
Umetna inteligenca
Strojno učenje proti globokemu učenju – ključne razlike
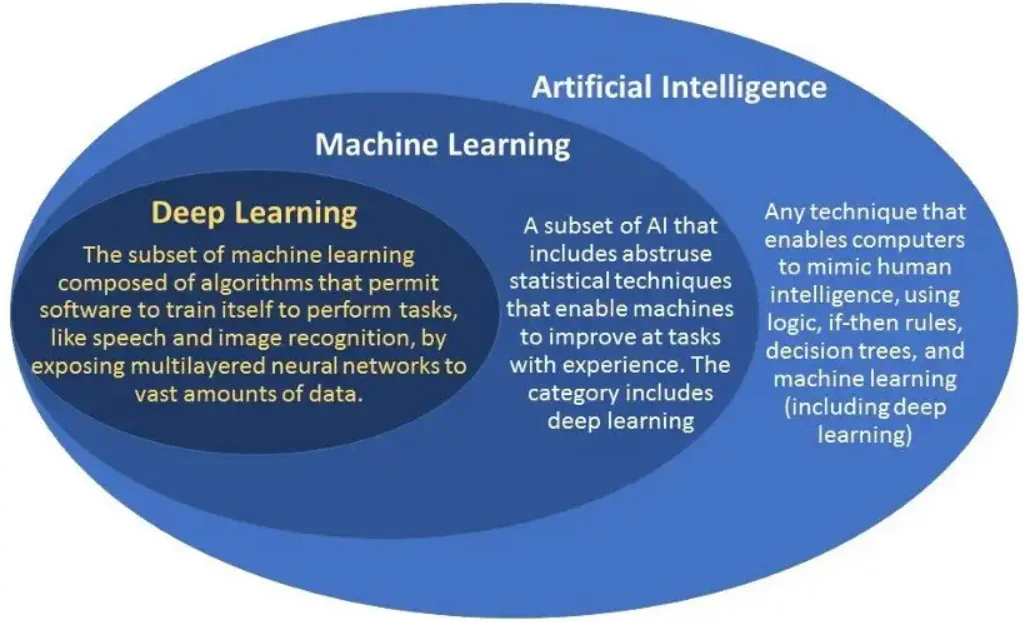
Terminologije, kot so umetna inteligenca (AI), strojno učenje (ML) in globoko učenje, so dandanes zelo priljubljene. Ljudje pa te izraze pogosto uporabljajo zamenljivo. Čeprav so ti izrazi med seboj zelo povezani, imajo tudi posebne lastnosti in posebne primere uporabe.
AI se ukvarja z avtomatiziranimi stroji, ki rešujejo probleme in sprejemajo odločitve, ki posnemajo človeške kognitivne sposobnosti. Strojno učenje in globoko učenje sta poddomeni umetne inteligence. Strojno učenje je umetna inteligenca, ki lahko napoveduje z minimalnim človeškim posredovanjem. Medtem ko je globoko učenje podmnožica strojnega učenja, ki uporablja nevronske mreže za sprejemanje odločitev s posnemanjem nevronskih in kognitivnih procesov človeškega uma.
Zgornja slika ponazarja hierarhijo. Nadaljevali bomo z razlago razlik med strojnim in globokim učenjem. Prav tako vam bo pomagal izbrati primerno metodologijo glede na njeno uporabo in področje osredotočanja. Pogovorimo se o tem podrobno.
Strojno učenje na kratko
Strojno učenje omogoča strokovnjakom, da "usposobijo" stroj tako, da analizirajo ogromne nabore podatkov. Več podatkov kot stroj analizira, natančnejše rezultate lahko ustvari s sprejemanjem odločitev in napovedmi za nevidene dogodke ali scenarije.
Modeli strojnega učenja potrebujejo strukturirane podatke za natančne napovedi in odločitve. Če podatki niso označeni in organizirani, jih modeli strojnega učenja ne morejo natančno razumeti in postanejo domena globokega učenja.
Zaradi razpoložljivosti ogromnih količin podatkov v organizacijah je strojno učenje postalo sestavni del odločanja. Motorji za priporočila so odličen primer modelov strojnega učenja. Storitve OTT, kot je Netflix, se naučijo vaših vsebinskih nastavitev in predlagajo podobno vsebino na podlagi vaših iskalnih navad in zgodovine ogledov.
Razumeti kako se usposabljajo modeli strojnega učenja, si najprej oglejmo vrste ML.
V strojnem učenju obstajajo štiri vrste metodologij.
- Nadzorovano učenje – za natančne rezultate potrebuje označene podatke. Pogosto zahteva učenje več podatkov in redne prilagoditve za izboljšanje rezultatov.
- Polnadzorovano – je srednja stopnja med nadzorovanim in nenadzorovanim učenjem, ki izkazuje funkcionalnost obeh področij. Lahko daje rezultate na delno označenih podatkih in ne zahteva stalnih prilagoditev za zagotavljanje točnih rezultatov.
- Učenje brez nadzora – odkrije vzorce in vpoglede v nizih podatkov brez človeškega posredovanja in daje natančne rezultate. Združevanje v gruče je najpogostejša uporaba nenadzorovanega učenja.
- Učenje s krepitvijo – model učenja s krepitvijo zahteva stalne povratne informacije ali krepitev, ko prihajajo nove informacije, ki dajejo natančne rezultate. Uporablja tudi "funkcijo nagrajevanja", ki omogoča samoučenje z nagrajevanjem želenih rezultatov in kaznovanjem napačnih.
Globoko učenje na kratko
Modeli strojnega učenja potrebujejo človeško posredovanje za izboljšanje natančnosti. Ravno nasprotno, modeli globokega učenja se izboljšajo po vsakem rezultatu brez človeškega nadzora. Toda pogosto zahteva podrobnejše in daljše količine podatkov.
Metodologija globokega učenja oblikuje prefinjen učni model, ki temelji na nevronskih mrežah, ki jih je navdihnil človeški um. Ti modeli imajo več plasti algoritmov, imenovanih nevroni. Še naprej se izboljšujejo brez človeškega posredovanja, tako kot kognitivni um, ki se nenehno izboljšuje in razvija s prakso, ponovnimi obiski in časom.
Modeli globokega učenja se uporabljajo predvsem za klasifikacijo in ekstrakcijo funkcij. Globoki modeli se na primer hranijo z naborom podatkov pri prepoznavanju obraza. Model ustvari večdimenzionalne matrike za zapomnitev vsake obrazne poteze kot slikovnih pik. Ko ga prosite, naj prepozna sliko osebe, ki ji ni bil izpostavljen, jo zlahka prepozna tako, da se ujema z omejenimi potezami obraza.
- Konvolucijske nevronske mreže (CNN) – Konvolucija je postopek dodeljevanja uteži različnim objektom slike. Na podlagi teh dodeljenih uteži ga model CNN prepozna. Rezultati temeljijo na tem, kako blizu so te uteži teži predmeta, ki se dovaja kot vlak.
- Ponavljajoča se nevronska mreža (RNN) – Za razliko od CNN, model RNN ponovno pregleda prejšnje rezultate in podatkovne točke za natančnejše odločitve in napovedi. To je dejanska replika človeške kognitivne funkcije.
- Generativna kontradiktorna omrežja (GAN) – dva klasifikatorja v GAN, generator in diskriminator, dostopata do istih podatkov. Generator ustvari lažne podatke tako, da vključi povratne informacije diskriminatorja. Diskriminator poskuša razvrstiti, ali so podani podatki resnični ali lažni.
Glavne razlike
Spodaj je nekaj opaznih razlik.
| Razlike | strojno učenje | Globoko učenje |
| Človeški nadzor | Strojno učenje zahteva več nadzora. | Modeli globokega učenja po razvoju skoraj ne potrebujejo človeškega nadzora. |
| Viri strojne opreme | Programe za strojno učenje gradite in izvajate na zmogljivem CPE. | Modeli globokega učenja zahtevajo zmogljivejšo strojno opremo, kot so namenski grafični procesorji. |
| Čas in trud | Čas, potreben za postavitev modela strojnega učenja, je krajši od časa za poglobljeno učenje, vendar je njegova funkcionalnost omejena. | Za razvoj in usposabljanje podatkov z globokim učenjem potrebuje več časa. Ko je ustvarjen, s časom še naprej izboljšuje svojo natančnost. |
| Podatki (strukturirani/nestrukturirani) | Modeli strojnega učenja potrebujejo strukturirane podatke, da dajejo rezultate (razen nenadzorovanega učenja) in zahtevajo stalno človeško posredovanje za izboljšave. | Modeli globokega učenja lahko obdelujejo nestrukturirane in zapletene nize podatkov brez ogrožanja natančnosti. |
| Primeri uporabe | Spletna mesta za e-trgovino in storitve pretakanja, ki uporabljajo mehanizme za priporočila. | Vrhunske aplikacije, kot je avtopilot v letalih, samovozečih vozilih, roverjih na površini Marsa, prepoznavanje obrazov itd. |
Strojno učenje v primerjavi z globokim učenjem – kateri je najboljši?
Izbira med strojnim učenjem in globokim učenjem resnično temelji na njihovih primerih uporabe. Oba se uporabljata za izdelavo strojev s skoraj človeško inteligenco. Natančnost obeh modelov je odvisna od tega, ali uporabljate ustrezne KPI-je in atribute podatkov.
Strojno in globoko učenje bosta postala rutinski poslovni komponenti v panogah. Nedvomno bo umetna inteligenca v bližnji prihodnosti popolnoma avtomatizirala industrijske dejavnosti, kot so letalstvo, vojskovanje in avtomobili.
Če želite izvedeti več o AI in o tem, kako nenehno spreminja poslovne rezultate, preberite več člankov o združiti.ai.















