
Best Of
10 najlepších algoritmov strojového učenia
Aj keď žijeme v období mimoriadnych inovácií v oblasti strojového učenia akcelerovaného GPU, najnovšie výskumné práce často (a prominentne) obsahujú algoritmy, ktoré sú desaťročia staré, v niektorých prípadoch 70 rokov staré.
Niektorí by mohli tvrdiť, že mnohé z týchto starších metód spadajú skôr do tábora „štatistickej analýzy“ než strojového učenia a uprednostňujú datovať nástup tohto sektora až do roku 1957, kedy vynález perceptrónu.
Vzhľadom na to, do akej miery tieto staršie algoritmy podporujú a sú začlenené do najnovších trendov a najvýznamnejšieho vývoja v oblasti strojového učenia, je to sporný postoj. Poďme sa teda pozrieť na niektoré z „klasických“ stavebných blokov, ktoré sú základom najnovších inovácií, ako aj na niektoré novšie položky, ktoré sa čoskoro uchádzajú o vstup do siene slávy AI.
1: Transformátory
V roku 2017 Google Research viedol výskumnú spoluprácu, ktorá vyvrcholila v papier Pozornosť je všetko, čo potrebujete. Práca načrtla novú architektúru, ktorá sa propagovala mechanizmy pozornosti od „potrubia“ v modeloch kódovača/dekodéra a rekurentnej siete až po centrálnu transformačnú technológiu ako takú.
Prístup bol dabovaný Transformer, a odvtedy sa stala revolučnou metodológiou v spracovaní prirodzeného jazyka (NLP), ktorá okrem mnohých iných príkladov poháňa autoregresívny jazykový model a umelú inteligenciu poster-child GPT-3.
![]()
Transformers elegantne vyriešili problém sekvenčná transdukcia, tiež nazývaná „transformácia“, ktorá sa zaoberá spracovaním vstupných sekvencií na výstupné sekvencie. Transformátor tiež prijíma a spravuje údaje nepretržitým spôsobom, a nie v sekvenčných dávkach, čo umožňuje „perzistenciu pamäte“, na ktorú nie sú navrhnuté architektúry RNN. Podrobnejší prehľad transformátorov nájdete na náš referenčný článok.
Na rozdiel od rekurentných neurónových sietí (RNN), ktoré začali dominovať výskumu ML v ére CUDA, architektúra transformátora mohla byť tiež ľahko paralelizované, čím sa otvára cesta k produktívnemu adresovaniu oveľa väčšieho súboru údajov ako RNN.
Populárne použitie
Transformers zaujali verejnú predstavivosť v roku 2020 vydaním OpenAI GPT-3, ktorý sa pýšil vtedy rekordným 175 miliárd parametrov. Tento zdanlivo ohromujúci úspech bol nakoniec zatienený neskoršími projektmi, ako napríklad 2021 uvoľnite Microsoft Megatron-Turing NLG 530B, ktorý (ako už názov napovedá) obsahuje viac ako 530 miliárd parametrov.

Časová os hyperškálových projektov Transformer NLP. zdroj: Microsoft
Architektúra transformátora tiež prešla od NLP k počítačovému videniu, čím napája a Nová generácia rámcov na syntézu obrazu, ako je OpenAI CLIP a DALL-E, ktoré používajú mapovanie textových>obrázkových domén na dokončenie neúplných obrázkov a syntetizovanie nových obrázkov z trénovaných domén v rámci rastúceho počtu súvisiacich aplikácií.

DALL-E sa pokúša dokončiť čiastočný obraz Platónovej busty. Zdroj: https://openai.com/blog/dall-e/
2: Generative Adversarial Networks (GAN)
Hoci transformátory získali mimoriadne mediálne pokrytie vydaním a prijatím GPT-3, Generatívna kontradiktórna sieť (GAN) sa stala uznávanou značkou sama o sebe a môže sa nakoniec pripojiť deepfake ako sloveso.
Prvý navrhovaný v 2014 a primárne sa používa na syntézu obrazu, Generative Adversarial Network architektúra je zložený z a Generator a Diskriminátor. Generátor cyklicky prechádza tisíckami obrázkov v súbore údajov a opakovane sa ich pokúša rekonštruovať. Za každý pokus Diskriminátor ohodnotí prácu Generátora a pošle Generátora späť, aby to urobil lepšie, ale bez akéhokoľvek nahliadnutia do spôsobu, akým predchádzajúca rekonštrukcia chybovala.

Zdroj: https://developers.google.com/machine-learning/gan/gan_structure
To núti Generátora preskúmať množstvo ciest namiesto toho, aby sledoval potenciálne slepé uličky, ktoré by viedli, ak by mu Diskriminátor povedal, kde je chyba (pozri #8 nižšie). Po skončení školenia má Generátor podrobnú a komplexnú mapu vzťahov medzi bodmi v súbore údajov.

Z papiera Zlepšenie rovnováhy GAN zvyšovaním priestorového povedomia: nový rámec prechádza niekedy tajomným latentným priestorom GAN a poskytuje citlivú inštrumentáciu pre architektúru syntézy obrazu. Zdroj: https://genforce.github.io/eqgan/
Analogicky je to rozdiel medzi učením sa jednej nudnej cesty do centra Londýna alebo starostlivým získavaním Vedomosť.
Výsledkom je kolekcia funkcií na vysokej úrovni v latentnom priestore trénovaného modelu. Sémantický indikátor funkcie vysokej úrovne môže byť „osoba“, zatiaľ čo zostup prostredníctvom špecifickosti súvisiacej s vlastnosťou môže odhaliť ďalšie naučené charakteristiky, ako napríklad „muž“ a „žena“. Na nižších úrovniach sa čiastkové znaky môžu rozložiť na „blond“, „kaukazský“ a kol.
Zapletenie je pozoruhodný problém v latentnom priestore GAN a rámcov kódovača/dekodéra: je úsmev na ženskej tvári vygenerovanej GAN zapletenou črtou jej „identity“ v latentnom priestore, alebo je to paralelná vetva?

Tváre vygenerované GAN od tejto osoby neexistujú. Zdroj: https://this-person-does-not-exist.com/en
Posledných pár rokov prinieslo rastúci počet nových výskumných iniciatív v tomto ohľade, čo možno pripravilo pôdu pre úpravy na úrovni funkcií v štýle Photoshopu pre skrytý priestor GAN, ale v súčasnosti je veľa transformácií efektívne. všetky alebo nič. Najmä vydanie EditGAN od NVIDIA z konca roku 2021 dosahuje a vysoká úroveň interpretovateľnosti v latentnom priestore pomocou sémantických segmentačných masiek.
Populárne použitie
Okrem ich (v skutočnosti dosť obmedzenej) účasti na populárnych deepfake videách sa za posledné štyri roky rozšírili siete GAN zamerané na obrázky/video, ktoré uchvátili výskumníkov aj verejnosť. Udržať krok so závratnou rýchlosťou a frekvenciou nových vydaní je výzva, hoci úložisko GitHub Úžasné aplikácie GAN má za cieľ poskytnúť komplexný zoznam.
Generatívne adverzné siete môžu teoreticky odvodzovať vlastnosti z akejkoľvek dobre zarámovanej domény, vrátane textu.
3: SVM
vznikal v 1963, Podporný vektorový stroj (SVM) je základný algoritmus, ktorý sa často objavuje v novom výskume. V rámci SVM vektory mapujú relatívnu dispozíciu údajových bodov v množine údajov podpora vektory vymedzujú hranice medzi rôznymi skupinami, znakmi alebo znakmi.
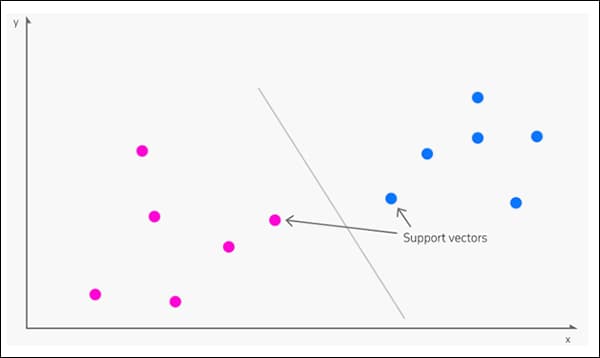
Podporné vektory definujú hranice medzi skupinami. Zdroj: https://www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html
Odvodená hranica sa nazýva a nadrovina.
Pri nízkych úrovniach funkcií je SVM dvojrozmerný (obrázok vyššie), ale tam, kde je rozpoznaný vyšší počet skupín alebo typov, sa stáva trojrozmerný.

Hlbšie pole bodov a skupín si vyžaduje trojrozmernú SVM. Zdroj: https://cml.rhul.ac.uk/svm.html
Populárne použitie
Keďže podpora Vector Machines dokáže efektívne a agnosticky riešiť vysokorozmerné dáta mnohých druhov, objavujú sa široko v rôznych sektoroch strojového učenia, vrátane detekcia deepfake, klasifikácia obrázkov, klasifikácia nenávistných prejavov, DNA analýza a predikcia štruktúry obyvateľstva, medzi mnohými ďalšími.
4: Klastrovanie K-Means
Klastrovanie vo všeobecnosti je učenie bez dozoru prístup, ktorý sa snaží kategorizovať dátové body prostredníctvom odhad hustoty, čím sa vytvorí mapa rozloženia skúmaných údajov.

K-Means zoskupuje božské segmenty, skupiny a komunity v údajoch. Zdroj: https://aws.amazon.com/blogs/machine-learning/k-means-clustering-with-amazon-sagemaker/
Klastrovanie K-Means sa stala najpopulárnejšou implementáciou tohto prístupu, zaraďovaním údajových bodov do charakteristických „K skupín“, ktoré môžu označovať demografické sektory, online komunity alebo akúkoľvek inú možnú tajnú agregáciu, ktorá čaká na odhalenie v nespracovaných štatistických údajoch.

Klastre sa tvoria v analýze K-Means. Zdroj: https://www.geeksforgeeks.org/ml-determine-the-optimal-value-of-k-in-k-means-clustering/
Samotná hodnota K je určujúcim faktorom v užitočnosti procesu a pri stanovení optimálnej hodnoty pre klaster. Na začiatku je hodnota K náhodne priradená a jej vlastnosti a vektorové charakteristiky sa porovnávajú s jej susedmi. Tí susedia, ktorí sa najviac podobajú dátovému bodu s náhodne priradenou hodnotou, sa priraďujú k jeho klastru iteratívne, kým údaje neposkytnú všetky zoskupenia, ktoré proces umožňuje.
Graf pre štvorcovú chybu alebo „náklady“ rôznych hodnôt medzi klastrami odhalí lakťový bod pre údaje:

„Bod lakťa“ v zhlukovom grafe. Zdroj: https://www.scikit-yb.org/en/latest/api/cluster/elbow.html
Koncepcia lakťového bodu je podobná spôsobu, akým sa strata vyrovnáva na klesajúce výnosy na konci tréningu pre súbor údajov. Predstavuje bod, v ktorom sa neprejavia žiadne ďalšie rozdiely medzi skupinami, čo naznačuje moment prechodu k ďalším fázam v dátovom potrubí alebo nahlásenie zistení.
Populárne použitie
K-Means Clustering je zo zrejmých dôvodov primárnou technológiou v zákazníckej analýze, pretože ponúka jasnú a vysvetliteľnú metodológiu na prevod veľkého množstva obchodných záznamov do demografických prehľadov a „potenciálnych zákazníkov“.
Mimo tejto aplikácie sa používa aj K-Means Clustering predpoveď zosuvu pôdy, segmentácia medicínskeho obrazu, syntéza obrazu s GAN, klasifikácia dokumentova územné plánovanie, okrem mnohých iných potenciálnych a skutočných použití.
5: Náhodný les
Náhodný les je an súborové učenie metóda, ktorá spriemeruje výsledok z poľa rozhodovacie stromy vytvoriť celkovú predpoveď výsledku.

Zdroj: https://www.tutorialandexample.com/wp-content/uploads/2019/10/Decision-Trees-Root-Node.png
Ak ste to skúmali čo i len tak málo ako pozeranie Návrat do budúcnosti trilógie, samotný rozhodovací strom sa dá pomerne ľahko konceptualizovať: pred vami leží množstvo ciest a každá cesta sa rozvetvuje k novému výsledku, ktorý zase obsahuje ďalšie možné cesty.
In posilňovanie učenia, môžete ustúpiť z cesty a začať znova z predchádzajúceho postoja, zatiaľ čo rozhodovacie stromy sa zaviažu k svojej ceste.
Algoritmus Random Forest je teda v podstate stávkovanie na šírenie rozhodnutí. Algoritmus sa nazýva „náhodný“, pretože robí ad hoc výbery a pozorovania s cieľom pochopiť medián súčet výsledkov z poľa rozhodovacieho stromu.
Keďže berie do úvahy množstvo faktorov, prístup Random Forest môže byť ťažšie previesť na zmysluplné grafy ako rozhodovací strom, ale pravdepodobne bude výrazne produktívnejší.
Rozhodovacie stromy podliehajú nadmernému prispôsobeniu, pričom získané výsledky sú špecifické pre údaje a nie je pravdepodobné, že zovšeobecňujú. Svojvoľný výber údajových bodov Random Forest bojuje proti tejto tendencii a prechádza k zmysluplným a užitočným reprezentatívnym trendom v údajoch.

Regresia rozhodovacieho stromu. Zdroj: https://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html
Populárne použitie
Rovnako ako u mnohých algoritmov v tomto zozname, Random Forest zvyčajne funguje ako „skorý“ triedič a filter údajov a ako taký sa neustále objavuje v nových výskumných dokumentoch. Niektoré príklady použitia Random Forest zahŕňajú Syntéza obrazu magnetickou rezonanciou, Predikcia ceny bitcoínov, segmentácia sčítania, triedenie textu a odhaľovanie podvodov s kreditnými kartami.
Keďže Random Forest je nízkoúrovňový algoritmus v architektúrach strojového učenia, môže tiež prispieť k výkonu iných nízkoúrovňových metód, ako aj vizualizačných algoritmov, vrátane Indukčné klastrovanie, Transformácie funkcií, klasifikácia textových dokumentov pomocou riedkych funkciía zobrazenie potrubí.
6: Naivný Bayes
V spojení s odhadom hustoty (pozri 4, vyššie), a naivný Bayes klasifikátor je výkonný, ale relatívne ľahký algoritmus schopný odhadnúť pravdepodobnosti na základe vypočítaných vlastností údajov.

Charakteristické vzťahy v naivnom Bayesovom klasifikátore. Zdroj: https://www.sciencedirect.com/topics/computer-science/naive-bayes-model
Pojem „naivný“ sa vzťahuje na predpoklad v Bayesova veta že funkcie spolu nesúvisia, známe ako podmienená nezávislosť. Ak prijmete toto stanovisko, chôdza a rozprávanie ako kačica nestačia na to, aby sme zistili, že máme do činenia s kačicou, a žiadne „zrejmé“ predpoklady nie sú predčasne prijaté.
Táto úroveň akademickej a vyšetrovacej prísnosti by bola prehnaná tam, kde je k dispozícii „zdravý rozum“, ale je cenným štandardom pri prechádzaní mnohých nejednoznačností a potenciálne nesúvisiacich korelácií, ktoré môžu existovať v súbore údajov strojového učenia.
V pôvodnej Bayesovskej sieti sú funkcie predmetom bodovacie funkcie, vrátane minimálnej dĺžky popisu a Bayesovské bodovanie, ktorý môže uvaliť obmedzenia na údaje z hľadiska odhadovaných spojení nájdených medzi dátovými bodmi a smeru, ktorým tieto spojenia prúdia.
Naivný Bayesov klasifikátor naopak funguje tak, že predpokladá, že vlastnosti daného objektu sú nezávislé, následne použije Bayesovu vetu na výpočet pravdepodobnosti daného objektu na základe jeho vlastností.
Populárne použitie
Filtre Naive Bayes sú dobre zastúpené v predikcia chorôb a kategorizácia dokumentov, filtrovanie spamu, klasifikácia sentimentu, odporúčacie systémya detekcia podvodov, medzi inými aplikáciami.
7: K- Najbližší susedia (KNN)
Prvýkrát ho navrhla Škola leteckého lekárstva amerického letectva v 1951a musí sa prispôsobiť najmodernejšiemu výpočtovému hardvéru z polovice 20. storočia, K-Najbližší susedia (KNN) je štíhly algoritmus, ktorý stále vyniká v akademických dokumentoch a výskumných iniciatívach strojového učenia v súkromnom sektore.
KNN sa nazýva „lenivý študent“, pretože vyčerpávajúcim spôsobom skenuje súbor údajov s cieľom vyhodnotiť vzťahy medzi údajovými bodmi, namiesto toho, aby vyžadoval trénovanie plnohodnotného modelu strojového učenia.

Zoskupenie KNN. Zdroj: https://scikit-learn.org/stable/modules/neighbors.html
Hoci je KNN architektonicky štíhly, jeho systematický prístup kladie značné požiadavky na operácie čítania/zápisu a jeho použitie vo veľmi veľkých súboroch údajov môže byť problematické bez doplnkových technológií, ako je analýza hlavných komponentov (PCA), ktorá dokáže transformovať zložité a veľkoobjemové súbory údajov. do reprezentatívne zoskupenia že KNN dokáže prejsť s menšou námahou.
A Nedávna štúdia hodnotili efektívnosť a hospodárnosť niekoľkých algoritmov, ktorých úlohou bolo predpovedať, či zamestnanec odíde zo spoločnosti, pričom zistil, že sedemdesiatnik KNN zostal lepší ako modernejší uchádzači, pokiaľ ide o presnosť a predikčnú účinnosť.
Populárne použitie
Napriek všetkej svojej obľúbenej jednoduchosti koncepcie a prevedenia nie je KNN uviaznutý v 1950. rokoch minulého storočia – bol prispôsobený prístup viac zameraný na DNN v návrhu Pensylvánskej štátnej univerzity z roku 2018 a zostáva ústredným procesom v počiatočnom štádiu (alebo analytickým nástrojom následného spracovania) v mnohých oveľa zložitejších rámcoch strojového učenia.
V rôznych konfiguráciách bol KNN použitý alebo pre online overenie podpisu, klasifikácia obrázkov, dolovanie textu, predpoveď úrodya rozpoznávanie tváre, okrem iných aplikácií a začlenení.

Systém rozpoznávania tváre založený na KNN v tréningu. Source: https://pdfs.semanticscholar.org/6f3d/d4c5ffeb3ce74bf57342861686944490f513.pdf
8: Markovov rozhodovací proces (MDP)
Matematický rámec zavedený americkým matematikom Richardom Bellmanom v 1957, Markovov rozhodovací proces (MDP) je jedným z najzákladnejších blokov posilňovanie učenia architektúry. Koncepčný algoritmus sám o sebe bol adaptovaný do veľkého množstva iných algoritmov a často sa opakuje v súčasnej množine výskumu AI/ML.
MDP skúma dátové prostredie pomocou vyhodnotenia jeho aktuálneho stavu (tj „kde“ sa v dátach nachádza), aby sa rozhodol, ktorý uzol dát preskúmať ako ďalší.

Zdroj: https://www.sciencedirect.com/science/article/abs/pii/S0888613X18304420
Základný Markovov rozhodovací proces uprednostní krátkodobú výhodu pred žiadanejšími dlhodobými cieľmi. Z tohto dôvodu je zvyčajne začlenená do kontextu komplexnejšej architektúry politiky v posilňovacom vzdelávaní a často podlieha obmedzujúcim faktorom, ako napr. zľavnená odmenaa iné modifikujúce premenné prostredia, ktoré mu zabránia ponáhľať sa k okamžitému cieľu bez zohľadnenia širšieho požadovaného výsledku.
Populárne použitie
Nízkoúrovňový koncept MDP je rozšírený vo výskume aj aktívnom nasadení strojového učenia. Bolo to navrhnuté pre IoT bezpečnostné obranné systémy, zber rýba predpovedanie trhu.
Okrem jeho zrejmá použiteľnosť k šachu a iným striktne sekvenčným hrám je MDP tiež prirodzeným uchádzačom o procesný výcvik robotických systémov, ako môžeme vidieť na videu nižšie.

9: Pojem frekvencia-inverzná frekvencia dokumentu
Frekvencia termínu (TF) vydelí počet výskytov slova v dokumente celkovým počtom slov v tomto dokumente. Teda slovo tesnenie vyskytujúce sa raz v tisícslovnom článku má frekvenciu výrazov 0.001. Sama o sebe je TF ako indikátor dôležitosti termínu do značnej miery zbytočná z dôvodu, že nezmyselné články (ako napr. a, a, the,ena it) prevládajú.
Na získanie zmysluplnej hodnoty výrazu Inverse Document Frequency (IDF) vypočítava TF slova vo viacerých dokumentoch v súbore údajov, pričom veľmi vysokej frekvencii priraďuje nízke hodnotenie. stopwords, ako sú články. Výsledné vektory znakov sú normalizované na celé hodnoty, pričom každému slovu je priradená príslušná váha.

TF-IDF váži relevantnosť pojmov na základe frekvencie v mnohých dokumentoch, pričom zriedkavejší výskyt je indikátorom dôležitosti. Zdroj: https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
Aj keď tento prístup zabraňuje strate sémanticky dôležitých slov outliers, invertovanie frekvenčnej váhy automaticky neznamená, že nízkofrekvenčný člen je nie odľahlá hodnota, pretože niektoré veci sú zriedkavé a bezcenný. Nízkofrekvenčný výraz preto bude musieť preukázať svoju hodnotu v širšom architektonickom kontexte tým, že sa objaví (aj s nízkou frekvenciou na dokument) v množstve dokumentov v súbore údajov.
Napriek tomu vekTF-IDF je výkonná a populárna metóda na počiatočné filtrovanie prechodov v rámci spracovania prirodzeného jazyka.
Populárne použitie
Keďže TF-IDF zohrala za posledných dvadsať rokov aspoň určitú úlohu vo vývoji prevažne okultného algoritmu PageRank spoločnosti Google, stala sa veľmi široko prijímané ako manipulatívna taktika SEO, napriek 2019 Johna Muellera vzdať sa jeho dôležitosti pre výsledky vyhľadávania.
Kvôli tajnostiam okolo PageRank neexistuje žiadny jasný dôkaz, že TF-IDF je nie v súčasnosti účinná taktika, ako sa dostať do rebríčka Google. Zápalný diskusia medzi odborníkmi v oblasti IT v poslednom čase naznačuje, že či už je to správne alebo nie, že zneužívanie výrazov môže stále viesť k lepšiemu umiestneniu SEO (hoci dodatočným obvinenia zo zneužívania monopolov a nadmerná reklama stierajú hranice tejto teórie).
10: Stochastický zostup gradientu
Stochastický gradientový zostup (SGD) je čoraz populárnejšia metóda na optimalizáciu tréningu modelov strojového učenia.
Samotný Gradient Descent je metóda optimalizácie a následne kvantifikácie zlepšenia, ktoré model robí počas tréningu.
V tomto zmysle „gradient“ označuje sklon smerom nadol (skôr ako farebnú gradáciu, pozri obrázok nižšie), kde najvyšší bod „kopca“ vľavo predstavuje začiatok tréningového procesu. V tomto štádiu model ešte ani raz nevidel celé údaje a nenaučil sa dostatočne o vzťahoch medzi údajmi, aby produkoval efektívne transformácie.

Gradientný zostup na tréningu FaceSwap. Môžeme vidieť, že tréning v druhej polovici nejaký čas stagnoval, ale nakoniec sa spamätal z gradientu smerom k prijateľnej konvergencii.
Najnižší bod na pravej strane predstavuje konvergenciu (bod, v ktorom je model taký efektívny, ako sa kedy dostane pod uložené obmedzenia a nastavenia).
Gradient funguje ako záznam a prediktor disparity medzi chybovosťou (ako presne má model aktuálne zmapované dátové vzťahy) a váhami (nastavenia, ktoré ovplyvňujú spôsob, akým sa bude model učiť).
Tento záznam o pokroku možno použiť na informovanie a rozvrh miery učenia, automatický proces, ktorý hovorí, že architektúra sa má stať granulárnejšou a presnejšou, keď sa prvé vágne detaily premenia na jasné vzťahy a mapovania. Strata gradientu v skutočnosti poskytuje mapu just-in-time toho, kam by mal tréning pokračovať a ako by mal pokračovať.
Inováciou Stochastic Gradient Descent je, že aktualizuje parametre modelu na každom tréningovom príklade na iteráciu, čo vo všeobecnosti urýchľuje cestu ku konvergencii. V dôsledku nástupu hyperškálových súborov údajov v posledných rokoch sa popularita SGD v poslednej dobe stala jednou z možných metód na riešenie následných logistických problémov.
Na druhej strane má SGD negatívnych dôsledkov pre škálovanie prvkov a môže vyžadovať viac iterácií na dosiahnutie rovnakého výsledku, čo si vyžaduje dodatočné plánovanie a dodatočné parametre v porovnaní s bežným zostupom gradientu.
Populárne použitie
Vďaka svojej konfigurovateľnosti a napriek svojim nedostatkom sa SGD stal najobľúbenejším optimalizačným algoritmom na osadenie neurónových sietí. Jednou z konfigurácií SGD, ktorá sa stáva dominantnou v nových výskumných prácach AI/ML, je výber adaptívneho odhadu momentu (ADAM, predstavený v 2015) optimalizátor.
ADAM dynamicky prispôsobuje rýchlosť učenia pre každý parameter („adaptívna rýchlosť učenia“), ako aj začleňuje výsledky z predchádzajúcich aktualizácií do následnej konfigurácie („hybnosť“). Dodatočne sa dá nakonfigurovať na využitie neskorších inovácií, ako napr Nesterov Momentum.
Niektorí však tvrdia, že použitie hybnosti môže tiež urýchliť ADAM (a podobné algoritmy) na a suboptimálny záver. Rovnako ako vo väčšine prípadov v oblasti výskumu strojového učenia, na SGD sa stále pracuje.
Prvýkrát zverejnené 10. februára 2022. Upravené 10. februára 20.05 EET – formátovanie.















