
Umetna inteligenca
YOLOv7: Najnaprednejši algoritem za zaznavanje predmetov?

6. julij 2022 bo zapisan kot mejnik v zgodovini umetne inteligence, ker je bil ta dan, ko je bil izdan YOLOv7. Vse od lansiranja je YOLOv7 najbolj vroča tema v skupnosti razvijalcev računalniškega vida in to iz pravih razlogov. YOLOv7 že velja za mejnik v industriji odkrivanja predmetov.
Kmalu po Objavljen je bil članek YOLOv7, izkazal se je kot najhitrejši in najbolj natančen model za odkrivanje ugovorov v realnem času. Kako pa YOLOv7 prekaša svoje predhodnike? Zakaj je YOLOv7 tako učinkovit pri izvajanju nalog računalniškega vida?
V tem članku bomo poskušali analizirati model YOLOv7 in poskušali najti odgovor, zakaj YOLOv7 zdaj postaja industrijski standard? Toda preden lahko odgovorimo na to, si bomo morali ogledati kratko zgodovino zaznavanja predmetov.
Kaj je zaznavanje predmetov?
Zaznavanje predmetov je veja računalniškega vida ki identificira in locira predmete na sliki ali video datoteki. Zaznavanje predmetov je gradnik številnih aplikacij, vključno s samovozečimi avtomobili, nadzorovanim nadzorom in celo robotiko.
Model zaznavanja objektov lahko razvrstimo v dve različni kategoriji, enojni detektorji, in večstrelni detektorji.
Zaznavanje predmetov v realnem času
Da bi resnično razumeli, kako deluje YOLOv7, je bistveno, da razumemo glavni cilj YOLOv7, “Zaznavanje predmetov v realnem času". Zaznavanje predmetov v realnem času je ključna komponenta sodobnega računalniškega vida. Modeli za odkrivanje predmetov v realnem času poskušajo identificirati in locirati zanimive predmete v realnem času. Modeli za zaznavanje predmetov v realnem času so razvijalcem omogočili resnično učinkovito sledenje zanimivim predmetom v premikajočem se okvirju, kot je videoposnetek ali nadzorni vnos v živo.

Modeli za zaznavanje objektov v realnem času so v bistvu korak naprej od običajnih modelov za zaznavanje slik. Medtem ko se prvi uporablja za sledenje predmetom v video datotekah, drugi locira in identificira predmete znotraj mirujočega okvira, kot je slika.
Posledično so modeli za zaznavanje predmetov v realnem času resnično učinkoviti za video analitiko, avtonomna vozila, štetje objektov, sledenje več objektom in še veliko več.
Kaj je YOLO?
YOLO ali "Samo enkrat pogledaš” je družina modelov za odkrivanje objektov v realnem času. Koncept YOLO je leta 2016 prvič predstavil Joseph Redmon in o njem se je skoraj takoj začelo govoriti, ker je bil veliko hitrejši in veliko natančnejši od obstoječih algoritmov za zaznavanje predmetov. Kmalu je algoritem YOLO postal standard v industriji računalniškega vida.

Temeljni koncept, ki ga predlaga algoritem YOLO, je uporaba nevronske mreže od konca do konca z uporabo omejevalnih okvirjev in verjetnosti razreda za napovedovanje v realnem času. YOLO se je razlikoval od prejšnjega modela zaznavanja objektov v smislu, da je predlagal drugačen pristop za izvajanje zaznavanja objektov s spreminjanjem namena klasifikatorjev.
Sprememba pristopa je delovala, saj je YOLO kmalu postal industrijski standard, saj je bila razlika v zmogljivosti med samim seboj in drugimi algoritmi za odkrivanje objektov v realnem času pomembna. Toda kaj je bil razlog, zakaj je bil YOLO tako učinkovit?
V primerjavi z YOLO so takratni algoritmi za zaznavanje objektov uporabljali omrežja predlogov regij za odkrivanje možnih regij, ki bi jih zanimalo. Postopek prepoznavanja je bil nato izveden na vsaki regiji posebej. Posledično so ti modeli pogosto izvajali več iteracij na isti sliki in s tem pomanjkanje natančnosti in daljši čas izvedbe. Po drugi strani pa algoritem YOLO uporablja en sam popolnoma povezan sloj za izvedbo napovedi hkrati.
Kako deluje YOLO?
Obstajajo trije koraki, ki pojasnjujejo, kako deluje algoritem YOLO.
Reframing Object Detection kot problem posamezne regresije
O Algoritem YOLO poskuša preoblikovati zaznavanje objekta kot en sam regresijski problem, vključno s slikovnimi pikami, do verjetnosti razreda in koordinat omejevalnega polja. Zato mora algoritem pogledati sliko le enkrat, da predvidi in locira ciljne predmete na slikah.
Razlogi za sliko globalno
Poleg tega ko algoritem YOLO naredi napovedi, obrazloži sliko globalno. Razlikuje se od tehnik, ki temeljijo na predlogih regije, in drsnih tehnik, saj algoritem YOLO vidi celotno sliko med usposabljanjem in testiranjem nabora podatkov ter lahko kodira kontekstualne informacije o razredih in njihovem videzu.
Pred YOLO je bil Fast R-CNN eden najbolj priljubljenih algoritmov za zaznavanje objektov, ki ni mogel videti širšega konteksta na sliki, ker je zaplate ozadja na sliki zamenjal za predmet. V primerjavi z algoritmom Fast R-CNN je YOLO 50 % bolj natančen ko gre za napake v ozadju.
Posplošuje predstavitev predmetov
Nazadnje, cilj algoritma YOLO je tudi posploševanje predstavitev predmetov na sliki. Kot rezultat, ko je bil algoritem YOLO zagnan na naboru podatkov z naravnimi slikami in preizkušen za rezultate, je YOLO močno presegel obstoječe modele R-CNN. Ker je YOLO zelo posplošljiv, so bile možnosti, da bi se pokvaril, ko bi se izvajal na nepričakovanih vhodih ali novih domenah, majhne.
YOLOv7: Kaj je novega?
Zdaj, ko imamo osnovno razumevanje, kaj so modeli za odkrivanje predmetov v realnem času in kaj je algoritem YOLO, je čas, da razpravljamo o algoritmu YOLOv7.
Optimiziranje procesa usposabljanja
Algoritem YOLOv7 ne samo da poskuša optimizirati arhitekturo modela, ampak je namenjen tudi optimizaciji procesa usposabljanja. Njegov cilj je uporaba optimizacijskih modulov in metod za izboljšanje natančnosti zaznavanja objektov, povečanje stroškov za usposabljanje, hkrati pa ohranjanje stroškov motenj. Te optimizacijske module lahko imenujemo a vadljiva vrečka brezplačnih izdelkov.
Grobo do fino vodeno dodeljevanje oznak
Algoritem YOLOv7 namerava uporabiti novo vodeno dodeljevanje oznak od grobega do finega svinca namesto običajnega Dinamična dodelitev oznak. To je zato, ker pri dinamičnem dodeljevanju oznak usposabljanje modela z več izhodnimi plastmi povzroča nekaj težav, najpogostejša med katerimi je, kako dodeliti dinamične cilje za različne veje in njihove rezultate.
Ponovna parametrizacija modela
Ponovna parametrizacija modela je pomemben koncept pri odkrivanju objektov in njeni uporabi med usposabljanjem na splošno sledi nekaj težav. Algoritem YOLOv7 načrtuje uporabo koncepta pot širjenja gradienta za analizo politik ponovne parametrizacije modela uporaben za različne plasti v omrežju.
Razširjeno in sestavljeno skaliranje
Algoritem YOLOv7 uvaja tudi razširjene in sestavljene metode skaliranja za uporabo in učinkovito uporabo parametrov in izračunov za odkrivanje predmetov v realnem času.

YOLOv7 : Sorodno delo
Zaznavanje predmetov v realnem času
YOLO je trenutno industrijski standard in večina detektorjev predmetov v realnem času uporablja algoritme YOLO in FCOS (Fully Convolutional One-Stage Object-Detection). Najsodobnejši detektor predmetov v realnem času ima običajno naslednje značilnosti
- Močnejša in hitrejša omrežna arhitektura.
- Učinkovita metoda integracije funkcij.
- Natančna metoda zaznavanja predmetov.
- Robustna izgubna funkcija.
- Učinkovit način dodeljevanja etiket.
- Učinkovit način usposabljanja.
Algoritem YOLOv7 ne uporablja metod samonadzorovanega učenja in destilacije, ki pogosto zahtevajo velike količine podatkov. Nasprotno pa algoritem YOLOv7 uporablja metodo vrečke brezplačnih izdelkov, ki jo je mogoče usposobiti.
Ponovna parametrizacija modela
Tehnike ponovne parametrizacije modela se obravnavajo kot tehnika ansambla, ki združuje več računalniških modulov v interferenčni stopnji. Tehniko lahko nadalje razdelimo v dve kategoriji, ansambel na ravni modela, in modulna zasedba.
Za pridobitev končnega modela motenj tehnika reparametrizacije na ravni modela uporablja dve praksi. Prva praksa uporablja različne podatke o usposabljanju za usposabljanje številnih enakih modelov, nato pa izračuna povprečje uteži treniranih modelov. Druga možnost je, da druga praksa povpreči uteži modelov med različnimi iteracijami.
Ponovna parametrizacija na ravni modula v zadnjem času postaja izjemno priljubljena, ker razdeli modul na različne veje modula ali različne enake veje med fazo usposabljanja, nato pa nadaljuje z integracijo teh različnih vej v enakovreden modul med interferenco.
Vendar tehnik ponovne parametrizacije ni mogoče uporabiti za vse vrste arhitekture. To je razlog, zakaj je Algoritem YOLOv7 uporablja nove tehnike ponovne parametrizacije modela za oblikovanje povezanih strategij primerna za različne arhitekture.
Skaliranje modela
Skaliranje modela je postopek povečevanja ali zmanjševanja obstoječega modela, da se prilega različnim računalniškim napravam. Skaliranje modela na splošno uporablja različne dejavnike, kot je število plasti (globina), velikost vhodnih slik (Ločljivost), število značilnih piramid (stopnja) in število kanalov (širina). Ti dejavniki igrajo ključno vlogo pri zagotavljanju uravnoteženega kompromisa za parametre omrežja, hitrost motenj, izračun in natančnost modela.
Eden najpogosteje uporabljenih načinov skaliranja je NAS ali Iskanje omrežne arhitekture ki samodejno išče ustrezne skalirne faktorje iz iskalnikov brez zapletenih pravil. Glavna slaba stran uporabe NAS je, da je to drag pristop za iskanje ustreznih faktorjev skaliranja.
Skoraj vsak model ponovne parametrizacije modela neodvisno analizira posamezne in edinstvene faktorje skaliranja in poleg tega celo neodvisno optimizira te faktorje. To je zato, ker arhitektura NAS deluje z nekoreliranimi faktorji skaliranja.
Omeniti velja, da modeli, ki temeljijo na veriženju, kot VoVNet or DenseNet spremenite vhodno širino nekaj plasti, ko se globina modelov spreminja. YOLOv7 deluje na predlagani arhitekturi, ki temelji na veriženju, in zato uporablja metodo sestavljenega skaliranja.

Zgoraj navedena slika primerja razširjena učinkovita omrežja združevanja slojev (E-ELAN) različnih modelov. Predlagana metoda E-ELAN ohranja gradientno prenosno pot izvirne arhitekture, vendar želi povečati kardinalnost dodanih funkcij z uporabo skupinske konvolucije. Postopek lahko izboljša funkcije, ki so se jih naučili različni zemljevidi, in lahko dodatno poveča učinkovitost uporabe izračunov in parametrov.
Arhitektura YOLOv7
Model YOLOv7 kot osnovo uporablja modele YOLOv4, YOLO-R in Scaled YOLOv4. YOLOv7 je rezultat poskusov, izvedenih na teh modelih, da bi izboljšali rezultate in naredili model natančnejši.
Razširjeno učinkovito omrežje združevanja slojev ali E-ELAN
E-ELAN je temeljni gradnik modela YOLOv7 in izhaja iz že obstoječih modelov učinkovitosti omrežja, predvsem ELAN.
Glavni premisleki pri načrtovanju učinkovite arhitekture so število parametrov, gostota računanja in količina računanja. Drugi modeli upoštevajo tudi dejavnike, kot so vpliv razmerja vhodnih/izhodnih kanalov, veje v arhitekturnem omrežju, hitrost motenj v omrežju, število elementov v tenzorjih konvolucijskega omrežja in drugo.
O CSPVoNet model ne upošteva le zgoraj omenjenih parametrov, ampak tudi analizira pot gradienta, da se nauči več raznolikih funkcij z omogočanjem uteži različnih plasti. Pristop omogoča, da so motnje veliko hitrejše in natančnejše. The MOMENTUM Cilj arhitekture je oblikovanje učinkovitega omrežja za nadzor najkrajše najdaljše gradientne poti, tako da je lahko omrežje učinkovitejše pri učenju in zbliževanju.
ELAN je že dosegel stabilno stopnjo ne glede na število zloženih računskih blokov in dolžino poti gradienta. Stabilno stanje bi lahko bilo uničeno, če so računski bloki neomejeno zloženi, stopnja izkoriščenosti parametrov pa se bo zmanjšala. The predlagana arhitektura E-ELAN lahko reši težavo, saj uporablja kardinalnost razširitve, mešanja in združevanja za stalno izboljšanje sposobnosti učenja omrežja ob ohranjanju prvotne gradientne poti.
Poleg tega, ko primerjamo arhitekturo E-ELAN z ELAN, razlika je le v računskem bloku, medtem ko je arhitektura prehodne plasti nespremenjena.
E-ELAN predlaga razširitev kardinalnosti računskih blokov in razširitev kanala z uporabo skupinska konvolucija. Zemljevid značilnosti bo nato izračunan in premeščen v skupine glede na parameter skupine, nato pa bo združen. Število kanalov v vsaki skupini bo ostalo enako kot v originalni arhitekturi. Nazadnje bodo dodane skupine zemljevidov funkcij za izvedbo kardinalnosti.
Merjenje modela za modele, ki temeljijo na veriženju
Pri tem pomaga skaliranje modela prilagajanje atributov modelov ki pomaga pri ustvarjanju modelov v skladu z zahtevami in v različnih obsegih za doseganje različnih hitrosti motenj.

Slika govori o skaliranju modela za različne modele, ki temeljijo na veriženju. Kot lahko vidite na sliki (a) in (b), se izhodna širina računskega bloka poveča s povečanjem skaliranja globine modelov. Posledično se vhodna širina prenosnih plasti poveča. Če so te metode implementirane v arhitekturi, ki temelji na veriženju, se postopek skaliranja izvaja poglobljeno, kar je prikazano na sliki (c).
Tako lahko sklepamo, da faktorjev skaliranja ni mogoče analizirati neodvisno za modele, ki temeljijo na veriženju, temveč jih je treba obravnavati ali analizirati skupaj. Zato je za model, ki temelji na veriženju, primerno je uporabiti ustrezno metodo skaliranja sestavljenega modela. Poleg tega je treba pri skaliranju globinskega faktorja prilagoditi tudi izhodni kanal bloka.
Trainable Bag of Freebies
Vreča brezplačnih izdelkov je izraz, ki ga razvijalci uporabljajo za opis nabor metod ali tehnik, ki lahko spremenijo strategijo usposabljanja ali stroške v poskusu povečanja natančnosti modela. Kaj so torej te brezplačne vrečke, ki jih je mogoče trenirati, v YOLOv7? Poglejmo.
Načrtovana ponovno parametrirana konvolucija
Algoritem YOLOv7 za določanje uporablja poti širjenja gradientnega toka kako idealno združiti omrežje s ponovno parametrizirano konvolucijo. Ta pristop YOLov7 je poskus nasprotovanja algoritem RepConv ki je, čeprav je deloval mirno na modelu VGG, deloval slabo, ko je uporabljen neposredno na modelih DenseNet in ResNet.
Za identifikacijo povezav v konvolucijski plasti je Algoritem RepConv združuje konvolucijo 3×3 in konvolucijo 1×1. Če analiziramo algoritem, njegovo zmogljivost in arhitekturo, bomo opazili, da RepConv uniči veriženje v DenseNet, ostanek pa v ResNet.

Zgornja slika prikazuje načrtovani ponovno parametriran model. Vidimo lahko, da je algoritem YOLov7 ugotovil, da sloj v omrežju z veriženjem ali preostalimi povezavami ne bi smel imeti identitetne povezave v algoritmu RepConv. Posledično je sprejemljivo preklopiti z RepConvN brez povezav identitete.
Grobo za pomožno in fino za izgubo svinca
Globok nadzor je veja računalništva, ki se pogosto uporablja v procesu usposabljanja globokih omrežij. Temeljno načelo globokega nadzora je, da doda dodatno pomožno glavo v srednjih slojih mreže skupaj s plitvimi mrežnimi utežmi z izgubo pomočnika kot vodilom. Algoritem YOLOv7 se nanaša na glavo, ki je odgovorna za končni rezultat, kot vodilno glavo, pomožna glava pa je glava, ki pomaga pri usposabljanju.
Če nadaljujemo, YOLOv7 uporablja drugačno metodo za dodelitev oznak. Običajno se dodeljevanje oznak uporablja za ustvarjanje oznak z neposrednim sklicevanjem na osnovno resnico in na podlagi danega nabora pravil. Vendar imata v zadnjih letih porazdelitev in kakovost vnosa napovedi pomembno vlogo pri ustvarjanju zanesljive oznake. YOLOv7 ustvari mehko oznako predmeta z uporabo napovedi omejevalne škatle in temeljne resnice.
Poleg tega nova metoda dodeljevanja oznak algoritma YOLOv7 uporablja napovedi vodilne glave za vodenje tako vodilne kot pomožne glave. Metoda dodeljevanja oznak ima dve predlagani strategiji.
Glavni vodeni dodeljevalec etiket
Strategija naredi izračune na podlagi rezultatov napovedi vodilne glave in osnovne resnice, nato pa uporabi optimizacijo za ustvarjanje mehkih oznak. Te mehke oznake se nato uporabijo kot model za usposabljanje tako za vodilno glavo kot za pomožno glavo.
Strategija deluje na predpostavki, da bi morale biti oznake, ki jih ustvari, bolj reprezentativne in korelirati med virom in ciljem, ker ima vodilna glava večjo sposobnost učenja.
Vodeni dodeljevalec nalepk s svinčeno glavo od grobega do finega
Ta strategija prav tako naredi izračune na podlagi rezultatov napovedi vodilne glave in resnice o terenu, nato pa uporabi optimizacijo za ustvarjanje mehkih oznak. Vendar pa obstaja ključna razlika. V tej strategiji sta dva sklopa mehkih oznak, groba raven, in lepa etiketa.
Grobo oznako ustvarimo s sprostitvijo omejitev pozitivnega vzorca
postopek dodelitve, ki več mrež obravnava kot pozitivne cilje. To je narejeno, da bi se izognili tveganju izgube informacij zaradi šibkejše učne moči pomožne glave.

Zgornja slika pojasnjuje uporabo vrečke brezplačnih izdelkov, ki jo je mogoče učiti, v algoritmu YOLOv7. Prikazuje grobo za pomožno glavo in fino za svinčeno glavo. Ko primerjamo model s pomožno glavo (b) z običajnim modelom (a), bomo opazili, da ima shema v (b) pomožno glavo, medtem ko je v (a) ni.
Slika (c) prikazuje skupni neodvisni dodeljevalec oznak, medtem ko slika (d) in slika (e) predstavljata vodilni vodeni dodeljevalec in vodilni dodeljevalnik od grobega do finega, ki ju uporablja YOLOv7.
Druga vrečka brezplačnih izdelkov, ki jo je mogoče usposobiti
Poleg zgoraj omenjenih algoritem YOLOv7 uporablja dodatne vrečke brezplačnih izdelkov, čeprav jih prvotno niso predlagali. So
- Paketna normalizacija v tehnologiji Conv-Bn-Activation: Ta strategija se uporablja za neposredno povezavo konvolucijske plasti s paketno normalizacijsko plastjo.
- Implicitno znanje v YOLOR: YOLOv7 združuje strategijo z zemljevidom funkcij Convolutional.
- Model EMA: Model EMA se uporablja kot končni referenčni model v YOLOv7, čeprav je njegova primarna uporaba v metodi srednjega učitelja.
YOLOv7 : Eksperimenti
Eksperimentalna namestitev
Algoritem YOLOv7 uporablja Nabor podatkov Microsoft COCO za usposabljanje in potrjevanje njihov model zaznavanja objektov in vsi ti poskusi ne uporabljajo vnaprej usposobljenega modela. Razvijalci so za usposabljanje uporabili nabor podatkov o vlakih iz leta 2017, za izbiro hiperparametrov pa so uporabili nabor podatkov o validaciji iz leta 2017. Končno se uspešnost rezultatov zaznavanja objektov YOLOv7 primerja z najsodobnejšimi algoritmi za zaznavanje predmetov.
Razvijalci so oblikovali osnovni model za robni grafični procesor (YOLOv7-tiny), običajni grafični procesor (YOLOv7) in grafični procesor v oblaku (YOLOv7-W6). Poleg tega algoritem YOLOv7 uporablja tudi osnovni model za skaliranje modela glede na različne storitvene zahteve in dobi različne modele. Pri algoritmu YOLOv7 se skaliranje sklada izvaja na vratu, predlagane spojine pa se uporabljajo za povečanje globine in širine modela.
Osnovne črte
Algoritem YOLOv7 uporablja prejšnje modele YOLO in algoritem za odkrivanje objektov YOLOR kot osnovo.

Zgornja slika primerja osnovno linijo modela YOLOv7 z drugimi modeli za zaznavanje predmetov in rezultati so precej očitni. V primerjavi z Algoritem YOLOv4, YOLOv7 ne samo, da uporablja 75 % manj parametrov, ampak uporablja tudi 15 % manj računanja in ima 0.4 % večjo natančnost.
Primerjava z najsodobnejšimi modeli detektorjev predmetov

Zgornja slika prikazuje rezultate primerjave YOLOv7 z najsodobnejšimi modeli zaznavanja predmetov za mobilne in splošne grafične procesorje. Opazimo lahko, da ima metoda, ki jo predlaga algoritem YOLOv7, najboljši rezultat kompromisa med hitrostjo in natančnostjo.
Ablacijska študija: Predlagana metoda skaliranja spojin

Zgornja slika primerja rezultate uporabe različnih strategij za povečevanje modela. Strategija skaliranja v modelu YOLOv7 poveča globino računalniškega bloka za 1.5-krat in širino za 1.25-krat.
V primerjavi z modelom, ki povečuje samo globino, je model YOLOv7 boljši za 0.5 %, medtem ko uporablja manj parametrov in računske moči. Po drugi strani pa je v primerjavi z modeli, ki povečajo le globino, natančnost YOLOv7 izboljšana za 0.2 %, vendar je treba število parametrov povečati za 2.9 % in izračun za 1.2 %.
Predlagani načrtovani re-parametrizirani model
Da bi preveril splošnost predlaganega ponovno parametriziranega modela, je Algoritem YOLOv7 ga za preverjanje uporablja na modelih, ki temeljijo na ostankih in na veriženju. Za postopek preverjanja uporablja algoritem YOLOv7 3-skladni ELAN za model, ki temelji na veriženju, in CSPDarknet za model, ki temelji na ostanku.
Za model, ki temelji na veriženju, algoritem nadomešča konvolucijske plasti 3 × 3 v 3-skladnem ELAN z RepConv. Spodnja slika prikazuje podrobno konfiguracijo programa Planned RepConv in 3-skladnega ELAN-a.
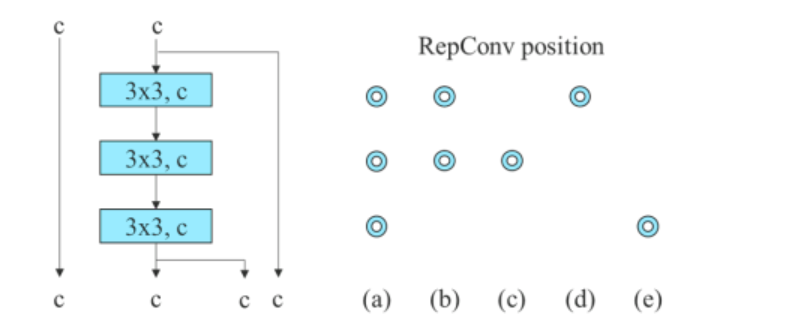
Poleg tega algoritem YOLOv7 pri obravnavi modela, ki temelji na ostankih, uporablja obrnjen temni blok, ker prvotni temni blok nima konvolucijskega bloka 3×3. Spodnja slika prikazuje arhitekturo obrnjenega CSPDarkneta, ki obrne položaje konvolucijske plasti 3×3 in 1×1. 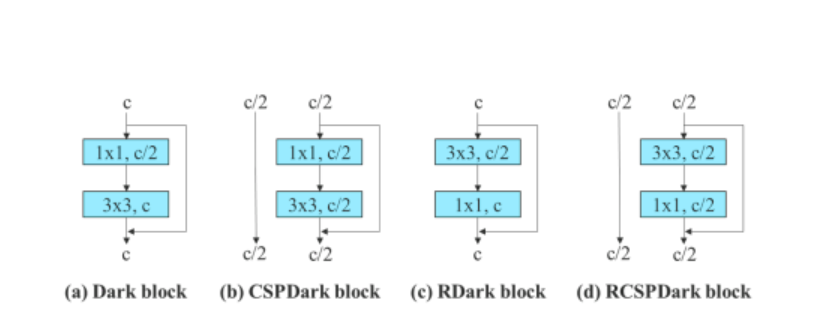
Predlagana izguba pomočnika za pomožnega vodjo
Za pomožno izgubo za pomožno glavo model YOLOv7 primerja neodvisno dodelitev oznak za metodi pomožne glave in vodilne glave.

Zgornja slika vsebuje rezultate študije o predlagani pomožni glavi. Vidimo lahko, da se splošna zmogljivost modela poveča s povečanjem izgube pomočnika. Poleg tega vodeno vodeno dodeljevanje oznak, ki ga predlaga model YOLOv7, deluje bolje kot neodvisne strategije dodeljevanja vodilnih strank.
Rezultati YOLOv7
Na podlagi zgornjih poskusov je tukaj rezultat zmogljivosti YOLov7 v primerjavi z drugimi algoritmi za zaznavanje predmetov.

Zgornja slika primerja model YOLOv7 z drugimi algoritmi za zaznavanje objektov in jasno je razvidno, da YOLOv7 prekaša druge modele za zaznavanje ugovorov v smislu Povprečna natančnost (AP) v/s šaržne motnje.
Poleg tega spodnja slika primerja zmogljivost YOLOv7 v primerjavi z drugimi algoritmi za zaznavanje ugovorov v realnem času. Ponovno YOLOv7 uspeva drugim modelom v smislu splošne zmogljivosti, natančnosti in učinkovitosti.

Tukaj je nekaj dodatnih opažanj iz rezultatov in uspešnosti YOLOv7.
- YOLOv7-Tiny je najmanjši model v družini YOLO z več kot 6 milijoni parametrov. YOLOv7-Tiny ima povprečno natančnost 35.2 % in s primerljivimi parametri prekaša modele YOLOv4-Tiny.
- Model YOLOv7 ima več kot 37 milijonov parametrov in prekaša modele z višjimi parametri, kot je YOLov4.
- Model YOLOv7 ima najvišjo hitrost mAP in FPS v razponu od 5 do 160 FPS.
zaključek
YOLO ali You Only Look Once je najsodobnejši model zaznavanja predmetov v sodobnem računalniškem vidu. Algoritem YOLO je znan po svoji visoki natančnosti in učinkovitosti, posledično pa najde široko uporabo v industriji odkrivanja predmetov v realnem času. Odkar je bil leta 2016 predstavljen prvi algoritem YOLO, so eksperimenti razvijalcem omogočili nenehno izboljševanje modela.
Model YOLOv7 je najnovejši dodatek v družini YOLO in je najzmogljivejši algoritem YOLo do danes. V tem članku smo govorili o osnovah YOLOv7 in poskušali razložiti, zakaj je YOLOv7 tako učinkovit.















