
Inteligjenca artificiale
YOLOv7: Algoritmi më i avancuar i zbulimit të objekteve?

6 korriku 2022 do të shënohet si një pikë referimi në historinë e AI, sepse ishte në këtë ditë kur u publikua YOLOv7. Që nga fillimi i tij, YOLOv7 ka qenë tema më e nxehtë në komunitetin e zhvilluesve të Computer Vision dhe për arsyet e duhura. YOLOv7 tashmë po konsiderohet si një moment historik në industrinë e zbulimit të objekteve.
Pas pak Punimi YOLOv7 u botua, ai u shfaq si modeli më i shpejtë dhe më i saktë i zbulimit të kundërshtimeve në kohë reale. Por si i kalon YOLOv7 paraardhësit e tij? Çfarë e bën YOLOv7 kaq efikas në kryerjen e detyrave të vizionit kompjuterik?
Në këtë artikull do të përpiqemi të analizojmë modelin YOLOv7 dhe të përpiqemi të gjejmë përgjigjen se pse YOLOv7 tani po bëhet standard i industrisë? Por përpara se të mund t'i përgjigjemi kësaj, do të duhet të hedhim një vështrim në historinë e shkurtër të zbulimit të objekteve.
Çfarë është Zbulimi i Objekteve?
Zbulimi i objekteve është një degë në vizionin kompjuterik që identifikon dhe lokalizon objektet në një imazh ose një skedar video. Zbulimi i objekteve është blloku ndërtues i aplikacioneve të shumta duke përfshirë makinat vetë-drejtuese, mbikëqyrjen e monitoruar dhe madje edhe robotikën.
Një model i zbulimit të objekteve mund të klasifikohet në dy kategori të ndryshme: detektorë me një goditje, detektorë me shumë goditje.
Zbulimi i objekteve në kohë reale
Për të kuptuar me të vërtetë se si funksionon YOLOv7, është thelbësore që ne të kuptojmë objektivin kryesor të YOLOv7, "Zbulimi i objekteve në kohë reale”. Zbulimi i objekteve në kohë reale është një komponent kyç i vizionit kompjuterik modern. Modelet e zbulimit të objekteve në kohë reale përpiqen të identifikojnë dhe lokalizojnë objektet me interes në kohë reale. Modelet e zbulimit të objekteve në kohë reale e bënë me të vërtetë efikase për zhvilluesit që të gjurmojnë objektet me interes në një kornizë lëvizëse si një video ose një hyrje e drejtpërdrejtë e mbikëqyrjes.

Modelet e zbulimit të objekteve në kohë reale janë në thelb një hap përpara nga modelet konvencionale të zbulimit të imazhit. Ndërsa i pari përdoret për të gjurmuar objektet në skedarët video, ky i fundit lokalizon dhe identifikon objektet brenda një kornize të palëvizshme si një imazh.
Si rezultat, modelet e zbulimit të objekteve në kohë reale janë vërtet efikase për analitikën e videove, automjetet autonome, numërimin e objekteve, gjurmimin e shumë objekteve dhe shumë më tepër.
Çfarë është YOLO?
YOLO ose "Ju shikoni vetëm një herë” është një familje e modeleve të zbulimit të objekteve në kohë reale. Koncepti YOLO u prezantua për herë të parë në vitin 2016 nga Joseph Redmon, dhe ishte biseda e qytetit pothuajse menjëherë sepse ishte shumë më i shpejtë dhe shumë më i saktë se algoritmet ekzistuese të zbulimit të objekteve. Nuk kaloi shumë kohë përpara se algoritmi YOLO u bë një standard në industrinë e vizionit kompjuterik.

Koncepti themelor që propozon algoritmi YOLO është përdorimi i një rrjeti nervor nga skaji në fund duke përdorur kutitë kufizuese dhe probabilitetet e klasave për të bërë parashikime në kohë reale. YOLO ishte i ndryshëm nga modeli i mëparshëm i zbulimit të objekteve në kuptimin që propozoi një qasje të ndryshme për të kryer zbulimin e objekteve duke ripërdorur klasifikuesit.
Ndryshimi në qasje funksionoi pasi YOLO shpejt u bë standardi i industrisë pasi hendeku i performancës midis vetes dhe algoritmeve të tjera të zbulimit të objekteve në kohë reale ishin domethënëse. Por cila ishte arsyeja pse YOLO ishte kaq efikase?
Kur krahasohen me YOLO, algoritmet e zbulimit të objekteve në atë kohë përdorën Rrjetet e Propozimit të Rajonit për të zbuluar rajone të mundshme me interes. Procesi i njohjes u krye më pas për secilin rajon veç e veç. Si rezultat, këto modele shpesh kryenin përsëritje të shumëfishta në të njëjtin imazh, dhe rrjedhimisht mungesa e saktësisë dhe koha më e lartë e ekzekutimit. Nga ana tjetër, algoritmi YOLO përdor një shtresë të vetme të lidhur plotësisht për të kryer parashikimin menjëherë.
Si funksionon YOLO?
Ka tre hapa që shpjegojnë se si funksionon një algoritëm YOLO.
Riformulimi i zbulimit të objektit si një problem i vetëm regresioni
La Algoritmi YOLO përpiqet të riformulojë zbulimin e objektit si një problem të vetëm regresioni, duke përfshirë pikselat e imazhit, probabilitetet e klasave dhe koordinatat kufizuese të kutisë. Prandaj, algoritmi duhet të shikojë imazhin vetëm një herë për të parashikuar dhe lokalizuar objektet e synuara në imazhe.
Arsyeton imazhin globalisht
Për më tepër, kur algoritmi YOLO bën parashikime, ai arsyeton imazhin globalisht. Është i ndryshëm nga teknikat e bazuara në propozim rajonal dhe rrëshqitës pasi algoritmi YOLO sheh imazhin e plotë gjatë trajnimit dhe testimit në grupin e të dhënave dhe është në gjendje të kodojë informacionin kontekstual rreth klasave dhe mënyrën se si ato shfaqen.
Përpara YOLO, Fast R-CNN ishte një nga algoritmet më të njohura të zbulimit të objekteve që nuk mund të shihte kontekstin më të madh në imazh, sepse përdorte gabimet e arnimeve të sfondit në një imazh me një objekt. Kur krahasohet me algoritmin Fast R-CNN, YOLO është 50% më i saktë kur bëhet fjalë për gabimet e sfondit.
Përgjithëson përfaqësimin e objekteve
Së fundi, algoritmi YOLO synon gjithashtu të përgjithësojë paraqitjet e objekteve në një imazh. Si rezultat, kur një algoritëm YOLO u ekzekutua në një grup të dhënash me imazhe natyrore dhe u testua për rezultatet, YOLO ia kaloi modelet ekzistuese R-CNN me një diferencë të gjerë. Kjo është për shkak se YOLO është shumë i përgjithësueshëm, shanset që ai të prishet kur zbatohet në inpute të papritura ose domene të reja ishin të pakta.
YOLOv7: Çfarë ka të re?
Tani që kemi një kuptim themelor se çfarë janë modelet e zbulimit të objekteve në kohë reale dhe cili është algoritmi YOLO, është koha për të diskutuar algoritmin YOLOv7.
Optimizimi i procesit të trajnimit
Algoritmi YOLOv7 jo vetëm që përpiqet të optimizojë arkitekturën e modelit, por synon gjithashtu optimizimin e procesit të trajnimit. Ai synon përdorimin e moduleve dhe metodave të optimizimit për të përmirësuar saktësinë e zbulimit të objekteve, duke forcuar koston për trajnimin, duke ruajtur koston e ndërhyrjes. Këto module optimizimi mund të quhen a çantë me dhurata të trajnueshme.
Caktim i etiketës së drejtuar nga plumbi i trashë deri në fine
Algoritmi YOLOv7 planifikon të përdorë një caktim të ri të etiketës së drejtuar nga plumbi i trashë në të imët në vend të konvencionales Caktimi dinamik i etiketës. Është kështu sepse me caktimin dinamik të etiketës, trajnimi i një modeli me shtresa të shumta daljeje shkakton disa probleme, më e zakonshme prej tyre është se si të caktohen objektivat dinamikë për degë të ndryshme dhe rezultatet e tyre.
Ri-parametrizim i modelit
Ri-parametrizimi i modelit është një koncept i rëndësishëm në zbulimin e objekteve dhe përdorimi i tij në përgjithësi ndiqet me disa çështje gjatë trajnimit. Algoritmi YOLOv7 planifikon të përdorë konceptin e Rruga e përhapjes së gradientit për të analizuar politikat e riparametrizimit të modelit i aplikueshëm për shtresa të ndryshme në rrjet.
Zgjerimi dhe Shkallëzimi i Komponuar
Algoritmi YOLOv7 prezanton gjithashtu metodat e shkallëzimit të zgjeruar dhe të përbërë për të përdorur dhe përdorur në mënyrë efektive parametrat dhe llogaritjet për zbulimin e objekteve në kohë reale.

YOLOv7: Punë e ngjashme
Zbulimi i objekteve në kohë reale
YOLO është aktualisht standardi i industrisë dhe shumica e detektorëve të objekteve në kohë reale vendosin algoritme YOLO dhe FCOS (Zbulimi i Objekteve me Një Fazë Plotësisht Konvolutional). Një detektor objektesh në kohë reale të teknologjisë së fundit zakonisht ka karakteristikat e mëposhtme
- Arkitektura e rrjetit më e fortë dhe më e shpejtë.
- Një metodë efektive e integrimit të veçorive.
- Një metodë e saktë e zbulimit të objekteve.
- Një funksion i fuqishëm i humbjes.
- Një metodë efikase e caktimit të etiketës.
- Një metodë efektive e trajnimit.
Algoritmi YOLOv7 nuk përdor metoda të mësimit dhe distilimit të vetë-mbikëqyrur që shpesh kërkojnë sasi të mëdha të dhënash. Anasjelltas, algoritmi YOLOv7 përdor një metodë të trajnueshme me bagazhe pa pagesë.
Ri-parametrizim i modelit
Teknikat e ri-parametrizimit të modelit konsiderohen si një teknikë ansambli që bashkon module të shumta llogaritëse në një fazë interferenci. Teknika mund të ndahet më tej në dy kategori: ansambël në nivel modeli, ansambël në nivel moduli.
Tani, për të marrë modelin përfundimtar të ndërhyrjes, teknika e riparametizimit në nivel modeli përdor dy praktika. Praktika e parë përdor të dhëna të ndryshme trajnimi për të trajnuar modele të shumta identike, dhe më pas mesatarizon peshat e modeleve të trajnuara. Përndryshe, praktika tjetër mesatarizon peshat e modeleve gjatë përsëritjeve të ndryshme.
Ri-parametralizimi i nivelit të modulit po fiton popullaritet të jashtëzakonshëm kohët e fundit sepse ndan një modul në degë të ndryshme të moduleve, ose degë të ndryshme identike gjatë fazës së trajnimit, dhe më pas vazhdon të integrojë këto degë të ndryshme në një modul ekuivalent gjatë ndërhyrjes.
Megjithatë, teknikat e riparametrizimit nuk mund të aplikohen për të gjitha llojet e arkitekturës. Është arsyeja pse Algoritmi YOLOv7 përdor teknika të reja të riparametrizimit të modelit për të hartuar strategji të lidhura të përshtatshme për arkitektura të ndryshme.
Shkallëzimi i modelit
Shkallëzimi i modelit është procesi i rritjes ose uljes së një modeli ekzistues në mënyrë që të përshtatet në pajisje të ndryshme kompjuterike. Shkallëzimi i modelit në përgjithësi përdor një sërë faktorësh si numri i shtresave (thellësi), madhësia e imazheve hyrëse (zgjidhje), numri i piramidave tipare (fazë), dhe numri i kanaleve (gjerësi). Këta faktorë luajnë një rol vendimtar në sigurimin e një shkëmbimi të balancuar për parametrat e rrjetit, shpejtësinë e ndërhyrjes, llogaritjen dhe saktësinë e modelit.
Një nga metodat më të përdorura të shkallëzimit është NAS ose Kërkimi i Arkitekturës së Rrjetit që kërkon automatikisht faktorë të përshtatshëm të shkallëzimit nga motorët e kërkimit pa ndonjë rregull të komplikuar. E meta kryesore e përdorimit të NAS është se është një qasje e shtrenjtë për kërkimin e faktorëve të përshtatshëm të shkallëzimit.
Pothuajse çdo model ri-parametralizimi i modelit analizon faktorët individualë dhe unikë të shkallëzimit në mënyrë të pavarur, dhe për më tepër, madje i optimizon këta faktorë në mënyrë të pavarur. Kjo është për shkak se arkitektura NAS punon me faktorë shkallëzues jo të ndërlidhur.
Vlen të përmendet se modelet e bazuara në lidhje si VoVNet or DenseNet ndryshoni gjerësinë e hyrjes së disa shtresave kur thellësia e modeleve është e shkallëzuar. YOLOv7 punon në një arkitekturë të propozuar të bazuar në lidhje, dhe për këtë arsye përdor një metodë të shkallëzimit të përbërë.

Figura e përmendur më sipër krahason rrjete të zgjeruara efikase të grumbullimit të shtresave (E-ELAN) të modeleve të ndryshme. Metoda e propozuar E-ELAN ruan shtegun e transmetimit të gradientit të arkitekturës origjinale, por synon të rrisë kardinalitetin e veçorive të shtuara duke përdorur konvolucionin grupor. Procesi mund të përmirësojë veçoritë e mësuara nga harta të ndryshme dhe mund ta bëjë më tej përdorimin e llogaritjeve dhe parametrave më efikas.
Arkitektura YOLOv7
Modeli YOLOv7 përdor si bazë modelet YOLOv4, YOLO-R dhe Scaled YOLOv4. YOLOv7 është rezultat i eksperimenteve të kryera në këto modele për të përmirësuar rezultatet dhe për ta bërë modelin më të saktë.
Rrjeti i zgjeruar dhe efikas i grumbullimit të shtresave ose E-ELAN
E-ELAN është blloku themelor i ndërtimit të modelit YOLOv7 dhe rrjedh nga modelet tashmë ekzistuese për efikasitetin e rrjetit, kryesisht ELAN.
Konsideratat kryesore gjatë hartimit të një arkitekture efikase janë numri i parametrave, densiteti llogaritës dhe sasia e llogaritjes. Modele të tjera gjithashtu marrin në konsideratë faktorë si ndikimi i raportit të kanalit hyrës/dalës, degët në rrjetin e arkitekturës, shpejtësia e ndërhyrjes në rrjet, numri i elementeve në tensorët e rrjetit konvolucionar dhe më shumë.
La CSPVoNet modeli jo vetëm që merr në konsideratë parametrat e lartpërmendur, por gjithashtu analizon rrugën e gradientit për të mësuar më shumë veçori të ndryshme duke mundësuar peshat e shtresave të ndryshme. Qasja lejon që ndërhyrjet të jenë shumë më të shpejta dhe të sakta. Të MOMENTI arkitektura synon të dizenjojë një rrjet efikas për të kontrolluar rrugën më të shkurtër të gradientit më të gjatë në mënyrë që rrjeti të jetë më efektiv në mësim dhe konvergim.
ELAN ka arritur tashmë një fazë të qëndrueshme pavarësisht nga numri i grumbullimit të blloqeve llogaritëse dhe gjatësia e shtegut të gradientit. Gjendja e qëndrueshme mund të shkatërrohet nëse blloqet llogaritëse grumbullohen në mënyrë të pakufizuar dhe shkalla e përdorimit të parametrave do të ulet. Të Arkitektura e propozuar E-ELAN mund ta zgjidhë problemin pasi përdor zgjerimin, përzierjen dhe bashkimin e kardinalitetit për të përmirësuar vazhdimisht aftësinë e të mësuarit të rrjetit duke ruajtur rrugën origjinale të gradientit.
Për më tepër, kur krahasohet arkitektura e E-ELAN me ELAN, ndryshimi i vetëm është në bllokun llogaritës, ndërsa arkitektura e shtresës së tranzicionit është e pandryshuar.
E-ELAN propozon zgjerimin e kardinalitetit të blloqeve llogaritëse dhe zgjerimin e kanalit duke përdorur konvolucioni në grup. Harta e veçorive më pas do të llogaritet dhe do të përzihet në grupe sipas parametrit të grupit dhe më pas do të bashkohet së bashku. Numri i kanaleve në secilin grup do të mbetet i njëjtë si në arkitekturën origjinale. Së fundi, grupet e hartave të veçorive do të shtohen për të kryer kardinalitetin.
Shkallëzimi i modelit për modelet e bazuara në lidhje
Shkallëzimi i modelit ndihmon në rregullimi i atributeve të modeleve që ndihmon në gjenerimin e modeleve sipas kërkesave, dhe të shkallëve të ndryshme për të përmbushur shpejtësitë e ndryshme të ndërhyrjeve.

Figura flet për shkallëzimin e modelit për modele të ndryshme të bazuara në lidhje. Siç mundeni në figurën (a) dhe (b), gjerësia e daljes së bllokut llogaritës rritet me një rritje në shkallëzimin e thellësisë së modeleve. Si rezultat, gjerësia e hyrjes së shtresave të transmetimit është rritur. Nëse këto metoda zbatohen në arkitekturën e bazuar në lidhje, procesi i shkallëzimit kryhet në thellësi dhe është paraqitur në figurën (c).
Kështu mund të konkludohet se nuk është e mundur të analizohen faktorët e shkallëzimit në mënyrë të pavarur për modelet e bazuara në lidhje, dhe përkundrazi ata duhet të konsiderohen ose analizohen së bashku. Prandaj, për një model të bazuar në lidhje, është e përshtatshme për të përdorur metodën përkatëse të shkallëzimit të modelit të përbërë. Përveç kësaj, kur faktori i thellësisë është i shkallëzuar, kanali i daljes së bllokut gjithashtu duhet të shkallëzohet.
Çantë Trainable of Freebies
Një çantë me dhurata falas është një term që zhvilluesit përdorin për të përshkruar një grup metodash ose teknikash që mund të ndryshojnë strategjinë ose koston e trajnimit në një përpjekje për të rritur saktësinë e modelit. Pra, cilat janë këto çanta me dhurata të trajnueshme në YOLOv7? Le t'i hedhim një sy.
Konvolucioni i ri-parametralizuar i planifikuar
Algoritmi YOLOv7 përdor shtigjet e përhapjes së rrjedhës së gradientit për të përcaktuar si të kombinoni në mënyrë ideale një rrjet me konvolucionin e riparametralizuar. Kjo qasje nga YOLov7 është një përpjekje për të kundërshtuar Algoritmi RepConv që megjithëse ka performuar qetësisht në modelin VGG, performon dobët kur aplikohet drejtpërdrejt në modelet DenseNet dhe ResNet.
Për të identifikuar lidhjet në një shtresë konvolucionale, Algoritmi RepConv kombinon konvolucionin 3×3 dhe konvolucionin 1×1. Nëse analizojmë algoritmin, performancën e tij dhe arkitekturën, do të vërejmë se RepConv shkatërron bashkimi në DenseNet dhe pjesa e mbetur në ResNet.

Imazhi i mësipërm përshkruan një model të ri-parametralizuar të planifikuar. Mund të shihet se algoritmi YOLov7 zbuloi se një shtresë në rrjet me lidhje ose lidhje të mbetura nuk duhet të ketë një lidhje identiteti në algoritmin RepConv. Si rezultat, është e pranueshme të kaloni me RepConvN pa lidhje identiteti.
I trashë për ndihmës dhe gjobë për humbjen e plumbit
Mbikëqyrje e thellë është një degë në shkencën kompjuterike që shpesh gjen përdorim në procesin e trajnimit të rrjeteve të thella. Parimi themelor i mbikëqyrjes së thellë është se ai shton një kokë shtesë ndihmëse në shtresat e mesme të rrjetit së bashku me peshat e cekëta të rrjetit me humbjen e asistentit si udhërrëfyes. Algoritmi YOLOv7 i referohet kokës që është përgjegjëse për daljen përfundimtare si koka drejtuese, dhe koka ndihmëse është koka që ndihmon në stërvitje.
Duke ecur përpara, YOLOv7 përdor një metodë të ndryshme për caktimin e etiketës. Në mënyrë konvencionale, caktimi i etiketave është përdorur për të gjeneruar etiketa duke iu referuar drejtpërdrejt të vërtetës bazë dhe në bazë të një grupi të caktuar rregullash. Megjithatë, në vitet e fundit, shpërndarja dhe cilësia e inputit të parashikimit luan një rol të rëndësishëm për të krijuar një etiketë të besueshme. YOLOv7 gjeneron një etiketë të butë të objektit duke përdorur parashikimet e kutisë kufizuese dhe të së vërtetës bazë.
Për më tepër, metoda e re e caktimit të etiketës së algoritmit YOLOv7 përdor parashikimet e kokës së plumbit për të drejtuar si prizën ashtu edhe kokën ndihmëse. Metoda e caktimit të etiketës ka dy strategji të propozuara.
Lead Head Guided Label Assigner
Strategjia bën llogaritjet në bazë të rezultateve të parashikimit të kreut kryesor dhe të vërtetës bazë, dhe më pas përdor optimizimin për të gjeneruar etiketa të buta. Këto etiketa të buta përdoren më pas si model trajnimi për kokën e plumbit dhe kokën ndihmëse.
Strategjia funksionon mbi supozimin se për shkak se drejtuesi kryesor ka një aftësi më të madhe të të mësuarit, etiketat që gjeneron duhet të jenë më përfaqësuese dhe të ndërlidhen midis burimit dhe objektivit.
Përcaktues i etiketës së drejtuar nga koka e plumbit të trashë në të imët
Kjo strategji gjithashtu bën llogaritjet në bazë të rezultateve të parashikimit të kreut kryesor, dhe të vërtetës bazë, dhe më pas përdor optimizimin për të gjeneruar etiketa të buta. Megjithatë, ka një ndryshim kyç. Në këtë strategji, ekzistojnë dy grupe etiketash të buta, nivel i trashë, etiketë e imët.
Etiketa e trashë krijohet duke relaksuar kufizimet e kampionit pozitiv
procesi i caktimit që trajton më shumë rrjete si objektiva pozitive. Është bërë për të shmangur rrezikun e humbjes së informacionit për shkak të fuqisë më të dobët të të mësuarit të drejtuesit ndihmës.

Figura e mësipërme shpjegon përdorimin e një qese të trajnueshme me dhurata falas në algoritmin YOLOv7. Ai përshkruan trashë për kokën ndihmëse dhe fine për kokën e plumbit. Kur krahasojmë një model me kokën ndihmëse (b) me modelin normal (a), do të vërejmë se skema në (b) ka një kokë ndihmëse, ndërsa nuk është në (a).
Figura (c) përshkruan caktuesin e përbashkët të pavarur të etiketës ndërsa figura (d) dhe figura (e) përfaqësojnë përkatësisht Cakuesin e udhëhequr nga plumbi dhe caktuesin e udhëhequr nga plumbi i trashë deri në fine të përdorur nga YOLOv7.
Çanta të tjera Trainable of Freebies
Përveç atyre që u përmendën më lart, algoritmi YOLOv7 përdor çanta shtesë falas, megjithëse ato nuk ishin propozuar nga ata fillimisht. Ata janë
- Normalizimi i grupit në teknologjinë e aktivizimit Conv-Bn: Kjo strategji përdoret për të lidhur një shtresë konvolucionale drejtpërdrejt me shtresën e normalizimit të grupit.
- Njohuri të nënkuptuara në YOLOR: YOLOv7 kombinon strategjinë me hartën e veçorive Convolutional.
- Modeli EMA: Modeli EMA përdoret si model referimi përfundimtar në YOLOv7, megjithëse përdorimi i tij parësor do të përdoret në metodën mesatare të mësuesit.
YOLOv7: Eksperimente
Instalimi eksperimental
Algoritmi YOLOv7 përdor Të dhënat e Microsoft COCO për trajnim dhe vërtetim modelin e tyre të zbulimit të objekteve dhe jo të gjitha këto eksperimente përdorin një model të trajnuar paraprakisht. Zhvilluesit përdorën grupin e të dhënave të trenit 2017 për trajnim dhe përdorën të dhënat e vërtetimit të 2017 për zgjedhjen e hiperparametrave. Së fundi, performanca e rezultateve të zbulimit të objekteve YOLOv7 krahasohet me algoritmet më të fundit për zbulimin e objekteve.
Zhvilluesit krijuan një model bazë për GPU edge (YOLOv7-vogël), GPU normale (YOLOv7) dhe GPU cloud (YOLOv7-W6). Për më tepër, algoritmi YOLOv7 përdor gjithashtu një model bazë për shkallëzimin e modelit sipas kërkesave të ndryshme të shërbimit, dhe merr modele të ndryshme. Për algoritmin YOLOv7, shkallëzimi i stivës bëhet në qafë dhe përbërësit e propozuar përdoren për të përmirësuar thellësinë dhe gjerësinë e modelit.
Vijat bazë
Algoritmi YOLOv7 përdor modelet e mëparshme YOLO dhe algoritmin e zbulimit të objekteve YOLOR si bazë të tij.

Figura e mësipërme krahason bazën e modelit YOLOv7 me modelet e tjera të zbulimit të objekteve dhe rezultatet janë mjaft të dukshme. Kur krahasohet me Algoritmi YOLOv4, YOLOv7 jo vetëm që përdor 75% më pak parametra, por gjithashtu përdor 15% më pak llogaritje dhe ka 0.4% saktësi më të lartë.
Krahasimi me modelet moderne të detektorëve të objekteve

Figura e mësipërme tregon rezultatet kur YOLOv7 krahasohet me modelet moderne të zbulimit të objekteve për GPU-të e lëvizshme dhe të përgjithshme. Mund të vërehet se metoda e propozuar nga algoritmi YOLOv7 ka rezultatin më të mirë të shkëmbimit të shpejtësisë dhe saktësisë.
Studimi i ablacionit: Metoda e propozuar e shkallëzimit të kompleksit

Figura e paraqitur më sipër krahason rezultatet e përdorimit të strategjive të ndryshme për shkallëzimin e modelit. Strategjia e shkallëzimit në modelin YOLOv7 rrit thellësinë e bllokut llogaritës me 1.5 herë dhe shkallëzon gjerësinë me 1.25 herë.
Kur krahasohet me një model që rrit vetëm thellësinë, modeli YOLOv7 performon më mirë me 0.5% ndërsa përdor më pak parametra dhe fuqi llogaritëse. Nga ana tjetër, kur krahasohet me modelet që rrisin vetëm thellësinë, saktësia e YOLOv7 është përmirësuar me 0.2%, por numri i parametrave duhet të shkallëzohet me 2.9%, dhe llogaritja me 1.2%.
Modeli i propozuar i ri-parametralizuar i planifikuar
Për të verifikuar përgjithësinë e modelit të ri-parametralizuar të propozuar, Algoritmi YOLOv7 e përdor atë në modele të bazuara në mbetje dhe të bazuara në lidhje për verifikim. Për procesin e verifikimit, përdor algoritmi YOLOv7 ELAN me 3 stivosje për modelin e bazuar në lidhje, dhe CSPDarknet për modelin e bazuar në mbetje.
Për modelin e bazuar në lidhje, algoritmi zëvendëson shtresat konvolucionare 3×3 në ELAN me 3 stivime me RepConv. Figura më poshtë tregon konfigurimin e detajuar të Planned RepConv dhe ELAN me 3 stiv.
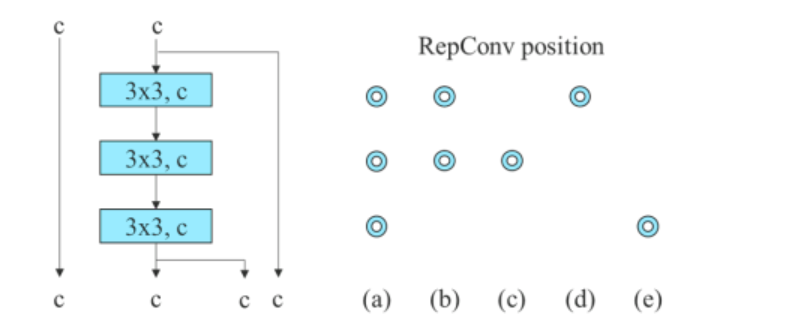
Për më tepër, kur kemi të bëjmë me modelin e bazuar në mbetje, algoritmi YOLOv7 përdor një bllok të errët të kundërt, sepse blloku i errët origjinal nuk ka një bllok konvolucioni 3×3. Figura e mëposhtme tregon arkitekturën e rrjetit të kundërt CSPDark që ndryshon pozicionet e shtresës konvolucionale 3×3 dhe 1×1. 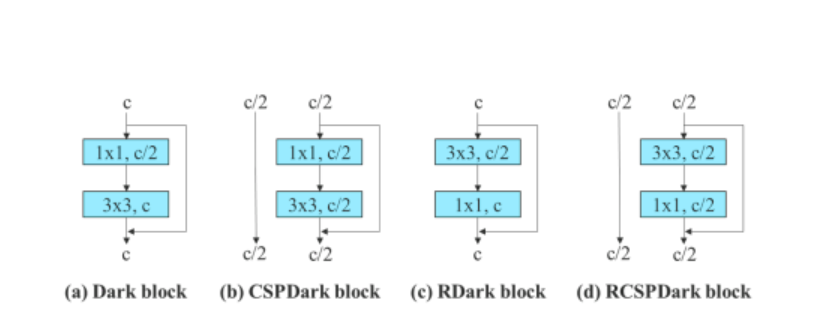
Humbja e propozuar e asistentit për kreun ndihmës
Për humbjen e ndihmës për kokën ndihmëse, modeli YOLOv7 krahason caktimin e pavarur të etiketës për metodat e kokës ndihmëse dhe kokës së plumbit.

Figura e mësipërme përmban rezultatet e studimit mbi kokën e propozuar ndihmëse. Mund të shihet se performanca e përgjithshme e modelit rritet me një rritje të humbjes së asistentit. Për më tepër, caktimi i etiketës së drejtuar nga drejtuesi i propozuar nga modeli YOLOv7 performon më mirë sesa strategjitë e pavarura të caktimit të drejtuesve.
Rezultatet e YOLOv7
Bazuar në eksperimentet e mësipërme, këtu është rezultati i performancës së YOLov7 kur krahasohet me algoritmet e tjera të zbulimit të objekteve.

Figura e mësipërme krahason modelin YOLOv7 me algoritme të tjera të zbulimit të objekteve dhe mund të vërehet qartë se YOLOv7 tejkalon modelet e tjera të zbulimit të kundërshtimeve për sa i përket Precisioni mesatar (AP) v/s interferenca në grup.
Për më tepër, figura e mëposhtme krahason performancën e algoritmeve të tjera të zbulimit të kundërshtimeve në kohë reale YOLOv7 v/s. Edhe një herë, YOLOv7 pason modelet e tjera për sa i përket performancës së përgjithshme, saktësisë dhe efikasitetit.

Këtu janë disa vëzhgime shtesë nga rezultatet dhe performancat e YOLOv7.
- YOLOv7-Tiny është modeli më i vogël në familjen YOLO, me mbi 6 milionë parametra. YOLOv7-Tiny ka një saktësi mesatare prej 35.2%, dhe i kalon modelet YOLOv4-Tiny me parametra të krahasueshëm.
- Modeli YOLOv7 ka mbi 37 milionë parametra dhe i kalon modelet me parametra më të lartë si YOLov4.
- Modeli YOLOv7 ka shkallën më të lartë të mAP dhe FPS në rangun nga 5 deri në 160 FPS.
Përfundim
YOLO ose You Only Look Once është modeli më i fundit i zbulimit të objekteve në vizionin kompjuterik modern. Algoritmi YOLO është i njohur për saktësinë dhe efikasitetin e tij të lartë, dhe si rezultat, gjen aplikim të gjerë në industrinë e zbulimit të objekteve në kohë reale. Që kur u prezantua algoritmi i parë YOLO në vitin 2016, eksperimentet i kanë lejuar zhvilluesit të përmirësojnë modelin vazhdimisht.
Modeli YOLOv7 është shtimi më i fundit në familjen YOLO dhe është algoritmi më i fuqishëm YOLo deri më tani. Në këtë artikull, ne kemi folur për bazat e YOLOv7 dhe jemi përpjekur të shpjegojmë se çfarë e bën YOLOv7 kaq efikas.















