
Inteligența artificială
Trei provocări în viitor pentru o difuzare stabilă

eliberaţi Difuzia stabilă a stabilității.ai difuzie latentă Modelul de sinteză a imaginii cu câteva săptămâni în urmă poate fi una dintre cele mai importante dezvăluiri tehnologice începând cu DeCSS în 1999este cu siguranță cel mai mare eveniment în domeniul imaginilor generate de inteligența artificială din 2017 încoace cod deepfakes a fost copiat pe GitHub și bifurcat în ceea ce avea să devină DeepFaceLab și schimb de fețe, precum și software-ul de streaming deepfake în timp real DeepFaceLive.
Dintr-o lovitură, frustrarea utilizatorului peste restricții de conținut în API-ul de sinteză a imaginilor din DALL-E 2 au fost date la o parte, deoarece s-a aflat că filtrul NSFW al Stable Diffusion putea fi dezactivat prin schimbarea unui singura linie de cod. Reddit-urile Stable Diffusion centrate pe porno au apărut aproape imediat și au fost la fel de repede tăiate, în timp ce tabăra de dezvoltatori și utilizatori s-a împărțit pe Discord în comunitățile oficiale și NSFW, iar Twitter a început să se umple cu creații fantastice Stable Diffusion.
În acest moment, fiecare zi pare să aducă niște inovații uimitoare de la dezvoltatorii care au adoptat sistemul, pluginurile și adjuvantele terță parte fiind scrise în grabă pentru Krita, Photoshop, Cinema4D, Blender, și multe alte platforme de aplicații.

În același timp, promptcraft – arta acum profesională a „șoptirii prin inteligență artificială”, care s-ar putea dovedi a fi cea mai scurtă opțiune de carieră de la „dosarul Filofax” încoace – devine deja comercializat, în timp ce monetizarea timpurie a Stable Diffusion are loc la Nivelul Patreon, cu certitudinea unor oferte mai sofisticate care vor veni, pentru cei care nu doresc să navigheze Bazat pe Conda instalări ale codului sursă sau filtre NSFW proscriptive ale implementărilor bazate pe web.
Ritmul de dezvoltare și libertatea de explorare a utilizatorilor avansează cu o viteză atât de amețitoare încât este dificil să vedem prea departe în viitor. În esență, nu știm exact cu ce avem de-a face încă sau care ar putea fi toate limitările sau posibilitățile.
Cu toate acestea, haideți să aruncăm o privire la trei dintre cele mai interesante și provocatoare obstacole cu care se confruntă și, sperăm, pe care comunitatea Stable Diffusion, aflată în plină dezvoltare și formare rapidă, trebuie să le depășească.
1: Optimizarea conductelor pe bază de plăci
Prezentat cu resurse hardware limitate și limite stricte privind rezoluția imaginilor de antrenament, se pare că dezvoltatorii vor găsi soluții pentru a îmbunătăți atât calitatea, cât și rezoluția rezultatelor Stable Diffusion. Multe dintre aceste proiecte sunt setate să implice exploatarea limitărilor sistemului, cum ar fi rezoluția sa nativă de doar 512×512 pixeli.
Ca întotdeauna în cazul inițiativelor de viziune computerizată și sinteză a imaginilor, Stable Diffusion a fost instruit pe imagini cu raport pătrat, în acest caz reeșantionate la 512×512, astfel încât imaginile sursă să poată fi regularizate și să se poată încadra în constrângerile GPU-urilor care a antrenat modelul.
Prin urmare, Stable Diffusion „gândește” (dacă gândește vreodată) în termeni de 512×512 și, cu siguranță, în termeni pătratici. Mulți utilizatori care explorează în prezent limitele sistemului raportează că Stable Diffusion produce cele mai fiabile și mai puțin defectuoase rezultate la acest raport de aspect destul de constrâns (vezi „abordarea extremităților” mai jos).
Deși diverse implementări oferă upscaling prin RealESRGAN (și poate repara fețele prost redate prin GFPGAN) câțiva utilizatori dezvoltă în prezent metode de împărțire a imaginilor în secțiuni de 512x512px și de a lega imaginile împreună pentru a forma lucrări compozite mai mari.

Această randare de 1024×576, o rezoluție de obicei imposibilă într-o singură randare Stable Diffusion, a fost creată prin copierea și lipirea fișierului Python attention.py din DoggettX furk de Stable Diffusion (o versiune care implementează upscaling bazat pe tile) într-o altă furcă. Sursa: https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Deși unele inițiative de acest fel folosesc cod original sau alte biblioteci, the portul txt2imghd de GOBIG (un mod în ProgRockDiffusion, care are nevoie de VRAM) este setat să ofere această funcționalitate ramului principal în curând. În timp ce txt2imghd este un port dedicat al GOBIG, alte eforturi ale dezvoltatorilor comunității implică diferite implementări ale GOBIG.

O imagine abstractă convenabilă în randarea originală de 512x512px (stânga și a doua din stânga); scalată prin ESGRAN, care este acum mai mult sau mai puțin nativă în toate distribuțiile Stable Diffusion; și căreia i s-a acordat „atenție specială” printr-o implementare a GOBIG, producând detalii care, cel puțin în limitele secțiunii imaginii, par mai bine scalate. Source: https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
Tipul de exemplu abstract prezentat mai sus are multe „mici regate” de detalii care se potrivesc acestei abordări solipsistice a upscaling-ului, dar care pot necesita soluții bazate pe cod mai dificile pentru a produce un upscaling nerepetitiv și coerent care nu uite ca și cum ar fi fost asamblat din mai multe părți. Nu în ultimul rând, în cazul fețelor umane, unde suntem neobișnuit de atenți la aberații sau artefacte „schimbătoare”. Prin urmare, fețele ar putea necesita în cele din urmă o soluție dedicată.
Stable Diffusion nu are în prezent un mecanism pentru focalizarea atenției asupra feței în timpul unei randări, în același mod în care oamenii prioritizează informațiile faciale. Deși unii dezvoltatori din comunitățile Discord iau în considerare metode de implementare a acestui tip de „atenție sporită”, în prezent este mult mai ușor să se îmbunătățească manual (și, în cele din urmă, automat) fața după ce a avut loc randarea inițială.
O față umană are o logică semantică internă și completă care nu se va regăsi într-o „dală” din colțul de jos (de exemplu) al unei clădiri și, prin urmare, este posibil în prezent să se „măriți” și să se redeze din nou o față „schiță” în rezultatul Stable Diffusion.

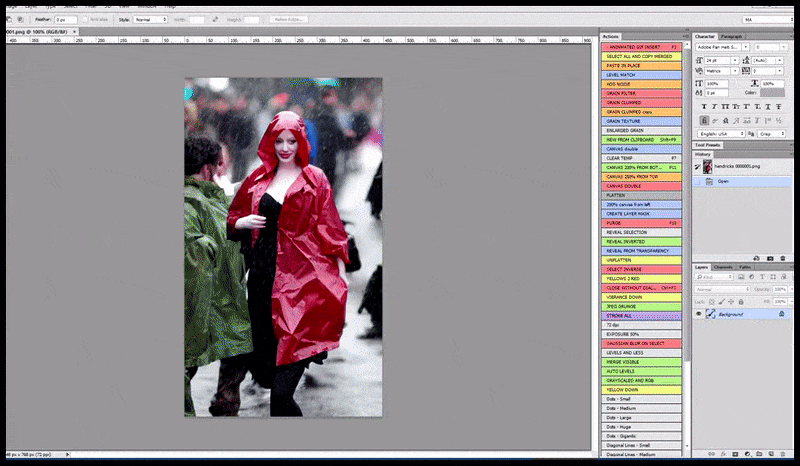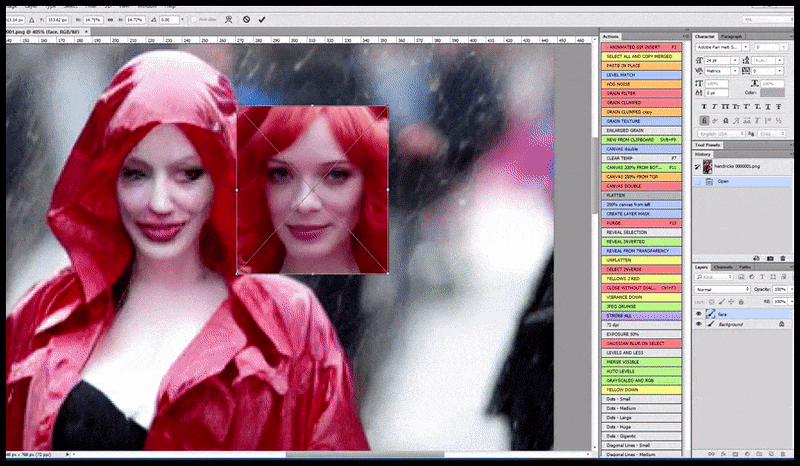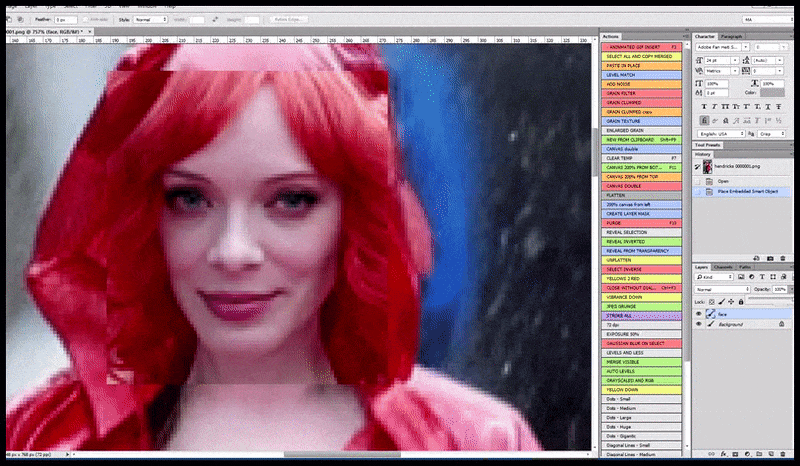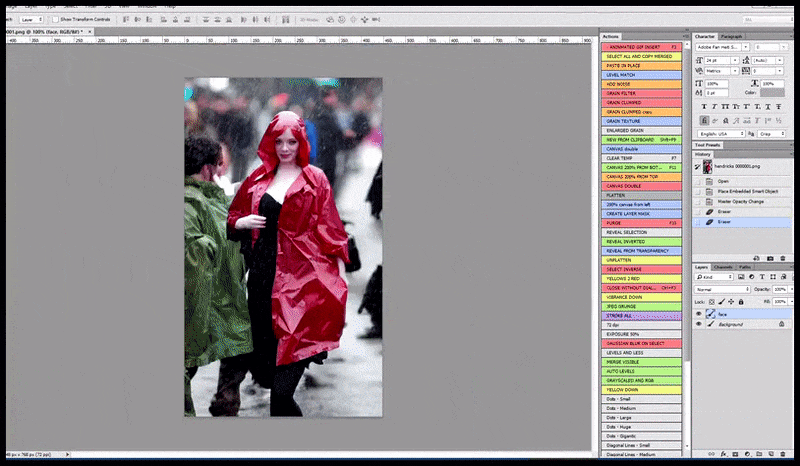
Stânga, efortul inițial al Stable Diffusion cu promptul „Fotografie color, de lungime întreagă, cu Christina Hendricks intrând într-un loc aglomerat, purtând un impermeabil; Canon 50, contact vizual, detalii detaliate, detalii faciale detaliate”. Dreapta, o față îmbunătățită obținută prin readucerea în atenția completă a Stable Diffusion a feței neclară și schițate din prima randare folosind Img2Img (vezi imaginile animate de mai jos).
În absența unei soluții dedicate de inversare textuală (a se vedea mai jos), aceasta va funcționa numai pentru imaginile celebrităților în care persoana în cauză este deja bine reprezentată în subseturile de date LAION care au antrenat Stable Diffusion. Prin urmare, va funcționa pe oameni precum Tom Cruise, Brad Pitt, Jennifer Lawrence și o gamă limitată de lumini media autentice care sunt prezente într-un număr mare de imagini în datele sursă.
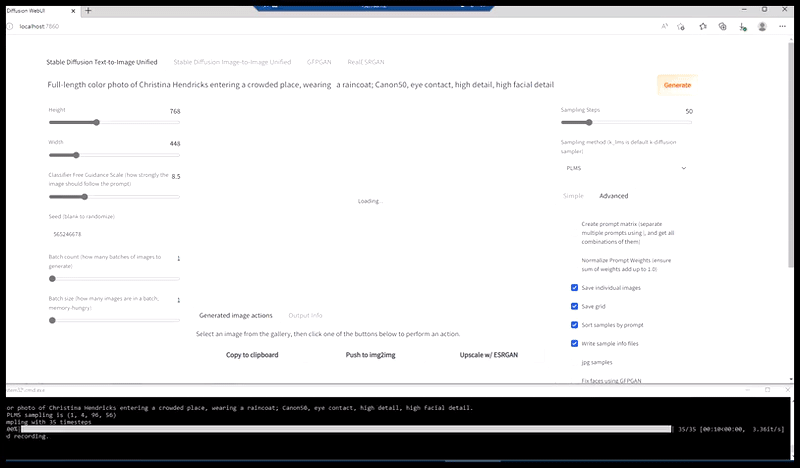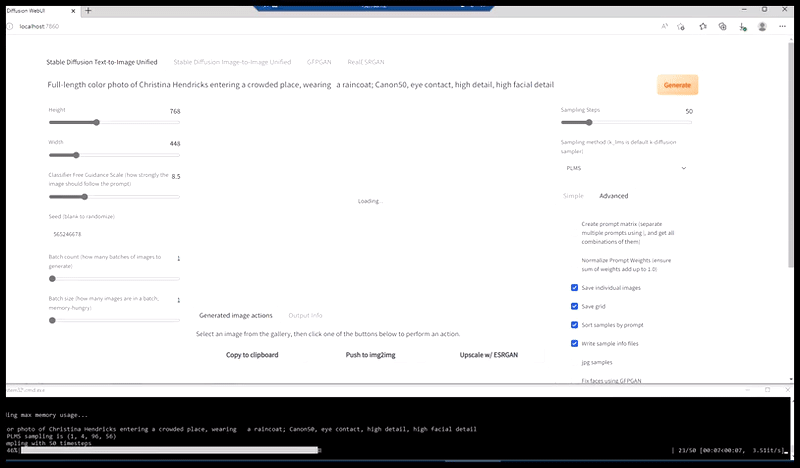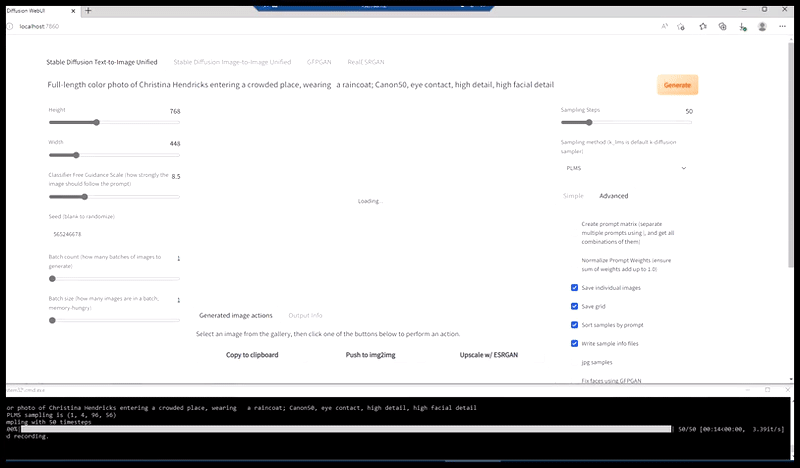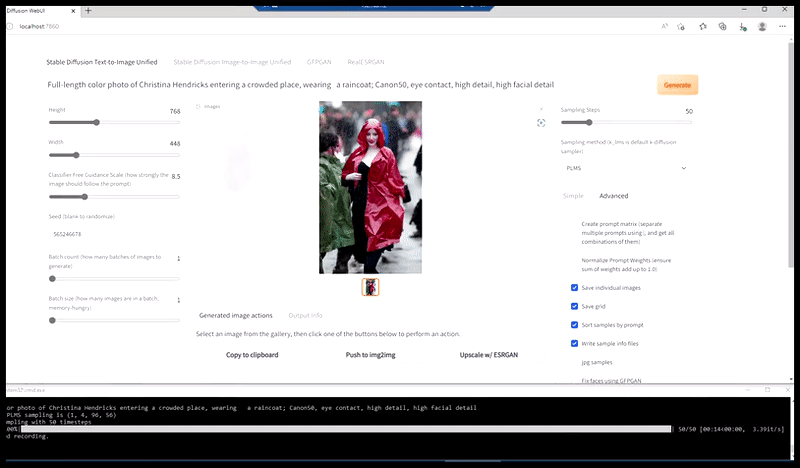
Generarea unei fotografii de presă plauzibile cu promptul „Fotografie color, de lungime întreagă, cu Christina Hendricks intrând într-un loc aglomerat, purtând un impermeabil; Canon 50, contact vizual, detalii detaliate, detalii faciale detaliate”.
Pentru celebritățile cu cariere lungi și de durată, Stable Diffusion va genera de obicei o imagine a persoanei la o vârstă recentă (adică mai în vârstă) și va fi necesar să adăugați adjuvanti prompti, cum ar fi 'tineri' or în anul [ANUL] pentru a produce imagini cu aspect mai tânăr.

Cu o carieră proeminentă, foarte fotografiată și consecventă de aproape 40 de ani, actrița Jennifer Connelly este una dintre puținele celebrități din LAION care îi permit lui Stable Diffusion să reprezinte o gamă de vârste. Sursa: Preambalaj Stable Diffusion, local, punct de control v1.4; sugestii legate de vârstă.
Acest lucru se datorează în mare parte proliferării fotografiei de presă digitale (mai degrabă decât costisitoare, pe bază de emulsie) de la mijlocul anilor 2000 și creșterii ulterioare a volumului de imagini din cauza vitezei crescute de bandă largă.
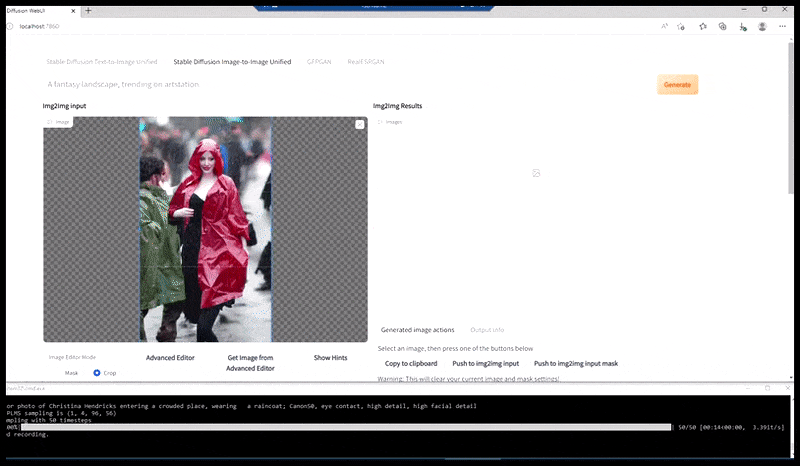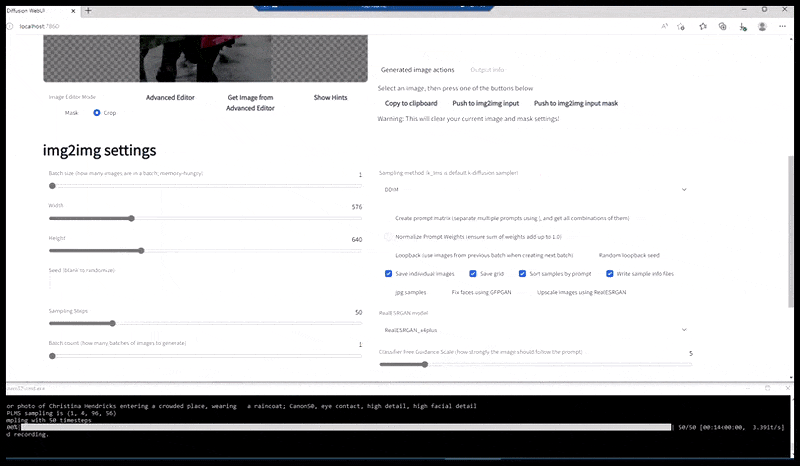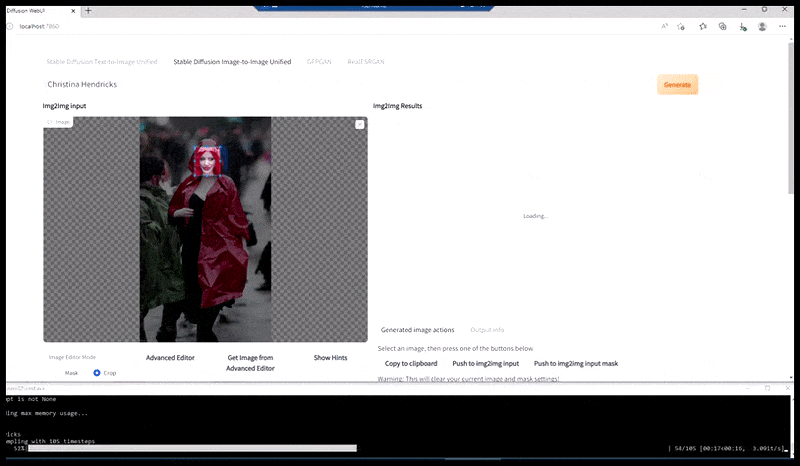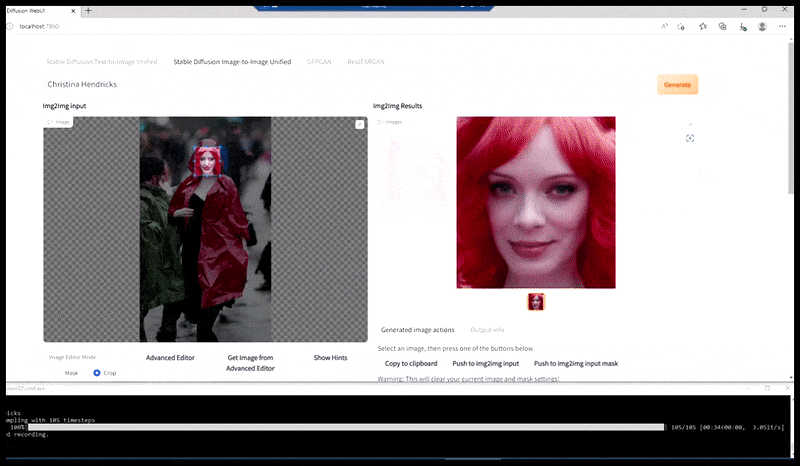
Imaginea randată este transmisă către Img2Img în Stable Diffusion, unde este selectată o „zonă de focalizare” și se realizează o nouă randare, la dimensiune maximă, doar pentru acea zonă, permițând Stable Diffusion să concentreze toate resursele disponibile pe recrearea feței.
Compunerea feței „cu atenție sporită” înapoi în randarea originală. În afară de fețe, acest proces va funcționa doar cu entități care au un aspect potențial cunoscut, coerent și integral, cum ar fi o porțiune a fotografiei originale care are un obiect distinct, cum ar fi un ceas sau o mașină. Mărirea la scară a unei secțiuni – de exemplu – a unui perete va duce la un perete reasamblat cu aspect foarte ciudat, deoarece randările plăcilor nu aveau un context mai larg pentru această „piesă de puzzle” în timpul randării.
Unele vedete din baza de date sunt „pre-înghețate” în timp, fie pentru că au murit devreme (cum ar fi Marilyn Monroe), fie pentru că au ajuns la o importanță trecătoare în mainstream, producând un volum mare de imagini într-o perioadă limitată de timp. Se poate spune că Polling Stable Diffusion oferă un fel de indice de popularitate „actual” pentru vedetele moderne și cele mai în vârstă. Pentru unele vedete mai în vârstă și actuale, nu există suficiente imagini în datele sursă pentru a obține o asemănare foarte bună, în timp ce popularitatea persistentă a anumitor vedete de mult moarte sau altfel stingute asigură că asemănarea lor rezonabilă poate fi obținută din sistem.

Randările Stable Diffusion dezvăluie rapid care fețe celebre sunt bine reprezentate în datele de antrenament. În ciuda popularității ei enorme ca adolescentă mai în vârstă la momentul scrierii, Millie Bobby Brown era mai tânără și mai puțin cunoscută atunci când seturile de date sursă LAION au fost îndepărtate de pe web, ceea ce face problematica asemănării de înaltă calitate cu Stable Diffusion în acest moment.
Acolo unde datele sunt disponibile, soluțiile de rezoluție ridicată bazate pe tile din Stable Diffusion ar putea merge mai departe decât găzduirea feței: ar putea permite chipuri și mai precise și mai detaliate, defalcând trăsăturile faciale și schimbând întreaga forță a GPU-ului local. resurse pe caracteristicile esențiale în mod individual, înainte de reasamblare - un proces care în prezent este, din nou, manual.

Acest lucru nu se limitează la fețe, ci este limitat la părți ale obiectelor care sunt cel puțin la fel de previzibil plasate în contextul mai larg al obiectului gazdă și care se conformează înglobărilor de nivel înalt pe care ne-am putea aștepta în mod rezonabil să le găsești într-o hiperscală. set de date.
Limita reală este cantitatea de date de referință disponibile în setul de date, deoarece, în cele din urmă, detaliile iterate profund vor deveni complet „halucinate” (adică fictive) și mai puțin autentice.
Astfel de măriri granulare de nivel înalt funcționează în cazul lui Jennifer Connelly, deoarece este bine reprezentată într-o gamă de vârste în LAION-estetica (subsetul primar al LAION 5B (pe care îl folosește Stable Diffusion) și, în general, în LAION; în multe alte cazuri, acuratețea ar avea de suferit din cauza lipsei de date, necesitând fie o ajustare fină (instruire suplimentară, vezi „Personalizare” mai jos), fie inversiune textuală (vezi mai jos).
Tiles-urile sunt o modalitate puternică și relativ ieftină de a permite Stable Diffusion să producă rezultate de înaltă rezoluție, dar upscalingul algoritmic în plăci de acest tip, dacă îi lipsește un fel de mecanism de atenție mai larg, de nivel superior, poate fi sub nivelul sperat. pentru standarde într-o gamă largă de tipuri de conținut.
2: Abordarea problemelor cu membrele umane
Difuzia Stabilă nu se ridică la înălțimea numelui său atunci când descrie complexitatea extremităților umane. Mâinile se pot multiplica aleatoriu, degetele se pot uni, al treilea picior poate apărea nedorit, iar membrele existente dispar fără urmă. În apărarea sa, Difuzia Stabilă are aceeași problemă cu celelalte sisteme și, cu siguranță, cu DALL-E 2.

Rezultate needitate de la DALL-E 2 și Stable Diffusion (1.4) la sfârșitul lunii august 2022, ambele prezentând probleme cu membrele. Subiectul este „O femeie îmbrățișează un bărbat”.
Fanii Stable Diffusion care speră că următorul punct de control 1.5 (o versiune mai intens antrenată a modelului, cu parametri îmbunătățiți) ar rezolva confuzia membrelor sunt probabil dezamăgiți. Noul model, care va fi lansat în aproximativ două săptămâni, este în prezent în premieră pe portalul comercial stability.ai studio de vis, care utilizează implicit 1.5 și unde utilizatorii pot compara noua ieșire cu randările din sistemele lor locale sau din alte sisteme 1.4:

Sursa: Local 1.4 prepack și https://beta.dreamstudio.ai/

Sursa: Local 1.4 prepack și https://beta.dreamstudio.ai/

Sursa: Local 1.4 prepack și https://beta.dreamstudio.ai/
Așa cum este adesea cazul, calitatea datelor ar putea fi cauza principală care contribuie.
Bazele de date open source care alimentează sistemele de sinteză a imaginilor, cum ar fi Stable Diffusion și DALL-E 2, sunt capabile să ofere multe etichete atât pentru oameni individuali, cât și pentru acțiunile interumane. Aceste etichete sunt instruite în mod simbiotic cu imaginile asociate sau cu segmentele de imagini.

Utilizatorii Stable Diffusion pot explora conceptele antrenate în model prin interogarea setului de date LAION-aesthetics, un subset al setului de date mai mare LAION 5B, care alimentează sistemul. Imaginile nu sunt ordonate după etichetele lor alfabetice, ci după „scorul lor estetic”. Sursa: https://rom1504.github.io/clip-retrieval/
A ierarhie bună de etichete și clase individuale care contribuie la descrierea unui braț uman ar fi ceva de genul corp>braț>mână>degete>[subcifre + degetul mare]> [segmente de cifre]>Unghii.

Segmentare semantică granulară a părților unei mâini. Chiar și această deconstrucție neobișnuit de detaliată lasă fiecare „deget” ca o singură entitate, fără a ține cont de cele trei secțiuni ale unui deget și de cele două secțiuni ale unui deget mare. Sursa: https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
În realitate, este puțin probabil ca imaginile sursă să fie adnotate atât de consistent în întregul set de date, iar algoritmii de etichetare nesupravegheați se vor opri probabil la superior nivelul – de exemplu – de „mâină” și să lase pixelii interiori (care conțin tehnic informații despre „deget”) ca o masă neetichetată de pixeli din care vor fi derivate arbitrar caracteristici și care se pot manifesta în randările ulterioare ca un element discordant.

Cum ar trebui să fie (dreapta sus, dacă nu în sus) și cum tinde să fie (dreapta jos), datorită resurselor limitate pentru etichetare sau exploatării arhitecturale a unor astfel de etichete, dacă acestea există în setul de date.
Astfel, dacă un model de difuzie latentă ajunge până la redarea unui braț, aproape sigur va încerca măcar să redea o mână la capătul acelui braț, deoarece braț> mână este ierarhia minimă necesară, destul de sus în ceea ce știe arhitectura despre „anatomia umană”.
După aceea, „degetele” ar putea fi cea mai mică grupare, chiar dacă există încă 14 subpărți ale degetelor/degetului mare de luat în considerare atunci când se descriu mâinile umane.
Dacă această teorie este valabilă, nu există un remediu real, din cauza lipsei la nivelul sectorului de buget pentru adnotarea manuală și a lipsei unor algoritmi suficient de eficienți care ar putea automatiza etichetarea, producând în același timp rate scăzute de eroare. De fapt, modelul se poate baza în prezent pe consistența anatomică umană pentru a pune în discuție deficiențele setului de date pe care a fost instruit.
Un posibil motiv pentru care nu poate bazează-te pe asta, recent propus la Stable Diffusion Discord, este că modelul ar putea deveni confuz cu privire la numărul corect de degete pe care ar trebui să le aibă o mână umană (realistă), deoarece baza de date derivată din LAION care o alimentează conține personaje de desene animate care pot avea mai puține degete (ceea ce este în sine) o scurtătură care economisește forța de muncă).

Doi dintre potențialii vinovați ai sindromului „degetului lipsă” în Stable Diffusion și modele similare. Mai jos, exemple de mâini din desene animate din setul de date LAION-aesthetics care alimentează Stable Diffusion. Sursa: https://www.youtube.com/watch?v=0QZFQ3gbd6I
Dacă acest lucru este adevărat, atunci singura soluție evidentă este recalificarea modelului, excluzând conținutul nerealist bazat pe oameni, asigurându-se că cazurile autentice de omisiune (adică persoanele amputate) sunt etichetate corespunzător ca excepții. Numai din punct de vedere al procesării datelor, aceasta ar fi o provocare, în special pentru eforturile comunității lipsite de resurse.
A doua abordare ar fi aplicarea de filtre care exclud un astfel de conținut (de exemplu, „mâna cu trei/cinci degete”) de la manifestarea în momentul randării, în același mod în care OpenAI a făcut-o, într-o oarecare măsură, filtrat GPT-3 și DALL-E2, astfel încât producția lor să poată fi reglată fără a fi nevoie de recalificarea modelelor sursă.

Pentru Stable Diffusion, distincția semantică dintre degete și chiar membre poate deveni îngrozitor de neclară, aducând în minte filmele horror „body horror” din anii 1980, cu actori precum David Cronenberg. Sursa: https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Cu toate acestea, din nou, acest lucru ar necesita etichete care ar putea să nu existe în toate imaginile afectate, lăsându-ne cu aceeași provocare logistică și bugetară.
S-ar putea argumenta că există două căi rămase de urmat: furnizarea mai multor date pentru a rezolva problema și aplicarea unor sisteme interpretative terțe care pot interveni atunci când erorile fizice de tipul descris aici sunt prezentate utilizatorului final (cel puțin, aceasta din urmă ar oferi OpenAI o metodă de a oferi rambursări pentru randările „body horror”, dacă firma ar fi motivată să facă acest lucru).
3: Personalizare
Una dintre cele mai interesante posibilități pentru viitorul Stable Diffusion este perspectiva ca utilizatorii sau organizațiile să dezvolte sisteme revizuite; modificări care permit ca conținutul din afara sferei LAION preantrenate să fie integrat în sistem – în mod ideal, fără cheltuiala neguvernabilă de a antrena din nou întregul model sau riscul pe care îl presupune antrenamentul într-un volum mare de imagini noi pentru un existent, matur și capabil. model.
Prin analogie: dacă doi elevi mai puțin talentați se alătură unei clase avansate de treizeci de elevi, fie se vor asimila și vor recupera decalajul, fie vor eșua ca elevi aberanți; în ambele cazuri, performanța medie a clasei probabil nu va fi afectată. Cu toate acestea, dacă se alătură 15 elevi mai puțin talentați, curba notelor pentru întreaga clasă este probabil să aibă de suferit.
De asemenea, rețeaua sinergică și destul de delicată de relații care sunt construite pe baza pregătirii susținute și costisitoare a modelului poate fi compromisă, în unele cazuri efectiv distrusă, de date noi excesive, scăzând calitatea ieșirii pentru model în general.
Argumentul pentru a face acest lucru se bazează în principal pe faptul că interesul tău constă în deturnarea completă a înțelegerii conceptuale a relațiilor și lucrurilor de către model și în însușirea acesteia pentru producerea exclusivă de conținut similar cu materialul suplimentar pe care l-ai adăugat.
Astfel, antrenând 500,000 Simpsons cadre într-un punct de control Stable Diffusion existent este probabil, în cele din urmă, să vă aducă un lucru mai bun Simpsons simulator decât ar fi putut oferi versiunea originală, presupunând că suficiente relații semantice largi supraviețuiesc procesului (adică Homer Simpson mănâncă un hotdog, care ar putea necesita material despre hot-dogi care nu se afla în materialul suplimentar, dar exista deja în punctul de control), și presupunând că nu doriți să treceți brusc de la Simpsons conținut pentru a crea peisaj fabulos de Greg Rutkowski – deoarece atenția modelului tău post-antrenat a fost deviată masiv și nu va mai fi la fel de bun la acest gen de lucruri ca înainte.
Un exemplu notabil în acest sens este waifu-difuzie, care a avut succes 56,000 de imagini anime post-antrenate într-un punct de control Stable Diffusion completat și antrenat. Este însă o perspectivă dificilă pentru un amator, deoarece modelul necesită un minim impresionant de 30 GB de VRAM, mult peste ceea ce este probabil disponibil la nivelul consumatorului în viitoarele versiuni ale seriei 40XX de la NVIDIA.

Antrenarea conținutului personalizat în Stable Diffusion prin waifu-diffusion: modelul a avut nevoie de două săptămâni de post-antrenament pentru a obține acest nivel de ilustrare. Cele șase imagini din stânga arată progresul modelului, pe măsură ce a continuat antrenamentul, în realizarea rezultatelor coerente cu subiectul pe baza noilor date de antrenament. Sursa: https://gigazine.net/gsc_news/en/20220121-how-waifu-labs-create/
S-ar putea depune mult efort pentru astfel de „furcături” ale punctelor de control Stable Diffusion, doar pentru a fi blocate de datorii tehnice. Dezvoltatorii de la Discord-ul oficial au indicat deja că versiunile ulterioare ale punctelor de control nu vor fi neapărat compatibile cu versiunile anterioare, chiar și cu o logică promptă care ar fi putut funcționa cu o versiune anterioară, deoarece interesul lor principal este obținerea celui mai bun model posibil, mai degrabă decât susținerea aplicațiilor și proceselor vechi.
Prin urmare, o companie sau o persoană care decide să ramifice un punct de control către un produs comercial nu are practic nicio cale de întoarcere; versiunea lor a modelului este, în acel moment, o „bifurcație rigidă” și nu va putea obține beneficii din versiunile ulterioare ale stability.ai – ceea ce reprezintă un angajament semnificativ.
Actuala și mai mare speranță pentru personalizarea Stable Diffusion este Inversie textuală, unde utilizatorul se antrenează într-o mână mică de CLIP-imagini aliniate.

O colaborare între Universitatea din Tel Aviv și NVIDIA, inversarea textuală permite formarea de entități noi și discrete, fără a distruge capacitățile modelului sursă. Sursa: https://textual-inversion.github.io/
Principala limitare aparentă a inversării textuale este că se recomandă un număr foarte mic de imagini – până la cinci. Acest lucru produce efectiv o entitate limitată care poate fi mai utilă pentru sarcinile de transfer de stil, mai degrabă decât pentru inserarea de obiecte fotorealiste.
Cu toate acestea, experimente au loc în prezent în cadrul diferitelor Discords Stable Diffusion care utilizează un număr mult mai mare de imagini de antrenament și rămâne de văzut cât de productivă s-ar putea dovedi metoda. Din nou, tehnica necesită multă VRAM, timp și răbdare.
Din cauza acestor factori limitativi, s-ar putea să fie nevoie să așteptăm o vreme pentru a vedea unele dintre cele mai sofisticate experimente de inversiune textuală realizate de entuziaștii Stable Diffusion – și dacă această abordare vă poate „pune în imagine” într-un mod care arată mai bine decât o copiere și lipire din Photoshop, păstrând în același timp funcționalitatea uimitoare a punctelor de control oficiale.
Publicat prima dată pe 6 septembrie 2022.











