
Inteligjenca artificiale
InstructIR: Rivendosja e imazhit me cilësi të lartë sipas udhëzimeve njerëzore

Një imazh mund të përcjellë shumë, por mund të dëmtohet edhe nga çështje të ndryshme si turbullira e lëvizjes, mjegullimi, zhurma dhe diapazoni i ulët dinamik. Këto probleme, të referuara zakonisht si degradime në vizionin kompjuterik të nivelit të ulët, mund të lindin nga kushtet e vështira mjedisore si nxehtësia ose shiu ose nga kufizimet e vetë kamerës. Restaurimi i imazhit përfaqëson një sfidë thelbësore në vizionin kompjuterik, duke u përpjekur për të rikuperuar një imazh me cilësi të lartë dhe të pastër nga ai që shfaq degradime të tilla. Rivendosja e imazhit është kompleks sepse mund të ketë zgjidhje të shumta për të rivendosur çdo imazh të caktuar. Disa qasje synojnë degradime specifike, të tilla si ulja e zhurmës ose heqja e turbullimit ose mjegullës.
Ndërsa këto metoda mund të japin rezultate të mira për çështje të veçanta, ato shpesh përpiqen të përgjithësohen në lloje të ndryshme degradimi. Shumë korniza përdorin një rrjet nervor gjenerik për një gamë të gjerë detyrash të restaurimit të imazhit, por këto rrjete janë trajnuar secila veç e veç. Nevoja për modele të ndryshme për çdo lloj degradimi e bën këtë qasje llogaritëse të shtrenjtë dhe kërkon kohë, duke çuar në një fokus në modelet e restaurimit Gjithë-në-Një në zhvillimet e fundit. Këto modele përdorin një model restaurimi të vetëm, të verbër të thellë që trajton nivele dhe lloje të shumta degradimi, shpesh duke përdorur udhëzime specifike për degradimin ose vektorë udhëzues për të përmirësuar performancën. Edhe pse modelet Gjithçka-në-Një zakonisht tregojnë rezultate premtuese, ato ende përballen me sfida me probleme të anasjellta.
InstructIR përfaqëson një qasje novatore në terren, duke qenë e para restaurimi i imazhit kornizë e krijuar për të udhëhequr modelin e restaurimit përmes udhëzimeve të shkruara nga njeriu. Ai mund të përpunojë kërkesat e gjuhës natyrore për të rikuperuar imazhe me cilësi të lartë nga ato të degraduara, duke marrë parasysh lloje të ndryshme degradimi. InstructIR vendos një standard të ri në performancë për një spektër të gjerë detyrash të restaurimit të imazhit, duke përfshirë heqjen, denoisimin, zbutjen, mjegullimin dhe përmirësimin e imazheve me dritë të ulët.
Ky artikull synon të mbulojë në thellësi kuadrin InstructIR, dhe ne eksplorojmë mekanizmin, metodologjinë, arkitekturën e kornizës së bashku me krahasimin e tij me kornizat më moderne të imazhit dhe videove. Pra, le të fillojmë.
InstructIR: Rivendosja e imazhit me cilësi të lartë
Rivendosja e imazhit është një problem thelbësor në vizionin kompjuterik pasi synon të rikuperojë një imazh të pastër me cilësi të lartë nga një imazh që demonstron degradime. Në vizionin kompjuterik të nivelit të ulët, Degradimet është një term që përdoret për të përfaqësuar efektet e pakëndshme të vëzhguara brenda një imazhi si turbullira e lëvizjes, mjegullimi, zhurma, diapazoni i ulët dinamik dhe më shumë. Arsyeja pse restaurimi i imazhit është një sfidë komplekse e kundërt është sepse mund të ketë zgjidhje të shumta të ndryshme për rivendosjen e çdo imazhi. Disa korniza fokusohen në degradime specifike si zvogëlimi i zhurmës së shembullit ose heqja e zhurmës së imazhit, ndërsa të tjerët mund të fokusohen më shumë në heqjen e turbullimit ose mjegullimit, ose pastrimin e mjegullës ose zbutjes.
Metodat e fundit të të mësuarit të thellë kanë shfaqur performancë më të fortë dhe më të qëndrueshme në krahasim me metodat tradicionale të restaurimit të imazhit. Këto modele të restaurimit të imazhit të të mësuarit të thellë propozojnë përdorimin e rrjeteve nervore të bazuara në transformatorët dhe rrjetet nervore konvolucioniste. Këto modele mund të trajnohen në mënyrë të pavarur për detyra të ndryshme të restaurimit të imazhit, dhe ato gjithashtu posedojnë aftësinë për të kapur ndërveprimet lokale dhe globale të veçorive dhe për t'i përmirësuar ato, duke rezultuar në performancë të kënaqshme dhe të qëndrueshme. Edhe pse disa nga këto metoda mund të funksionojnë në mënyrë adekuate për lloje specifike të degradimit, ato zakonisht nuk ekstrapolohen mirë në lloje të ndryshme degradimi. Për më tepër, ndërsa shumë korniza ekzistuese përdorin të njëjtin rrjet nervor për një mori detyrash të restaurimit të imazhit, çdo formulim i rrjetit nervor është trajnuar veçmas. Prandaj, është e qartë se përdorimi i një modeli nervor të veçantë për çdo degradim të imagjinueshëm është i pamundur dhe kërkon kohë, prandaj kornizat e fundit të restaurimit të imazhit janë përqendruar në përfaqësuesit e restaurimit Gjithë-në-Një.
Modelet e restaurimit të imazhit Gjithçka-në-Një ose me shumë degradim ose me shumë detyra po fitojnë popullaritet në fushën e vizionit kompjuterik pasi ato janë të afta të rivendosin lloje dhe nivele të shumta degradimesh në një imazh pa nevojën e trajnimit të modeleve në mënyrë të pavarur për çdo degradim . Modelet e restaurimit të imazhit Gjithçka-në-Një përdorin një model të vetëm të restaurimit të imazhit të verbër të thellë për të trajtuar lloje dhe nivele të ndryshme të degradimit të imazhit. Modele të ndryshme Gjithçka-në-Një zbatojnë qasje të ndryshme për të drejtuar modelin e verbër për të rivendosur imazhin e degraduar, për shembull, një model ndihmës për të klasifikuar vektorët udhëzues të degradimit ose shumëdimensionale ose kërkesa për të ndihmuar modelin të rivendosë lloje të ndryshme degradimi brenda një imazh.
Me këtë u tha, ne arrijmë në manipulimin e imazhit të bazuar në tekst, pasi ai është zbatuar nga disa korniza në vitet e fundit për gjenerimin e tekstit në imazh dhe detyrat e redaktimit të imazheve të bazuara në tekst. Këto modele shpesh përdorin udhëzime teksti për të përshkruar veprime ose imazhe së bashku me modele të bazuara në difuzion për të gjeneruar imazhet përkatëse. Frymëzimi kryesor për kornizën InstructIR është korniza InstructPix2Pix që i mundëson modelit të modifikojë imazhin duke përdorur udhëzimet e përdoruesit që udhëzojnë modelin se çfarë veprimi duhet të kryejë në vend të etiketave tekstuale, përshkrimeve ose titrave të imazhit të hyrjes. Si rezultat, përdoruesit mund të përdorin tekste të shkruara natyrale për të udhëzuar modelin se çfarë veprimi duhet të kryejë pa nevojën e sigurimit të imazheve të mostrës ose përshkrimeve shtesë të imazheve.
Duke u bazuar në këto baza, korniza InstructIR është modeli i parë i vizionit kompjuterik që përdor udhëzime të shkruara nga njeriu për të arritur restaurimin e imazhit dhe zgjidhjen e problemeve të anasjellta. Për kërkesat e gjuhës natyrore, modeli InstructIR mund të rikuperojë imazhe me cilësi të lartë nga homologët e tyre të degraduar dhe gjithashtu merr parasysh lloje të shumta degradimi. Korniza InstructIR është në gjendje të ofrojë performancën më të fundit në një gamë të gjerë detyrash të restaurimit të imazhit, duke përfshirë heqjen e imazhit, denoisimin, zbërthimin, mjegullimin dhe përmirësimin e imazhit në dritë të ulët. Ndryshe nga punimet ekzistuese që arrijnë restaurimin e imazhit duke përdorur vektorë udhëzues të mësuar ose ngulitje të menjëhershme, korniza InstructIR përdor kërkesat e papërpunuara të përdoruesit në formë teksti. Korniza InstructIR është në gjendje të përgjithësohet në rivendosjen e imazheve duke përdorur udhëzime të shkruara nga njeriu, dhe modeli i vetëm "gjithë-në-një" i zbatuar nga InstructIR mbulon më shumë detyra restaurimi sesa modelet e mëparshme. Figura e mëposhtme tregon mostrat e ndryshme të restaurimit të kornizës InstructIR.

InstructIR: Metoda dhe Arkitektura
Në thelbin e tij, korniza InstructIR përbëhet nga një kodues teksti dhe një model imazhi. Modeli përdor kornizën NAFNet, një model efikas i restaurimit të imazhit që ndjek një arkitekturë U-Net si model imazhi. Për më tepër, modeli zbaton teknika të drejtimit të detyrave për të mësuar detyra të shumta duke përdorur me sukses një model të vetëm. Figura e mëposhtme ilustron qasjen e trajnimit dhe vlerësimit për kornizën InstructIR.

Duke u frymëzuar nga modeli InstructPix2Pix, korniza InstructIR miraton udhëzimet e shkruara njerëzore si mekanizëm kontrolli pasi nuk ka nevojë që përdoruesi të japë informacion shtesë. Këto udhëzime ofrojnë një mënyrë ekspresive dhe të qartë për të ndërvepruar duke i lejuar përdoruesit të vënë në dukje vendndodhjen e saktë dhe llojin e degradimit në imazh. Për më tepër, përdorimi i kërkesave të përdoruesit në vend të kërkesave specifike të degradimit fiks rrit përdorshmërinë dhe aplikimet e modelit pasi mund të përdoret gjithashtu nga përdoruesit të cilëve u mungon ekspertiza e kërkuar e domenit. Për të pajisur kornizën InstructIR me aftësinë për të kuptuar kërkesat e ndryshme, modeli përdor GPT-4, një model i madh gjuhësor për të krijuar kërkesa të ndryshme, me kërkesa të paqarta dhe të paqarta të hequra pas një procesi filtrimi.
Koduesi i tekstit
Një kodues teksti përdoret nga modelet e gjuhës për të hartuar kërkesat e përdoruesit në një ngulitje teksti ose një paraqitje vektoriale me madhësi fikse. Tradicionalisht, koduesi i tekstit të a Modeli CLIP është një komponent jetik për gjenerimin e imazheve të bazuara në tekst dhe modelet e manipulimit të imazheve të bazuara në tekst për të koduar kërkesat e përdoruesve pasi korniza CLIP shkëlqen në kërkesat vizuale. Megjithatë, në shumicën e rasteve, përdoruesi kërkon degradim të shfaqë pak ose aspak përmbajtje vizuale, prandaj, duke i bërë koduesit e mëdhenj CLIP të padobishëm për detyra të tilla pasi do të pengojë ndjeshëm efikasitetin. Për të trajtuar këtë çështje, korniza InstructIR zgjedh një kodues fjalish të bazuar në tekst, i cili është trajnuar për të koduar fjali në një hapësirë kuptimplote të ngulitjes. Koduesit e fjalive janë të trajnuar paraprakisht në miliona shembuj dhe megjithatë, janë kompakt dhe efikas në krahasim me koduesit tradicional të tekstit të bazuar në CLIP, ndërkohë që kanë aftësinë për të koduar semantikën e kërkesave të ndryshme të përdoruesve.
Udhëzim me tekst
Një aspekt kryesor i kornizës InstructIR është zbatimi i instruksionit të koduar si një mekanizëm kontrolli për modelin e imazhit. Duke u bazuar në këtë, dhe i frymëzuar në drejtimin e detyrave për mësimin e shumë detyrave, korniza InstructIR propozon një bllok ndërtimi instruksioni ose ICB për të mundësuar transformime specifike të detyrave brenda modelit. Drejtimi konvencional i detyrave aplikon maska binare specifike të detyrave për veçoritë e kanalit. Megjithatë, meqenëse korniza InstructIR nuk e njeh degradimin, kjo teknikë nuk zbatohet drejtpërdrejt. Për më tepër, për veçoritë e imazhit dhe udhëzimet e koduara, korniza InstructIR aplikon drejtimin e detyrave dhe prodhon maskën duke përdorur një shtresë lineare të aktivizuar duke përdorur funksionin Sigmoid për të prodhuar një grup peshash në varësi të futjeve të tekstit, duke marrë kështu një dimension c për maskë binare e kanalit. Modeli përmirëson më tej veçoritë e kushtëzuara duke përdorur një NAFBlock dhe përdor NAFBlock dhe Bllokun e Kushtëzuar të Instruksionit për të kushtëzuar veçoritë në bllokun e koduesit dhe në bllokun e dekoderit.
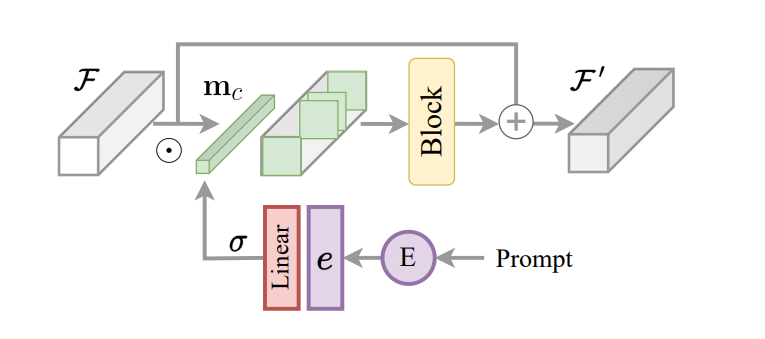
Edhe pse korniza InstructIR nuk i kushtëzon filtrat e rrjetit nervor në mënyrë eksplicite, maska lehtëson modelin të zgjedhë kanalet më të rëndësishme në bazë të udhëzimeve të imazhit dhe informacionit.
InstructIR: Zbatimi dhe rezultatet
Modeli InstructIR është i trajnueshëm nga fundi në fund dhe modeli i imazhit nuk kërkon trajnim paraprak. Është vetëm projeksionet e futjes së tekstit dhe kreu i klasifikimit që duhet të trajnohet. Enkoderi i tekstit inicializohet duke përdorur një kodues BGE, një kodues i ngjashëm me BERT-në, i cili është i trajnuar paraprakisht në një sasi të madhe të dhënash të mbikëqyrura dhe të pambikëqyrura për kodimin e fjalive për qëllime të përgjithshme. Korniza InstructIR përdor modelin NAFNet si model imazhi, dhe arkitektura e NAFNet përbëhet nga një dekoder kodues me 4 nivele me numër të ndryshëm blloqesh në çdo nivel. Modeli gjithashtu shton 4 blloqe të mesme midis koduesit dhe dekoderit për të përmirësuar më tej veçoritë. Për më tepër, në vend që të lidhet për lidhjet e kapërcimit, dekoderi zbaton shtimin dhe modeli InstructIR zbaton vetëm ICB ose Bllokun e Kushtëzuar të Instruksionit për drejtimin e detyrave vetëm në kodues dhe dekoder. Duke ecur përpara, modeli InstructIR është optimizuar duke përdorur humbjen midis imazhit të rivendosur dhe imazhit të pastër të së vërtetës nga terreni, dhe humbja e entropisë së kryqëzuar përdoret për kokën e klasifikimit të qëllimit të koduesit të tekstit. Modeli InstructIR përdor optimizuesin AdamW me një madhësi grupi prej 32 dhe një shkallë mësimi prej 5e-4 për gati 500 epoka, dhe gjithashtu zbaton zbërthimin e shkallës së të mësuarit të pjekjes kosinus. Meqenëse modeli i imazhit në kornizën InstructIR përfshin vetëm 16 milionë parametra dhe ka vetëm 100 mijë parametra të projektimit të tekstit të mësuar, korniza InstructIR mund të trajnohet lehtësisht në GPU-të standarde, duke ulur kështu kostot llogaritëse dhe duke rritur zbatueshmërinë.
Rezultatet e shumëfishta të degradimit
Për degradime të shumta dhe restaurime me shumë detyra, korniza InstructIR përcakton dy konfigurime fillestare:
- 3D për modelet me tre degradim për të trajtuar çështjet e degradimit si dezinfektimi, denoisimi dhe heqja e ujit.
- 5D për pesë modele degradimi për të trajtuar çështjet e degradimit si denoisimi i imazhit, përmirësimet në dritë të ulët, zbutja, denoisimi dhe heqja e ajrit.
Performanca e modeleve 5D është demonstruar në tabelën e mëposhtme dhe e krahason atë me restaurimin e imazhit më të fundit dhe modelet të gjitha-në-një.

Siç mund të vërehet, korniza InstructIR me një model të thjeshtë imazhi dhe vetëm 16 milionë parametra mund të trajtojë me sukses pesë detyra të ndryshme të restaurimit të imazhit falë udhëzimeve të bazuara në udhëzime dhe jep rezultate konkurruese. Tabela e mëposhtme tregon performancën e kornizës në modelet 3D dhe rezultatet janë të krahasueshme me rezultatet e mësipërme.

Pika kryesore e kornizës InstructIR është restaurimi i imazhit të bazuar në udhëzime dhe figura e mëposhtme tregon aftësitë e jashtëzakonshme të modelit InstructIR për të kuptuar një gamë të gjerë udhëzimesh për një detyrë të caktuar. Gjithashtu, për një instruksion kundërshtar, modeli InstructIR kryen një identitet që nuk është i detyruar.

Mendime përfundimtare
Rivendosja e imazhit është një problem thelbësor në vizionin kompjuterik pasi synon të rikuperojë një imazh të pastër me cilësi të lartë nga një imazh që demonstron degradime. Në vizionin kompjuterik të nivelit të ulët, Degradimet është një term që përdoret për të përfaqësuar efektet e pakëndshme të vëzhguara brenda një imazhi si turbullira e lëvizjes, mjegullimi, zhurma, diapazoni i ulët dinamik dhe më shumë. Në këtë artikull, ne kemi folur për InstructIR, kuadri i parë në botë i restaurimit të imazhit që synon të drejtojë modelin e restaurimit të imazhit duke përdorur udhëzime të shkruara nga njeriu. Për kërkesat e gjuhës natyrore, modeli InstructIR mund të rikuperojë imazhe me cilësi të lartë nga homologët e tyre të degraduar dhe gjithashtu merr parasysh lloje të shumta degradimi. Korniza InstructIR është në gjendje të ofrojë performancën më të fundit në një gamë të gjerë detyrash të restaurimit të imazhit, duke përfshirë heqjen e imazhit, denoisimin, zbërthimin, mjegullimin dhe përmirësimin e imazhit në dritë të ulët.















