
AI 101
Vad är CNN (Convolutional Neural Networks)?
Du kanske har undrat hur Facebook eller Instagram automatiskt kan känna igen ansikten i en bild, eller hur Google låter dig söka på webben efter liknande bilder bara genom att ladda upp ett eget foto. Dessa funktioner är exempel på datorseende och de drivs av konvolutionella neurala nätverk (CNN). Men vad exakt är konvolutionella neurala nätverk? Låt oss ta en djupdykning i arkitekturen hos ett CNN och förstå hur de fungerar.
Vad är neurala nätverk?
Innan vi börjar prata om konvolutionella neurala nätverk, låt oss ta en stund för att definiera vanliga neurala nätverk. Det finns en annan artikel om ämnet tillgängliga neurala nätverk, så vi ska inte gå för djupt in på dem här. Men för att kortfattat definiera dem är de beräkningsmodeller inspirerade av den mänskliga hjärnan. Ett neuralt nätverk fungerar genom att ta in data och manipulera data genom att justera "vikter", som är antaganden om hur indatafunktionerna är relaterade till varandra och objektets klass. När nätverket tränas justeras vikternas värden och de kommer förhoppningsvis att konvergera till vikter som exakt fångar sambanden mellan funktioner.
Det är så ett neuralt nätverk för feed-forward fungerar, och CNN består av två halvor: ett feed-forward neuralt nätverk och en grupp av faltningslager.
Vad är Convolution Neural Networks (CNN)?
Vilka är de "falsningar" som händer i ett faltningsneuralt nätverk? En faltning är en matematisk operation som skapar en uppsättning vikter, i huvudsak skapar en representation av delar av bilden. Denna uppsättning vikter kallas en kärna eller ett filter. Filtret som skapas är mindre än hela inmatningsbilden och täcker bara en undersektion av bilden. Värdena i filtret multipliceras med värdena i bilden. Filtret flyttas sedan över för att bilda en representation av en ny del av bilden, och processen upprepas tills hela bilden har täckts.
Ett annat sätt att tänka på detta är att föreställa sig en tegelvägg, där klossarna representerar pixlarna i inmatningsbilden. Ett "fönster" skjuts fram och tillbaka längs väggen, som är filtret. De tegelstenar som är synliga genom fönstret är pixlarna som har sitt värde multiplicerat med värdena i filtret. Av denna anledning kallas denna metod för att skapa vikter med ett filter ofta som tekniken för "skjutfönster".
Utdata från filtren som flyttas runt hela ingångsbilden är en tvådimensionell matris som representerar hela bilden. Denna array kallas a "funktionskarta".
Varför veck är väsentliga
Vad är syftet med att skapa veck? Konvolutioner är nödvändiga eftersom ett neuralt nätverk måste kunna tolka pixlarna i en bild som numeriska värden. Funktionen hos faltningsskikten är att omvandla bilden till numeriska värden som det neurala nätverket kan tolka och sedan extrahera relevanta mönster från. Syftet med filtren i det konvolutionella nätverket är att skapa en tvådimensionell uppsättning värden som kan överföras till de senare lagren i ett neuralt nätverk, de som lär sig mönstren i bilden.
Filter och kanaler
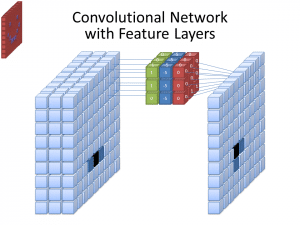
Foto: cecebur via Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)
CNN:er använder inte bara ett filter för att lära sig mönster från ingångsbilderna. Flera filter används, eftersom de olika arrayerna som skapas av de olika filtren leder till en mer komplex, rik representation av ingångsbilden. Vanliga antal filter för CNN är 32, 64, 128 och 512. Ju fler filter det finns, desto fler möjligheter har CNN att undersöka indata och lära av dem.
En CNN analyserar skillnaderna i pixelvärden för att bestämma gränserna för objekt. I en gråskalebild skulle CNN bara titta på skillnaderna i svart och vitt, ljust till mörkt. När bilderna är färgbilder tar CNN inte bara hänsyn till mörker och ljus, utan måste också ta hänsyn till de tre olika färgkanalerna – röd, grön och blå – också. I det här fallet har filtren 3 kanaler, precis som bilden själv gör. Antalet kanaler som ett filter har kallas dess djup, och antalet kanaler i filtret måste matcha antalet kanaler i bilden.
Konvolutionellt neuralt nätverk (CNN) arkitektur
Låt oss ta en titt på den kompletta arkitekturen för ett konvolutionellt neuralt nätverk. Ett faltningslager finns i början av varje faltningsnätverk, eftersom det är nödvändigt att omvandla bilddata till numeriska arrayer. Men faltningsskikt kan också komma efter andra faltningsskikt, vilket innebär att dessa skikt kan staplas ovanpå varandra. Att ha flera faltningsskikt innebär att utdata från ett skikt kan genomgå ytterligare faltningar och grupperas i relevanta mönster. I praktiken betyder detta att när bilddata fortsätter genom de faltande lagren, börjar nätverket "känna igen" mer komplexa egenskaper hos bilden.
De tidiga lagren i ett ConvNet är ansvariga för att extrahera funktionerna på låg nivå, såsom pixlarna som utgör enkla linjer. Senare lager i ConvNet kommer att sammanfoga dessa linjer till former. Den här processen att gå från analys på ytnivå till analys på djupnivå fortsätter tills ConvNet känner igen komplexa former som djur, mänskliga ansikten och bilar.
Efter att data har passerat genom alla faltningsskikten fortsätter den in i den tätt anslutna delen av CNN. De tätt sammankopplade lagren är hur ett traditionellt neuralt nätverk med feed-forward ser ut, en serie noder som är uppdelade i lager som är anslutna till varandra. Data fortsätter genom dessa tätt sammankopplade lager, som lär sig mönstren som extraherades av de konvolutionella lagren, och på så sätt blir nätverket kapabelt att känna igen objekt.










