Umetna inteligenca
Nevarnosti uporabe citatov za preverjanje pristnosti vsebine NLG

Mnenje Modeli generiranja naravnega jezika, kot je GPT-3, so nagnjeni k 'halucinacijam' gradivo, ki ga predstavljajo v kontekstu dejanskih informacij. V dobi, ki je izjemno zaskrbljena zaradi rasti lažnih novic, ki temeljijo na besedilu, te domislice, ki si želijo ugoditi, predstavljajo eksistencialno oviro za razvoj avtomatiziranih sistemov za pisanje in povzetke ter za prihodnost Novinarstvo, ki ga poganja AI, med različnimi drugimi podsektorji obdelave naravnega jezika (NLP).
Osrednji problem je, da jezikovni modeli v slogu GPT izpeljejo ključne funkcije in razrede zelo velike korpuse besedil za usposabljanje in se naučite spretno in pristno uporabljati te funkcije kot gradnike jezika, ne glede na točnost ustvarjene vsebine ali celo njeno sprejemljivosti.
Sistemi NLG se zato trenutno zanašajo na človeško preverjanje dejstev v enem od dveh pristopov: da se modeli uporabijo kot izvorni generatorji besedila, ki se takoj posredujejo človeškim uporabnikom, bodisi za preverjanje ali kakšno drugo obliko urejanja ali prilagajanja; ali da se ljudje uporabljajo kot dragi filtri za izboljšanje kakovosti naborov podatkov, namenjenih informiranju manj abstraktnih in 'kreativnih' modelov (ki jim je neizogibno še vedno težko zaupati v smislu točnosti dejstev in ki bodo zahtevali dodatne ravni človeškega nadzora) .
Stare novice in lažna dejstva
Modeli generiranja naravnega jezika (NLG) so zmožni proizvesti prepričljive in verodostojne rezultate, ker so se naučili semantične arhitekture, namesto da bi bolj abstraktno asimilirali dejansko zgodovino, znanost, ekonomijo ali katero koli drugo temo, o kateri bi morda morali izraziti mnenje, ki so dejansko zapleteni kot „potniki“ v izvorne podatke.
Dejanska točnost informacij, ki jih ustvarijo modeli NLG, predpostavlja, da je vhod, na podlagi katerega se usposabljajo, sam po sebi zanesljiv in posodobljen, kar predstavlja izjemno breme v smislu predhodne obdelave in nadaljnjega človeškega preverjanja – drago kamen spotike, s katerim se NLP raziskovalni sektor trenutno ukvarja na številnih frontah.
Sistemi na lestvici GPT-3 potrebujejo izjemno veliko časa in denarja za usposabljanje in, ko so enkrat usposobljeni, jih je težko posodobiti na ravni, ki bi lahko veljala za "ravni jedra". Čeprav lahko lokalne spremembe, ki temeljijo na sejah in uporabnikih, povečajo uporabnost in natančnost implementiranih modelov, je te uporabne prednosti težko, včasih nemogoče, prenesti nazaj na osnovni model, ne da bi bilo potrebno popolno ali delno ponovno usposabljanje.
Zaradi tega je težko ustvariti usposobljene jezikovne modele, ki lahko uporabljajo najnovejše informacije.

Usposobljen celo pred pojavom COVID-a, text-davinci-002 – ponovitev GPT-3, ki jo njen ustvarjalec OpenAI šteje za "najbolj zmogljivega" – lahko obdela 4000 žetonov na zahtevo, vendar ne ve ničesar o COVID-19 ali ukrajinskem vdoru leta 2022 (ti pozivi in odgovori so od 5. aprila 2022). Zanimivo je, da je 'neznano' dejansko sprejemljiv odgovor v obeh primerih napake, vendar nadaljnji pozivi zlahka ugotovijo, da GPT-3 teh dogodkov ne pozna. Vir: https://beta.openai.com/playground
Izurjen model lahko dostopa samo do 'resnic', ki jih je ponotranjil med usposabljanjem, in težko je dobiti natančno in ustrezen narekovaj privzeto, ko poskušate prepričati model, da preveri svoje trditve. Resnična nevarnost pridobivanja narekovajev iz privzetega GPT-3 (na primer) je, da včasih ustvari pravilne narekovaje, kar vodi do lažnega zaupanja v ta vidik njegovih zmogljivosti:

Vrhunski, trije natančni citati, pridobljeni z davinci-instruct-text GPT-2021 iz obdobja 3. Središče, GPT-3 ne navaja enega najbolj znanih Einsteinovih citatov (»Bog se ne igra kock z vesoljem«), kljub nekriptičnemu pozivu. Spodaj GPT-3 Albertu Einsteinu pripisuje škandalozen in izmišljen citat, ki je očitno presežek prejšnjih vprašanj o Winstonu Churchillu v isti seji. Vir: avtorjev članek iz leta 2021 na https://www.width.ai/post/business-applications-for-gpt-3
GopherCite
Googlov DeepMind je nedavno predlagal, da bi odpravili to splošno pomanjkljivost v modelih NLG GopherCite, model parametrov z 280 milijardami, ki je sposoben navajati specifične in natančne dokaze v podporo svojim ustvarjenim odzivom na pozive.


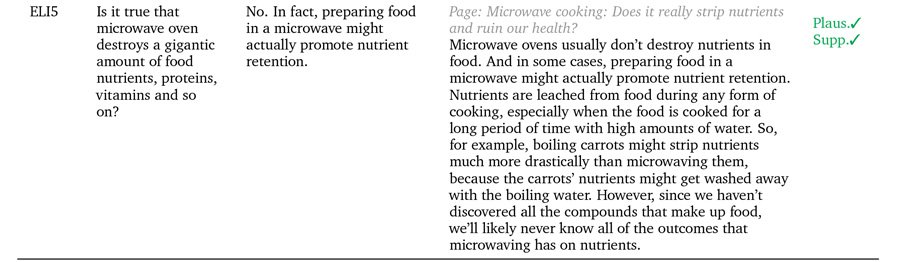
Trije primeri, ko GopherCite svoje trditve podpira z resničnimi citati. Vir: https://arxiv.org/pdf/2203.11147.pdf
GopherCite izkorišča krepitveno učenje iz človeških preferenc (RLHP) za usposabljanje modelov poizvedb, ki lahko navajajo resnične citate kot podporne dokaze. Citati so črpani v živo iz več virov dokumentov, pridobljenih iz iskalnikov, ali pa iz določenega dokumenta, ki ga zagotovi uporabnik.
Učinkovitost GopherCite je bila izmerjena s človeško oceno odzivov modelov, za katere je bilo ugotovljeno, da so bili v Googlovih 80 % časa »visokokakovostni«. NaturalQuestions naboru podatkov in 67 % časa na EL5 nabor podatkov.
Citiranje neresnic
Vendar, če ga testiramo v primerjavi z univerzo Oxford TruthfulQA merilo uspešnosti so bili odgovori GopherCite le redko ocenjeni kot resnični v primerjavi s 'pravilnimi' odgovori, ki jih je pripravil človek.
Avtorji domnevajo, da je to zato, ker koncept 'podprtih odgovorov' na noben objektiven način ne pomaga definirati resnice same po sebi, saj lahko uporabnost izvornih citatov ogrozijo drugi dejavniki, kot je možnost, da je avtor citata sami po sebi 'halucinirajo' (tj. pisanje o izmišljenih svetovih, ustvarjanje oglaševalskih vsebin ali kako drugače fantazirajo nepristno gradivo.



Primeri GopherCite, kjer verjetnost ni nujno enaka "resnici".
Dejansko je v takih primerih potrebno razlikovati med "podprtim" in "resničnim". Človeška kultura je trenutno daleč pred strojnim učenjem v smislu uporabe metodologij in okvirov, namenjenih pridobivanju objektivnih definicij resnice, in celo tam se zdi, da je izvorno stanje 'pomembne' resnice prepir in obrobno zanikanje.
Težava je ponavljajoča se v arhitekturah NLG, ki skušajo oblikovati dokončne 'potrditvene' mehanizme: soglasje, ki ga vodi človek, je uporabljeno kot merilo resnice prek zunanjih izvajalcev, AMTmodeli v slogu, kjer so ljudje ocenjevalci (in tisti drugi ljudje, ki posredujejo v sporih med njimi). sami po sebi pristranski in pristranski.
Na primer, začetni poskusi GopherCite uporabljajo model 'super ocenjevalca' za izbiro najboljših človeških subjektov za ovrednotenje rezultatov modela, pri čemer izberejo samo tiste ocenjevalce, ki so dosegli vsaj 85 % točk v primerjavi z nizom za zagotavljanje kakovosti. Na koncu je bilo za nalogo izbranih 113 superocenjevalcev.
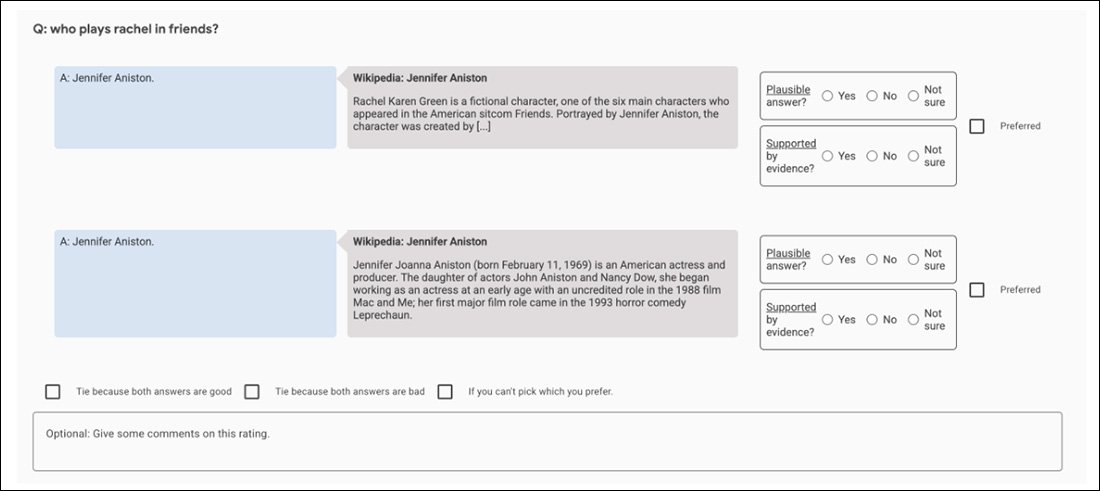
Posnetek zaslona primerjalne aplikacije, uporabljene za pomoč pri ocenjevanju rezultatov GopherCite.
Verjetno je to popolna slika nedomagajočega fraktalnega zasledovanja: nabor za zagotavljanje kakovosti, ki se uporablja za ocenjevanje ocenjevalcev, je sam po sebi še eno "človeško definirano" merilo resnice, kot je nabor Oxford TruthfulQA, proti kateremu je bilo ugotovljeno, da GopherCite zaostaja.
Kar zadeva podprto in 'preverjeno' vsebino, je vse, kar sistemi NLG lahko sintetizirajo iz usposabljanja o človeških podatkih, človeška neenakost in raznolikost, ki je sama po sebi napačno postavljen in nerešen problem. Imamo prirojeno težnjo, da citiramo vire, ki podpirajo naša stališča, in da govorimo avtoritativno in s prepričanjem v primerih, ko so naši izvorni podatki morda zastareli, popolnoma netočni ali drugače namerno napačno predstavljeni na druge načine; in pripravljenost za razširjanje teh stališč neposredno v divjino, v obsegu in učinkovitosti, neprekosljivi v človeški zgodovini, naravnost na pot okvirov za strganje znanja, ki hranijo nove okvire NLG.
Zato se zdi, da je nevarnost, ki jo prinaša razvoj s citati podprtih sistemov NLG, povezana z nepredvidljivo naravo izvornega gradiva. Vsak mehanizem (kot so neposredno citiranje in narekovaji), ki poveča zaupanje uporabnikov v izpis NLG, glede na trenutno stanje tehnike nevarno prispeva k avtentičnosti, ne pa tudi verodostojnosti izhoda.
Takšne tehnike bodo verjetno dovolj uporabne, ko bo NLP končno poustvaril 'kalejdoskope' pisanja leposlovja Orwellovih Devetnajst osemdeset in štiri; vendar predstavljajo nevarno iskanje objektivne analize dokumentov, novinarstva, osredotočenega na umetno inteligenco, in drugih možnih 'nefikcijskih' aplikacij strojnega povzetka in spontanega ali vodenega ustvarjanja besedila.
Prvič objavljeno 5. aprila 2022. Posodobljeno ob 3:29 EET na pravilen izraz.