri kaynakları ile entegrasyon, bunların akıl yürütme, öğrenme ve uyum sağlama yeteneklerini daha da artırır.












