
Umelá inteligencia
Strojové učenie vs. hlboké učenie – kľúčové rozdiely
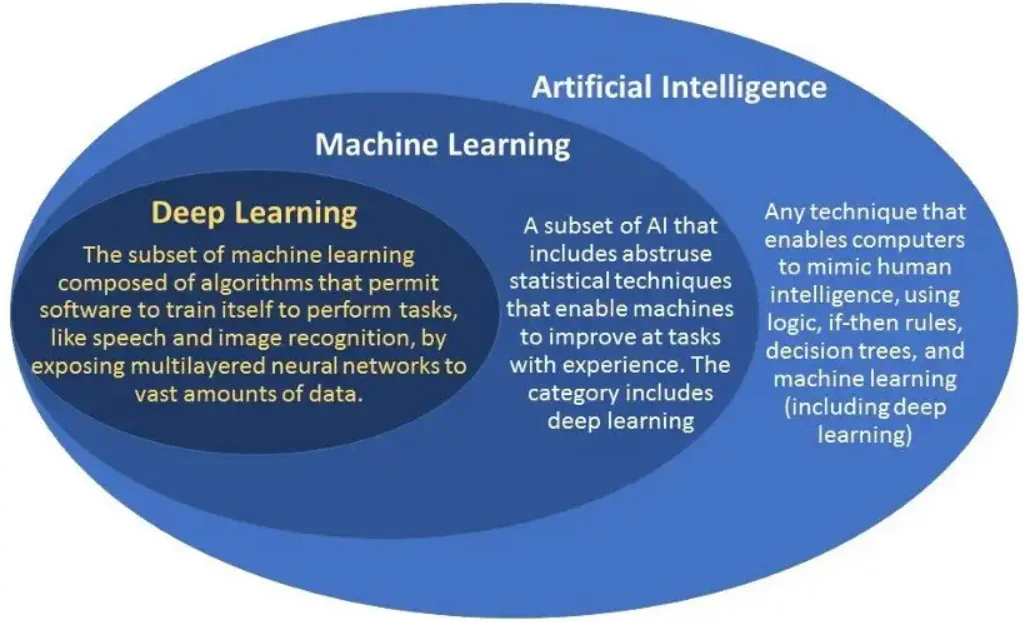
Terminológie ako umelá inteligencia (AI), strojové učenie (ML) a hlboké učenie sú v dnešnej dobe hype. Ľudia však tieto výrazy často používajú zameniteľne. Aj keď tieto výrazy navzájom vysoko súvisia, majú aj charakteristické črty a špecifické prípady použitia.
AI sa zaoberá automatizovanými strojmi, ktoré riešia problémy a robia rozhodnutia napodobňujúce ľudské kognitívne schopnosti. Strojové učenie a hlboké učenie sú subdomény AI. Strojové učenie je AI, ktorá dokáže predpovedať s minimálnym zásahom človeka. Zatiaľ čo hlboké učenie je podmnožinou strojového učenia, ktoré využíva neurónové siete na rozhodovanie napodobňovaním neurónových a kognitívnych procesov ľudskej mysle.
Vyššie uvedený obrázok ilustruje hierarchiu. Budeme pokračovať vo vysvetľovaní rozdielov medzi strojovým učením a hlbokým učením. Pomôže vám aj pri výbere vhodnej metodiky na základe jej aplikácie a oblasti zamerania. Poďme si to podrobne rozobrať.
Strojové učenie v skratke
Strojové učenie umožňuje odborníkom „trénovať“ stroj tým, že analyzuje rozsiahle súbory údajov. Čím viac údajov stroj analyzuje, tým presnejšie výsledky môže produkovať prijímaním rozhodnutí a predpovedí pre neviditeľné udalosti alebo scenáre.
Modely strojového učenia potrebujú štruktúrované údaje, aby mohli robiť presné predpovede a rozhodnutia. Ak údaje nie sú označené a usporiadané, modely strojového učenia ich nedokážu presne pochopiť a stávajú sa doménou hlbokého učenia.
Vďaka dostupnosti obrovských objemov údajov v organizáciách sa strojové učenie stalo neoddeliteľnou súčasťou rozhodovania. Nástroje odporúčaní sú dokonalým príkladom modelov strojového učenia. Služby OTT, ako je Netflix, sa učia vaše preferencie obsahu a navrhujú podobný obsah na základe vašich zvykov vyhľadávania a histórie pozerania.
Rozumieť ako sa trénujú modely strojového učeniapozrime sa najprv na typy ML.
Existujú štyri typy metodík strojového učenia.
- Učenie pod dohľadom – potrebuje označené údaje, aby poskytovalo presné výsledky. Na zlepšenie výsledkov si to často vyžaduje získanie ďalších údajov a pravidelné úpravy.
- Semi-supervised – Je to stredná vrstva medzi kontrolovaným a nekontrolovaným učením, ktoré vykazuje funkčnosť oboch domén. Môže poskytnúť výsledky na čiastočne označených údajoch a na poskytnutie presných výsledkov nevyžaduje priebežné úpravy.
- Učenie bez dozoru – Odhaľuje vzorce a poznatky v súboroch údajov bez ľudského zásahu a poskytuje presné výsledky. Klastrovanie je najbežnejšou aplikáciou učenia bez dozoru.
- Posilňovacie učenie – Model posilňovacieho učenia si vyžaduje neustálu spätnú väzbu alebo posilňovanie, pretože nové informácie poskytujú presné výsledky. Používa tiež „funkciu odmeňovania“, ktorá umožňuje samoučenie odmeňovaním požadovaných výsledkov a penalizáciou nesprávnych.
Hlboké učenie v skratke
Modely strojového učenia vyžadujú ľudský zásah na zlepšenie presnosti. Naopak, modely hlbokého učenia sa po každom výsledku bez ľudského dohľadu zdokonaľujú. Často si to však vyžaduje podrobnejšie a zdĺhavejšie objemy údajov.
Metodológia hlbokého učenia navrhuje sofistikovaný model učenia založený na neurónových sieťach inšpirovaných ľudskou mysľou. Tieto modely majú viacero vrstiev algoritmov nazývaných neuróny. Pokračujú v zlepšovaní bez ľudského zásahu, ako je kognitívna myseľ, ktorá sa neustále zlepšuje a vyvíja praxou, opakovanými návštevami a časom.
Modely hlbokého učenia sa používajú hlavne na klasifikáciu a extrakciu funkcií. Napríklad hlboké modely sa živia súborom údajov v rozpoznávaní tváre. Model vytvára viacrozmerné matice na zapamätanie každej funkcie tváre ako pixelov. Keď ho požiadate, aby rozpoznal obrázok osoby, ktorej nebol vystavený, ľahko ho rozpozná podľa zhody s obmedzenými črtami tváre.
- Konvolučné neurónové siete (CNN) – Konvolúcia je proces priraďovania váh rôznym objektom na obrázku. Na základe týchto priradených váh to model CNN rozpozná. Výsledky sú založené na tom, ako blízko sú tieto hmotnosti k hmotnosti objektu napájaného ako vlaková súprava.
- Rekurentná neurónová sieť (RNN) – Na rozdiel od CNN model RNN prehodnocuje predchádzajúce výsledky a dátové body, aby mohol robiť presnejšie rozhodnutia a predpovede. Je to skutočná replika ľudskej kognitívnej funkcie.
- Generative Adversarial Networks (GAN) – Dva klasifikátory v GAN, generátor a diskriminátor, majú prístup k rovnakým údajom. Generátor vytvára falošné údaje začlenením spätnej väzby z diskriminátora. Diskriminátor sa snaží klasifikovať, či sú dané údaje skutočné alebo falošné.
Výrazné rozdiely
Nižšie sú uvedené niektoré pozoruhodné rozdiely.
| Rozdiely | Strojové učenie | Deep Learning |
| Ľudský dohľad | Strojové učenie si vyžaduje väčší dohľad. | Modely hlbokého učenia nevyžadujú po vývoji takmer žiadny ľudský dohľad. |
| Hardvérové zdroje | Vytvárate a spúšťate programy strojového učenia na výkonnom procesore. | Modely hlbokého učenia vyžadujú výkonnejší hardvér, ako sú vyhradené GPU. |
| Čas a úsilie | Čas potrebný na nastavenie modelu strojového učenia je kratší ako pri hĺbkovom učení, ale jeho funkčnosť je obmedzená. | Vývoj a trénovanie údajov pomocou hlbokého učenia si vyžaduje viac času. Po vytvorení pokračuje v zlepšovaní svojej presnosti s časom. |
| Údaje (štruktúrované/neštruktúrované) | Modely strojového učenia potrebujú štruktúrované údaje, aby poskytovali výsledky (okrem učenia bez dozoru) a na zlepšenie vyžadujú neustály ľudský zásah. | Modely hlbokého učenia dokážu spracovať neštruktúrované a zložité súbory údajov bez kompromisov v presnosti. |
| Prípady použitia | webové stránky elektronického obchodu a streamingové služby, ktoré používajú nástroje na odporúčanie. | Špičkové aplikácie ako Autopilot v lietadlách, samoriadiace vozidlá, Rovery na povrchu Marsu, rozpoznávanie tváre atď. |
Strojové učenie vs. hlboké učenie – ktorý z nich je najlepší?
Voľba medzi strojovým učením a hlbokým učením je skutočne založená na ich prípadoch použitia. Obe sa používajú na výrobu strojov s inteligenciou blízkou ľudskej. Presnosť oboch modelov závisí od toho, či používate príslušné KPI a atribúty údajov.
Strojové učenie a hlboké učenie sa stanú rutinnými obchodnými komponentmi v rôznych odvetviach. Umelá inteligencia nepochybne v blízkej budúcnosti plne zautomatizuje priemyselné činnosti, ako je letectvo, vojna a automobily.
Ak sa chcete dozvedieť viac o AI a o tom, ako neustále mení obchodné výsledky, prečítajte si ďalšie články na tému zjednotiť.ai.















