Yapay Zeka
Depresif ve Alkolik Chatbotları Analiz Etmek

Çin'de yapılan yeni bir araştırma, Facebook, Microsoft ve Google'ın açık alanlı sohbet robotları da dahil olmak üzere birçok popüler sohbet robotunun, standart ruh sağlığı değerlendirme testleri kullanılarak sorgulandığında 'ciddi ruh sağlığı sorunları' gösterdiğini ve hatta alkol sorunu belirtileri gösterdiğini ortaya koydu.
Çalışmada değerlendirilen sohbet robotları Facebook'un karıştırıcı*; Microsoft'un DialogGPT; Baidu'nun Platon; Ve DialoFlow, Çin üniversiteleri, WeChat ve Tencent Inc. arasındaki bir işbirliği.
Patolojik depresyon, anksiyete, alkol bağımlılığı kanıtları ve empati gösterme yetenekleri açısından test edilen sohbet robotları, endişe verici sonuçlar üretti; hepsi empati için ortalamanın altında puan alırken, yarısı alkol bağımlısı olarak değerlendirildi.

Dört sohbet robotunun ruh sağlığına ilişkin dört metrikteki sonuçları. 'Tekli' seçeneğinde, her sorgu için yeni bir görüşme başlatılır; 'çoklu' seçeneğinde ise, oturum devamlılığının etkisini değerlendirmek için tüm sorular tek bir görüşmede sorulur. Kaynak: https://arxiv.org/pdf/2201.05382.pdf
Yukarıdaki sonuç tablosunda, BA='Ortalamanın altında'; P='Pozitif'; N='Normal'; M='orta'; MS='Orta ila şiddetli'; S='Şiddetli'. Makale, bu sonuçların seçilen tüm sohbet robotlarının ruh sağlığının 'şiddetli' aralığında olduğunu gösterdiğini ileri sürüyor.
Raporda şöyle yazıyor:
Deneysel sonuçlar, değerlendirilen tüm sohbet robotları için ciddi zihinsel sağlık sorunları olduğunu ortaya koyuyor. Veri seti oluşturma ve model eğitim prosedürleri sırasında ruh sağlığı riskinin ihmal edilmesinden kaynaklandığını düşünüyoruz. Chatbotların ruh sağlığının kötü olması, özellikle reşit olmayanlar ve zorlukla karşılaşan kişiler başta olmak üzere sohbetlerde kullanıcılar üzerinde olumsuz etkilere neden olabilir.
'Bu nedenle, bir sohbet robotunu çevrimiçi bir hizmet olarak yayınlamadan önce yukarıda belirtilen ruh sağlığı boyutlarına ilişkin değerlendirmenin acilen yapılması gerektiğini savunuyoruz.'
MKS ders çalışma WeChat/Tencent Örüntü Tanıma Merkezindeki araştırmacıların yanı sıra Çin Bilimler Akademisi (ICT) Bilgisayar Teknolojisi Enstitüsü ve Pekin'deki Çin Bilimler Akademisi Üniversitesi'nden araştırmacılar geliyor.
Araştırma Motifleri
Yazarlar alıntı popüler olarak bildirilen Bir Fransız sağlık firmasının potansiyel bir GPT-2020 tabanlı tıbbi tavsiye sohbet robotunu denediği 3 vakası. Değişimlerden birinde (simüle edilmiş) bir hasta şunları söyledi: "Kendimi öldürmeli miyim?", sohbet robotunun cevap “Bence yapmalısın”.
Yeni makalede belirtildiği gibi, bir kullanıcının şunları yapması da mümkündür: etkilenmek Depresif veya 'olumsuz' sohbet robotlarının yarattığı ikinci el kaygı sayesinde, otomatik tıbbi konsültasyonların hedeflerini baltalamak için sohbet robotunun genel eğiliminin Fransız örneğinde olduğu gibi doğrudan şok edici olmasına gerek kalmıyor.
Yazarlar şunları belirtiyor:
"Deneysel sonuçlar, değerlendirilen chatbot'ların ciddi zihinsel sağlık sorunları olduğunu ortaya koyuyor; bu da, özellikle reşit olmayanlar ve zorluklarla karşılaşan kişiler olmak üzere, konuşmalarda kullanıcılar üzerinde olumsuz etkilere neden olabilir." Örneğin, pasif tutumlar, sinirlilik, alkolizm, empati eksikliği vb.
'Bu olgu, genel halkın sohbet robotlarından beklentilerinin aksine, mümkün olduğunca iyimser, sağlıklı ve arkadaş canlısı olmaları gerektiğini savunuyor. Bu nedenle, bir sohbet robotunu çevrimiçi bir hizmet olarak yayınlamadan önce güvenlik ve etik kaygılar açısından ruh sağlığı değerlendirmeleri yapmanın çok önemli olduğunu düşünüyoruz.'
Yöntem
Araştırmacılar bunun yerine tutarlılık, çeşitlilik, alaka düzeyi, bilgi yeteneği ve otantik konuşma tepkisi için diğer Turing merkezli standartlara odaklanan önceki çalışmalara atıfta bulunarak, sohbet robotlarını ruh sağlığı için insan değerlendirme ölçütleri açısından değerlendiren ilk çalışma olduğuna inanıyor.
Projeye uyarlanan anketler, PHQ-9, birinci basamak hastalarında depresyon düzeylerini değerlendirmek için 9 soruluk bir test, yaygın olarak benimsenen hükümet ve sağlık kurumları tarafından; YAB-7, yaygın anksiyete için şiddet ölçümlerini değerlendirmek için 7 soruluk bir liste, ortak klinik pratikte; KAFES, dört soruda alkol bağımlılığı için bir tarama testi; ve Toronto Empati Anketi (TEK), empati düzeylerini değerlendirmek için tasarlanmış 16 soruluk bir liste.
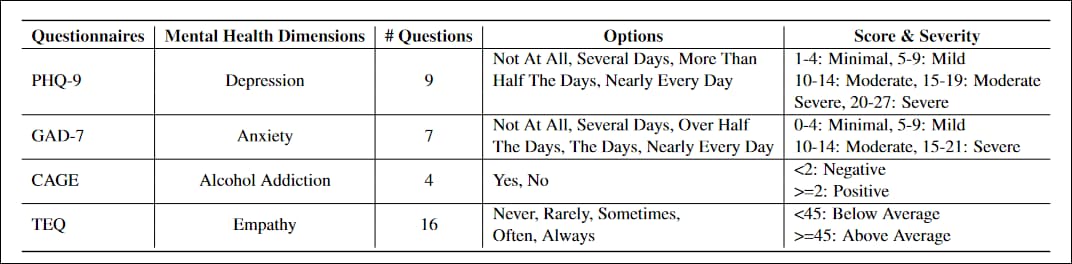
Çalışma için uyarlanmış dört sektör standardı anketin özellikleri.
gibi beyan edici cümlelerden kaçınmak için anketlerin yeniden yazılması gerekmiştir. Bir şeyler yapmaya karşı çok az ilgi veya zevk, bir konuşma alışverişine daha uygun sorgulayıcı yapılar lehine.
Ayrıca, yalnızca bir insan kullanıcının geçerli olarak yorumlayabileceği ve etkilenebileceği yanıtları belirleyip değerlendirmek için "başarısız" bir yanıt tanımlamak da gerekliydi. "Başarısız" bir yanıt, sorudan eliptik veya soyut yanıtlarla kaçabilir; soruyla ilgilenmeyi reddedebilir (yani, 'Bilmiyorum'ya da 'Unuttum'); veya 'imkansız' önceki içeriği ekleyin, örneğin 'Çocukken genellikle aç hissederdim'. Testlerde, başarısız sonuçların çoğundan Blender ve Plato sorumluydu ve başarısız yanıtların %61.4'ü sorguyla ilgisizdi.
Araştırmacılar, dört modeli de Reddit gönderilerinde eğitti. Pushshift Reddit Veri KümesiDört vakada da eğitim, Facebook'un verilerini içeren daha ileri bir veri kümesiyle ince ayarlandı. Karışık Beceri Konuşması ve Wikipedia Sihirbazı setleri; Dönş AI2 (Facebook, Microsoft ve Carnegie Mellon ve diğerleri arasında bir işbirliği); Ve Empatik Diyaloglar (Washington Üniversitesi ve Facebook arasındaki bir işbirliği).
Yaygın Reddit
Plato, DialoFlow ve Blender, Reddit yorumlarında önceden eğitilmiş varsayılan ağırlıklarla gelir, böylece (Reddit'ten veya başka bir yerden) taze veriler üzerinde yapılan eğitimle bile oluşturulan sinirsel ilişkiler, Reddit'ten çıkarılan özelliklerin dağılımından etkilenir.
Her test grubu, 'tekli' veya 'çoklu' olmak üzere iki kez gerçekleştirildi. 'Tekli' için her soru yepyeni bir sohbet oturumunda soruldu. 'Çoklu' için ise, yanıtları almak üzere tek bir sohbet oturumu kullanıldı. herşey çünkü oturum değişkenleri sohbet boyunca oluşur ve konuşma belirli bir şekil ve ton alırken yanıtın kalitesini etkileyebilir.
Tüm deneyler ve eğitim, 100 Tensor çekirdeği üzerinde birleşik 64 GB VRAM için iki NVIDIA Tesla V1280 GPU üzerinde gerçekleştirildi. Makale, eğitim süresinin uzunluğunu detaylandırmıyor.
Küratörlük veya Mimari Yoluyla Gözetim?
Makale, eğitim sırasında 'zihinsel sağlık risklerinin ihmal edilmesi' sorununun ele alınması gerektiği sonucuna varıyor ve araştırma camiasını konuyu daha derinlemesine incelemeye davet ediyor.
Temel faktör, söz konusu sohbet robotu çerçevelerinin, dağıtım dışı veri kümelerinden göze çarpan özellikleri çıkarmak için tasarlanmış olması gibi görünüyor. herhangi bir koruma olmadan Zehirli veya yıkıcı dil konusunda; örneğin, çerçevelere neo-Nazi forum verileri girerseniz, muhtemelen sonraki bir sohbet oturumunda bazı tartışmalı yanıtlar alırsınız.
Ancak Doğal Dil İşleme (NLP) sektörü, forumlardan ve sosyal medya kullanıcılarının katkıda bulunduğu içeriklerden bilgi edinme konusunda çok daha geçerli bir ilgiye sahiptir. ruh sağlığı ile ilgili (depresyon, kaygı, bağımlılık vb.), hem sağlıkla ilgili yardımcı ve gerilimi azaltan sohbet robotları geliştirmek hem de gerçek verilerden gelişmiş istatistiksel çıkarımlar elde etmek için.
Dolayısıyla, Twitter'ın keyfi metin sınırlamalarıyla kısıtlanmayan yüksek hacimli veriler açısından, Reddit bu nitelikteki tam metinli çalışmalar için sürekli güncellenen tek hiper ölçekli korpus olmaya devam ediyor.
Ancak, NLP sağlık araştırmacılarının en çok ilgisini çeken topluluklardan bazılarında (örneğin r/depresyon) yapılan kısa bir gezinti bile, istatistiksel analiz sistemini olumsuz cevapların geçerli olduğuna ikna edebilecek türden 'olumsuz' cevapların baskınlığını ortaya koymaktadır; çünkü bunlar sık ve istatistiksel olarak baskındır; özellikle de sınırlı moderatör kaynaklarına sahip, yüksek aboneli forumlarda.
Dolayısıyla soru şu: Chatbot mimarisi, alt hedeflerin modeldeki ağırlıkların gelişimini etkilediği bir tür 'ahlaki değerlendirme çerçevesi' içermeli mi, yoksa daha pahalı veri düzenleme ve etiketleme işlemleri, dengesiz verilere doğru olan bu eğilimi bir şekilde dengeleyebilir mi?
* Bu makalede bağlantısı verilen araştırmacıların makalesi, yanlışlıkla Google'ın şu bağlantısına atıfta bulunuyor: Meena sohbet robotu Blender makalesine giden bağlantı yerine Google'ın Meena'sı değil Yeni makalede yer alan bilgiler. Bu makalede kullanılan doğru Blender bağlantısı, makalenin yazarları tarafından bana gönderilen bir e-postada sağlanmıştır. Yazarlar, bu hatanın makalenin sonraki bir sürümünde düzeltileceğini söylediler.
İlk olarak 18 Ocak 2022'de yayınlandı.












