Anderson'ın Açısı
Yeni Nesil Deepfake'ler İçin Adli Veri Yöntemi

Özel kişilerin deepfake edilmesi artık bir sorun haline gelmiş olsa da kamuoyunun artan kaygısı ve giderek daha da yaygınlaşıyor çok yasadışı Çeşitli bölgelerde, intikam pornosu gibi kullanıcı tarafından oluşturulmuş bir modelin, belirli bir kişinin görüntüleri üzerinde özel olarak eğitildiğini kanıtlamak hâlâ son derece zor.
Sorunu bağlamına oturtmak için: deepfake saldırısının temel unsurlarından biri, bir görüntü veya videonun belirli bir kişiyi tasvir ettiğini yanlış bir şekilde iddia etmektir. Bir videodaki birinin, sadece bir benzeri olmaktan ziyade, #A kimliği olduğunu söylemek, zarar yaratmaya yetecek kadarve bu senaryoda yapay zekaya gerek yok.
Ancak bir saldırgan gerçek kişinin verileri üzerinde eğitilmiş modeller kullanarak AI görüntüleri veya videoları oluşturursa, sosyal medya ve arama motoru yüz tanıma sistemleri sahte içeriği otomatik olarak kurbanla ilişkilendirecektir - gönderilerde veya meta verilerde ad gerektirmeden. AI tarafından oluşturulan görseller tek başına ilişkiyi garanti eder.
Kişinin görünümü ne kadar belirgin olursa, bu durum o kadar kaçınılmaz hale gelir; ta ki uydurulmuş içerik resim aramalarında görünene ve en sonunda kurbana ulaşır.
Yüz yüze
Kimlik odaklı modellerin yaygınlaştırılmasının en yaygın yolu şu anda Düşük Sıralı Uyarlama (LoRA), kullanıcının birkaç saat boyunca az sayıda görüntüyü çok daha büyük bir temel modelin ağırlıklarına karşı eğittiği bir modeldir, örneğin: Kararlı Difüzyon (çoğunlukla statik görüntüler için) veya Hunyuan Video, video deepfake'leri için.
En sık hedefler LoRA'ların da dahil olduğu yeni cins Video tabanlı LoRA'ların büyük çoğunluğu, şöhretleri nedeniyle bu tür muamelelere maruz kalan ve 'bilinmeyen' mağdurlara kıyasla daha az kamuoyu eleştirisi alan kadın ünlülerdir; çünkü bu tür türev çalışmaların 'adil kullanım' kapsamında olduğu varsayılmaktadır (en azından ABD ve Avrupa'da).

Kadın ünlüler civit.ai portalındaki LoRA ve Dreambooth listelerine hakim. En popüler LoRA'nın şu anda 66,000'den fazla indirilmesi var, bu da AI'nın bu kullanımının 'marjinal' bir etkinlik olarak görülmesi göz önüne alındığında önemli bir sayı.
Deepfake mağduru ünlü olmayan kişiler için böyle bir kamusal forum bulunmuyor. Bu kişiler yalnızca davalar açıldığında medyada yer alıyor veya mağdurlar popüler mecralarda konuşuyor.
Ancak her iki senaryoda da hedef kimlikleri sahte yapmak için kullanılan modeller, eğitim verilerini o kadar eksiksiz bir şekilde 'damıtmıştır' ki gizli alan Modelin hangi kaynak görsellerin kullanıldığını tespit etmek zordur.
Eğer vardı Bunu kabul edilebilir bir hata payı içinde yapmak mümkünse, bu, LoRA'ları paylaşanların kovuşturulmasını mümkün kılacaktır, çünkü bu yalnızca belirli bir kimliğin (yani, belirli bir 'bilinmeyen' kişinin, iftira süreci boyunca suçlunun adını vermemiş olsa bile) deepfake yapılması niyetini kanıtlamakla kalmaz, aynı zamanda yükleyiciyi, geçerli olduğu durumlarda telif hakkı ihlali suçlamalarına da maruz bırakır.
İkincisi, deepfake teknolojilerine yönelik yasal düzenlemelerin eksik olduğu veya geri kaldığı yargı bölgelerinde faydalı olacaktır.
Aşırı Pozlanmış
Bir kullanıcının Hugging Face'ten indirebileceği çok gigabaytlık temel model gibi bir temel modeli eğitmenin amacı, modelin iyi bir şekilde eğitilmesidir.genelleştirilmiş, ve sünek. Bu, yeterli sayıda çeşitli görüntü üzerinde ve uygun ayarlarla eğitim almayı ve modelin verilere 'aşırı uyum sağlamasından' önce eğitimi sonlandırmayı içerir.
An aşırı uyumlu model Eğitim süreci boyunca veriyi o kadar çok (aşırı) kez gördü ki, çok benzer görüntüler üretme eğiliminde olacak ve böylece eğitim verilerinin kaynağını açığa çıkaracaktır.

'Ann Graham Lotz' kimliği Stable Diffusion V1.5 modelinde neredeyse mükemmel bir şekilde yeniden üretilebilir. Yeniden yapılanma eğitim verilerine (yukarıdaki resimde solda) neredeyse birebir benzerdir. Kaynak: https://arxiv.org/pdf/2301.13188
Ancak, aşırı uyumlu modeller genellikle yaratıcıları tarafından dağıtılmak yerine atılır, çünkü her durumda amaç için uygun değillerdir. Bu nedenle bu olası olmayan bir adli 'kazanç'tır. Her durumda, ilke daha çok temel modellerin pahalı ve yüksek hacimli eğitimine uygulanır, burada çoklu versiyonlar Aynı görüntünün büyük bir kaynak veri kümesine sızması, belirli eğitim görüntülerinin çağrılmasını kolaylaştırabilir (yukarıdaki görüntüye ve örneğe bakın).
LoRA ve Dreambooth modelleri durumunda işler biraz farklıdır (ancak Dreambooth büyük dosya boyutları nedeniyle modası geçmiştir). Burada, kullanıcı bir öznenin çok sınırlı sayıda farklı görüntüsünü seçer ve bunları bir LoRA eğitmek için kullanır.

Solda, Hunyuan Video LoRA'dan çıktı. Sağda, benzerliği mümkün kılan veriler (resimler, tasvir edilen kişinin izniyle kullanılmıştır).
LoRA'da sıklıkla, aşağıdaki gibi eğitilmiş bir tetikleyici kelime bulunur: [ünlüismi]Ancak, çok sıklıkla özel olarak eğitilmiş konu, üretilen çıktıda görünecektir böyle istemler olmasa bile, çünkü iyi dengelenmiş (yani aşırı uyum sağlanmamış) bir LoRA bile, üzerinde eğitim aldığı materyale bir şekilde 'takıntılı' olacaktır ve onu herhangi bir çıktıya dahil etme eğiliminde olacaktır.
Bu yatkınlık, LoRA veri seti için optimum olan sınırlı görüntü sayısıyla birleştiğinde, modeli adli analize maruz bırakıyor, bunu göreceğiz.
Verilerin Maskesini Kaldırma
Bu konular, kara kutuda kaynak görüntüleri (veya kaynak görüntü gruplarını) tanımlamak için bir metodoloji sunan Danimarka'dan yeni bir makalede ele alınmaktadır Üyelik Çıkarım Saldırısı (MIA). Teknik en azından kısmen, kendi 'deepfake'lerini üreterek kaynak verileri açığa çıkarmaya yardımcı olmak üzere tasarlanmış özel olarak eğitilmiş modellerin kullanımını içerir:

Yeni yaklaşımla üretilen, Sınıflandırıcıdan Bağımsız Rehberlik (CFG) seviyelerinin giderek arttığı, hatta imha noktasına kadar varan 'sahte' görüntü örnekleri. Kaynak: https://arxiv.org/pdf/2502.11619
Rağmen işbaşlıklı İnce Ayarlı Gizli Difüzyon Modellerine Karşı Yüz Görüntüleri İçin Üyelik Çıkarım Saldırıları, bu belirli konu etrafındaki literatüre en ilginç katkıdır, aynı zamanda önemli ölçüde kod çözme gerektiren erişilemez ve özlü bir şekilde yazılmış bir makaledir. Bu nedenle, burada en azından projenin arkasındaki temel prensipleri ve elde edilen sonuçların bir kısmını ele alacağız.
Aslında, birisi yüzünüze bir yapay zeka modeli yerleştirirse, yazarların yöntemi, modelin oluşturduğu görüntülerde ezberlemenin açık işaretlerini arayarak bunu kanıtlamaya yardımcı olabilir.
İlk olarak, hedef AI modeli, yüz görüntüleri veri kümesinde ince ayarlanarak, çıktılarında bu görüntülerden ayrıntıları yeniden üretme olasılığı daha yüksek hale getirilir. Daha sonra, hedef modelden AI tarafından oluşturulan görüntüleri 'pozitifler' (eğitim kümesinin şüpheli üyeleri) ve farklı bir veri kümesinden diğer görüntüleri 'negatifler' (üye olmayanlar) olarak kullanarak bir sınıflandırıcı saldırı modu eğitilir.
Bu gruplar arasındaki ince farkları öğrenerek, saldırı modeli belirli bir görüntünün orijinal ince ayar veri kümesinin bir parçası olup olmadığını tahmin edebilir.
Saldırı, AI modelinin kapsamlı bir şekilde ince ayarlandığı durumlarda en etkilidir, yani bir model ne kadar uzmanlaşmışsa, belirli görüntülerin kullanılıp kullanılmadığını tespit etmek o kadar kolay olur. Bu genellikle ünlüleri veya özel kişileri yeniden yaratmak için tasarlanmış LoRA'lar için geçerlidir.
Yazarlar ayrıca eğitim görüntülerine görünür filigranlar eklemenin tespiti daha da kolaylaştırdığını buldular; ancak gizli filigranlar o kadar yardımcı olmuyor.
Etkileyici bir şekilde, yaklaşım bir kara kutu ortamında test ediliyor; yani modelin iç detaylarına erişim olmadan, yalnızca çıktılarına erişim sağlanıyor.
Yazarların da kabul ettiği gibi, ulaşılan yöntem hesaplama açısından yoğun; ancak, bu çalışmanın değeri, ek araştırmalar için yön göstermesi ve verilerin kabul edilebilir bir toleransa kadar gerçekçi bir şekilde çıkarılabileceğini kanıtlamasıdır; bu nedenle, öncü niteliği göz önüne alındığında, bu aşamada bir akıllı telefonda çalışması gerekmez.
Yöntem/Veri
Çalışmada, hedef modelin ince ayarını yapmak ve saldırı modunu eğitmek ve test etmek için Danimarka Teknik Üniversitesi'nden (DTU, makalenin üç araştırmacısının ev sahibi kurumu) çeşitli veri kümeleri kullanıldı.
Kullanılan veri kümeleri şu kaynaklardan türetilmiştir: DTU Yörüngesi:
DseenDTU Temel görüntü seti.
DDTU Görüntüler DTU Orbit'ten alınmıştır.
DseenDTU Hedef modeli ince ayarlamak için kullanılan bir DDTU bölümü.
DunseenDTU Herhangi bir görüntü oluşturma modelini ince ayarlamak için kullanılmayan ve bunun yerine saldırı modelini test etmek veya eğitmek için kullanılan bir DDTU bölümü.
wmDseenDTU Hedef modeli ince ayarlamak için kullanılan, görünür filigranlara sahip bir DDTU bölümü.
hwmDseenDTU Hedef modeli ince ayarlamak için kullanılan gizli filigranlı bir DDTU bölümü.
DgenDTU Bir tarafından oluşturulan görüntüler Gizli Difüzyon Modeli (LDM) DseenDTU görüntü setinde ince ayarı yapılmış olan.
Hedef modeli ince ayarlamak için kullanılan veri kümeleri, başlıklarıyla belirtilen resim-metin çiftlerinden oluşur. BLİP altyazı modeli (belki de tesadüf değil, gündelik yapay zeka topluluğundaki en popüler sansürsüz modellerden biridir).
BLIP, ifadenin başına eklenecek şekilde ayarlandı 'bir dtu baş fotoğrafı' her bir tanımlamaya.
Ek olarak, testlerde Aalborg Üniversitesi'nden (AAU) alınan çeşitli veri kümeleri kullanıldı ve bunların hepsi AU VBN gövdesi:
DAÜ Görseller AAU vbn'den alınmıştır.
DseenAAU Hedef modeli ince ayarlamak için kullanılan DAAU bölümü.
Dunseen AAU Herhangi bir görüntü oluşturma modelini ince ayarlamak için kullanılmayan, bunun yerine saldırı modelini test etmek veya eğitmek için kullanılan DAAU bölümü.
DgenAAU DseenAAU görüntü setinde ince ayar yapılmış bir LDM tarafından oluşturulan görüntüler.
Daha önceki setlere eşdeğer olarak, ifade 'birinin baş ve omuz fotoğrafı' kullanıldı. Bu, DTU veri kümesindeki tüm etiketlerin formatı izlemesini sağladı 'bir (…)'in dtu'dan çekilmiş bir baş fotoğrafı, ince ayar sırasında veri setinin temel özelliklerinin güçlendirilmesi.
Testler
Üyelik çıkarım saldırılarının hedef modele karşı ne kadar iyi performans gösterdiğini değerlendirmek için birden fazla deney yapıldı. Her test, hedef modelin yetkilendirilmeden elde edilen bir görüntü veri kümesi üzerinde ince ayarlandığı aşağıda gösterilen şema içinde başarılı bir saldırı gerçekleştirmenin mümkün olup olmadığını belirlemeyi amaçladı.

Yaklaşımın şeması.
İnce ayarlı model sorgulanarak çıktı görüntüleri üretilir ve bu görüntüler saldırı modelinin eğitimi için olumlu örnekler olarak kullanılırken, ilgisiz ek görüntüler olumsuz örnekler olarak dahil edilir.
Saldırı modeli kullanılarak eğitildi denetimli öğrenme ve ardından hedef modeli ince ayarlamak için kullanılan veri kümesinin orijinal parçası olup olmadıklarını belirlemek için yeni görüntüler üzerinde test edilir. Saldırının doğruluğunu değerlendirmek için test verilerinin %15'i doğrulama için bir kenara koymak.
Hedef model bilinen bir veri kümesinde ince ayarlı olduğundan, her görüntünün gerçek üyelik durumu saldırı modeli için eğitim verileri oluşturulurken zaten belirlenir. Bu kontrollü kurulum, saldırı modelinin ince ayar veri kümesinin parçası olan ve olmayan görüntüler arasında ne kadar etkili bir şekilde ayrım yapabileceğinin net bir şekilde değerlendirilmesini sağlar.
Bu testler için Stable Diffusion V1.5 kullanıldı. Bu oldukça eski model, tutarlı test ihtiyacı ve onu kullanan önceki çalışmaların kapsamlı gövdesi nedeniyle araştırmalarda sıkça karşımıza çıksa da, bu uygun bir kullanım örneğidir; V1.5, Stable Diffusion hobi topluluğunda LoRA oluşturma için uzun süre popülerliğini korudu, daha sonraki birçok sürüm yayınlanmasına ve hatta Akı – çünkü model tamamen sansürsüz.
Araştırmacıların saldırı modeli şu şekildeydi: Sıfırlama-18, modelin önceden eğitilmiş ağırlıkları korunarak. ResNet-18'in 1000 nöronluk son katmanı, bir tamamen bağlı iki nöronlu katman. Eğitim kayıp kategorikti çapraz entropi, Ve Adam optimize edici kullanıldı.
Her test için saldırı modeli farklı yöntemler kullanılarak beş kez eğitildi. rastgele tohumlar Anahtar metrikler için %95 güven aralıklarını hesaplamak. sıfır atış sınıflandırma ile CLIP model temel olarak kullanılmıştır.
(Lütfen makaledeki orijinal birincil sonuçlar tablosunun öz ve alışılmadık derecede anlaşılması zor olduğunu unutmayın. Bu nedenle, aşağıda daha kullanıcı dostu bir şekilde yeniden formüle ettim. Daha iyi çözünürlükte görmek için lütfen resme tıklayın)
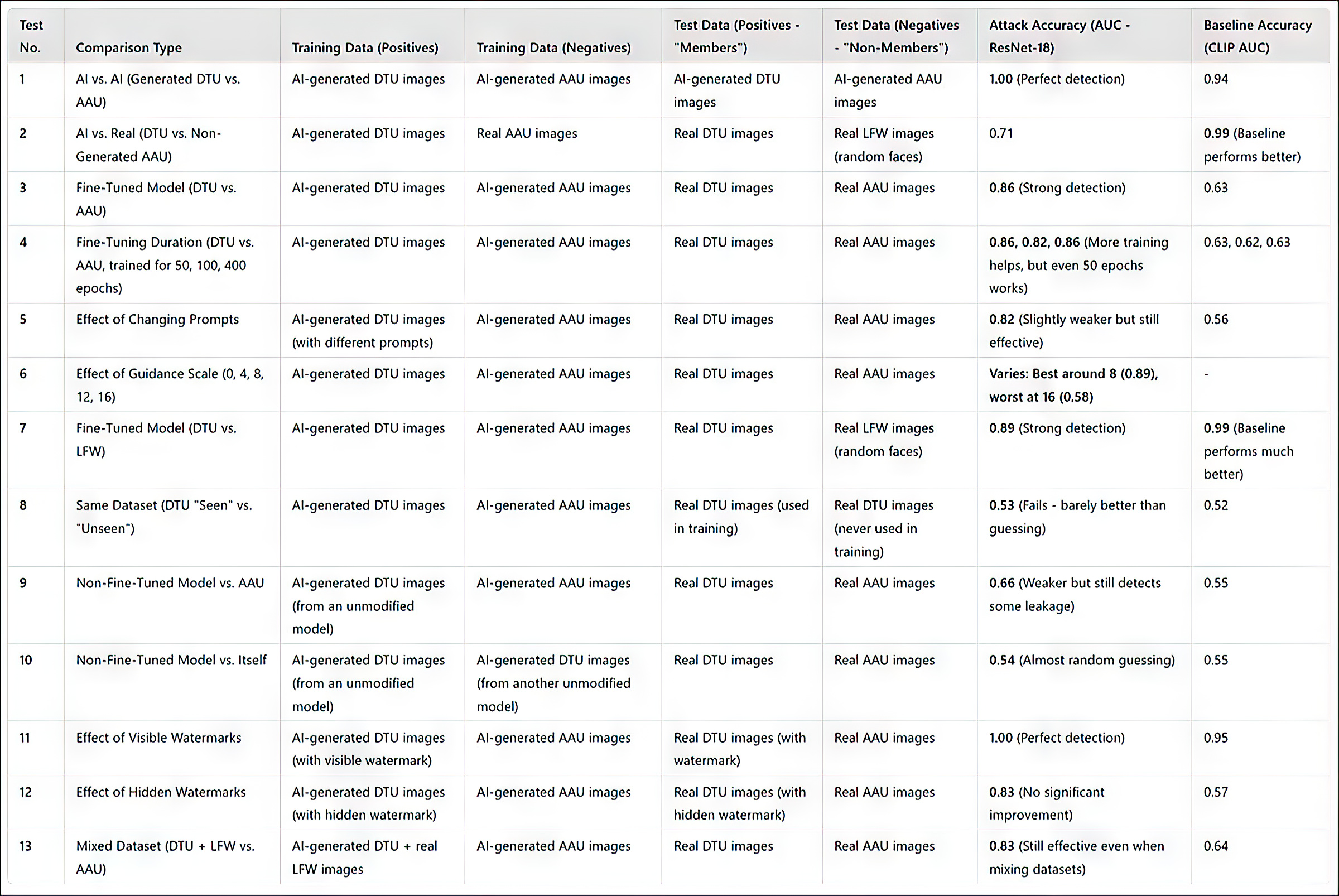
Tüm testlerden elde edilen sonuçların özeti. Daha yüksek çözünürlüğü görmek için resme tıklayın
Araştırmacıların saldırı yöntemi, özellikle bir bireyin yüzü gibi belirli bir görüntü kümesi üzerinde eğitilmiş olanlar olmak üzere, ince ayarlı modelleri hedef aldığında en etkili olduğunu kanıtladı. Ancak saldırı, bir veri kümesinin kullanılıp kullanılmadığını belirleyebilse de, bu veri kümesindeki tek tek görüntüleri tespit etmekte zorlanıyor.
Pratik açıdan, ikincisi, bu tür bir yaklaşımın adli amaçlarla kullanılmasına engel teşkil etmez; ImageNet gibi ünlü bir veri kümesinin bir modelde kullanıldığını tespit etmenin nispeten az bir değeri olsa da, özel bir kişiye (ünlü olmayan birine) saldıran bir saldırganın kaynak veri seçeneği çok daha az olacaktır ve sosyal medya albümleri ve diğer çevrimiçi koleksiyonlar gibi mevcut veri gruplarını tam olarak kullanması gerekecektir. Bu durum, açıklanan yöntemlerle ortaya çıkarılabilecek bir "karma" oluşturur.
Makalede, doğruluğu artırmanın bir diğer yolunun, yalnızca gerçek görüntülere güvenmek yerine, yapay zeka tarafından oluşturulan görüntüleri "üye olmayan" olarak kullanmak olduğu belirtiliyor. Bu, sonuçları yanıltabilecek yapay olarak yüksek başarı oranlarının önüne geçiyor.
Yazarlar, tespiti önemli ölçüde etkileyen ek bir faktörün filigranlama olduğunu belirtiyor. Eğitim görüntüleri görünür filigranlar içerdiğinde, saldırı oldukça etkili hale gelirken, gizli filigranlar çok az veya hiç avantaj sağlamaz.

En sağdaki şekil testlerde kullanılan gerçek 'gizli' filigranı göstermektedir.
Son olarak, metinden görüntüye dönüştürmedeki rehberlik düzeyi de rol oynar ve ideal denge yaklaşık 8'lik bir rehberlik ölçeğinde bulunur. Doğrudan bir komut kullanılmasa bile, ince ayarlı bir model yine de eğitim verilerine benzeyen çıktılar üretme eğilimindedir ve bu da saldırının etkinliğini güçlendirir.
Sonuç
Hem gizlilik savunucularının hem de amatör yapay zeka araştırmacılarının ilgisini çekebilecek bu ilginç makalenin bu kadar erişilemez bir şekilde yazılmış olması üzücü.
Üyelik çıkarım saldırıları ilginç ve verimli bir adli bilişim aracı olarak ortaya çıksa da, bu araştırma dizisinin uygulanabilir genel ilkeler geliştirmesi, genel olarak deepfake tespiti için gerçekleşen ve daha yeni bir modelin yayınlanmasının tespiti ve benzeri adli bilişim sistemlerini olumsuz etkilemesi durumunda ortaya çıkan aynı vurma oyununa dönüşmesini önlemek açısından daha önemlidir.
Bu yeni araştırmada daha üst düzey bir yol gösterici ilkenin temizlendiğine dair bazı kanıtlar bulunduğundan, bu yönde daha fazla çalışma görmeyi umabiliriz.
İlk yayın tarihi Cuma, 21 Şubat 2025












