
Etică
Practicile actuale de inteligență artificială ar putea permite o nouă generație de troli de drepturi de autor

O nouă colaborare de cercetare între Huawei și mediul academic sugerează că o mare parte din cele mai importante cercetări actuale în inteligența artificială și învățarea automată ar putea fi expuse la litigii de îndată ce acestea devin proeminente din punct de vedere comercial, deoarece seturile de date care fac posibile descoperiri sunt distribuite cu persoane invalide. licențe care nu respectă termenii inițiali ai domeniilor publice din care au fost obținute datele.
De fapt, acest lucru are două rezultate posibile aproape inevitabile: că algoritmii AI foarte de succes, comercializați, despre care se știe că au folosit astfel de seturi de date, vor deveni ținte viitoare ale trollilor de brevete oportuniști ale căror drepturi de autor nu au fost respectate atunci când datele lor au fost eliminate; și că organizațiile și indivizii vor putea folosi aceleași vulnerabilități legale pentru a protesta împotriva implementării sau difuzării tehnologiilor de învățare automată pe care le consideră inacceptabile.
hârtie se intitulează Pot folosi acest set de date disponibil public pentru a construi software comercial AI? Cel mai probabil nuși este o colaborare între Huawei Canada și Huawei China, împreună cu Universitatea York din Marea Britanie și Universitatea Victoria din Canada.
Cinci din șase (populare) seturi de date open source nu sunt utilizabile din punct de vedere legal
Pentru cercetare, autorii au cerut departamentelor de la Huawei să selecteze cele mai dorite seturi de date open source pe care ar dori să le exploateze în proiecte comerciale și au selectat cele mai solicitate șase seturi de date din răspunsuri: CIFAR-10 (un subset al 80 de milioane de imagini minuscule set de date, din moment ce retrase pentru „termeni derogatori” și „imagini ofensatoare”, deși derivatele sale proliferează); IMAGEnet; Peisaje urbane (care conține exclusiv material original); FFHQ; VGGFace2, și MSCOCO.
Pentru a analiza dacă seturile de date selectate erau adecvate pentru utilizare legală în proiecte comerciale, autorii au dezvoltat o nouă conductă pentru a urmări lanțul de licențe în măsura în care era fezabil pentru fiecare set, deși adesea au trebuit să recurgă la capturi de arhive web pentru a putea localizați licențele de pe domeniile expirate și, în anumite cazuri, trebuia să „ghicească” starea licenței din cele mai apropiate informații disponibile.
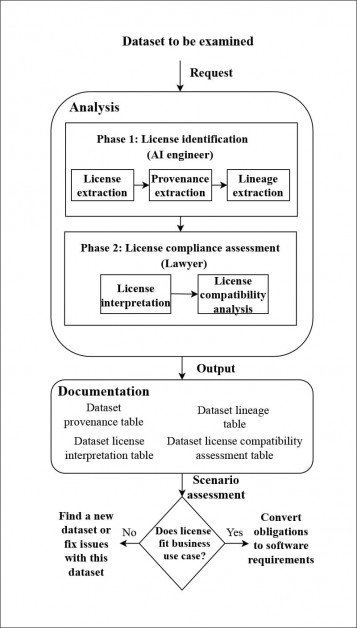
Arhitectură pentru sistemul de urmărire a provenienței dezvoltat de autori. Sursă: https://arxiv.org/pdf/2111.02374.pdf
Autorii au descoperit că licențele pentru cinci din cele șase seturi de date „conțin riscuri asociate cu cel puțin un context de utilizare comercială”:
„[Noi] observăm că, cu excepția MS COCO, niciuna dintre licențele studiate nu oferă practicienilor dreptul de a comercializa un model AI instruit pe date sau chiar pe rezultatul modelului AI instruit. Un astfel de rezultat îi împiedică, de asemenea, efectiv pe practicieni să folosească modele pre-instruite, instruite pe aceste seturi de date. Seturile de date disponibile public și modelele AI care sunt pre-instruite pe acestea sunt fiind utilizat pe scară largă comercial.' *
Autorii mai notează că trei dintre cele șase seturi de date studiate ar putea duce în plus la încălcarea licenței pentru produsele comerciale dacă setul de date este modificat, deoarece numai MS-COCO permite acest lucru. Cu toate acestea, creșterea datelor și sub-seturile și super-seturile de seturi de date influente sunt o practică comună.
În cazul CIFAR-10, compilatorii originali nu au creat deloc nicio formă convențională de licență, cerând doar ca proiectele care utilizează setul de date să includă o citare la lucrarea originală care a însoțit lansarea setului de date, prezentând o altă obstacol în calea stabilirii. statutul juridic al datelor.
În plus, numai setul de date CityScapes conține material care este generat exclusiv de inițiatorii setului de date, mai degrabă decât să fie „curat” (răzuit) din surse de rețea, CIFAR-10 și ImageNet utilizând mai multe surse, fiecare dintre acestea ar trebui investigată. și urmărit înapoi pentru a stabili orice fel de mecanism de drept de autor (sau chiar o declinare semnificativă a răspunderii).
No Way Out
Există trei factori pe care companiile comerciale de inteligență artificială par să se bazeze pentru a le proteja de litigiile legate de produse care au folosit conținut protejat prin drepturi de autor din seturi de date în mod liber și fără permisiune, pentru a antrena algoritmi de inteligență artificială. Niciuna dintre acestea nu oferă multă (sau orice) protecție fiabilă pe termen lung:
1: Legile Naționale Laissez Faire
Deși guvernele din întreaga lume sunt obligate să relaxeze legile referitoare la eliminarea datelor în efortul de a nu cădea înapoi în cursa către IA performantă (care se bazează pe volume mari de date din lumea reală pentru care respectarea obișnuită a drepturilor de autor și acordarea de licențe ar fi nerealistă), doar Statele Unite oferă imunitate cu drepturi depline în acest sens, în temeiul Doctrina utilizării corecte – o politică care a fost ratificată în 2015 cu concluzie de Authors Guild v. Google, Inc., care a afirmat că gigantul căutărilor ar putea ingera în mod liber material protejat prin drepturi de autor pentru proiectul său Google Books, fără a fi acuzat de încălcare.
Dacă politica privind doctrina utilizării echitabile se schimbă vreodată (adică ca răspuns la un alt caz emblematic care implică organizații sau corporații suficient de puternice), ar putea fi considerată un a priori stat în ceea ce privește exploatarea bazelor de date actuale care încalcă drepturile de autor, protejarea utilizării anterioare; dar nu în curs de desfășurare utilizarea și dezvoltarea sistemelor care au fost activate prin material protejat de drepturi de autor fără acord.
Acest lucru pune protecția actuală a Doctrinei utilizării loiale pe o bază foarte provizorie și ar putea, în acest scenariu, să solicite ca algoritmi de învățare automată stabiliți și comercializați să înceteze funcționarea în cazurile în care originile lor au fost activate de material protejat de drepturi de autor – chiar și în cazurile în care ale modelului greutăți acum se ocupă exclusiv de conținut permis, dar au fost instruiți cu privire la conținutul copiat ilegal (și s-au făcut folositori prin) conținut copiat ilegal.
În afara Statelor Unite, după cum remarcă autorii în noua lucrare, politicile sunt în general mai puțin îngăduitoare. Regatul Unit și Canada despăgubesc numai utilizarea datelor protejate prin drepturi de autor în scopuri necomerciale, în timp ce Legea UE privind extragerea de text și date (care nu a fost anulată în întregime de către propuneri recente pentru o reglementare mai formală a AI) exclude și exploatarea comercială pentru sistemele AI care nu respectă cerințele privind drepturile de autor ale datelor originale.
Aceste din urmă aranjamente înseamnă că o organizație poate realiza lucruri grozave cu datele altor oameni, până la – dar fără a include – punctul de a face bani din acestea. În acea etapă, produsul ar fi fie expus legal, fie ar trebui încheiate aranjamente cu milioane de deținători de drepturi de autor, mulți dintre care acum nu pot fi urmăriți din cauza naturii în schimbare a internetului – o perspectivă imposibilă și inaccesabilă.
2: Caveat Emptor
În cazurile în care organizațiile care încalcă drepturile de autor speră să amâne vina, noul articol observă, de asemenea, că multe licențe pentru cele mai populare seturi de date open source se auto-despăgubesc împotriva oricăror pretenții de abuz de drepturi de autor:
„De exemplu, licența ImageNet cere în mod explicit practicienilor să despăgubească echipa ImageNet împotriva oricăror pretenții care decurg din utilizarea setului de date. Seturile de date FFHQ, VGGFace2 și MS COCO necesită ca setul de date, dacă este distribuit sau modificat, să fie prezentat sub aceeași licență.'
În mod efectiv, acest lucru îi obligă pe cei care folosesc seturile de date FOSS să absoarbă vinovăția pentru utilizarea materialului protejat prin drepturi de autor, în fața eventualelor litigii (deși nu îi protejează neapărat pe compilatorii inițiali într-un caz în care este inclus climatul actual de „port sigur”).
3: Despăgubire prin obscuritate
Natura colaborativă a comunității de învățare automată face destul de dificilă utilizarea ocultismului corporativ pentru a ascunde prezența algoritmilor care au beneficiat de seturi de date care încalcă drepturile de autor. Proiectele comerciale pe termen lung încep adesea în medii deschise FOSS, în care utilizarea seturilor de date este o chestiune de înregistrare, la GitHub și alte forumuri accesibile publicului, sau unde originile proiectului au fost publicate în lucrări pretipărite sau revizuite de colegi.
Chiar și acolo unde nu este cazul, inversarea modelului is din ce în ce mai capabil de dezvăluire a caracteristicilor tipice ale seturilor de date (sau chiar scoaterea în mod explicit unele dintre materialele sursă), fie oferind dovezi în sine, fie suficiente suspiciuni de încălcare pentru a permite accesul ordonat de instanță la istoricul dezvoltării algoritmului și detaliile seturilor de date utilizate în acea dezvoltare.
Concluzie
Lucrarea descrie o utilizare haotică și ad-hoc a materialelor protejate prin drepturi de autor obținute fără permisiune și a unei serii de lanțuri de licențe care, urmate în mod logic încă de la sursa inițială a datelor, ar necesita negocieri cu mii de deținători de drepturi de autor ale căror lucrări au fost prezentate. sub egida site-urilor cu o mare varietate de termeni de licență, multe excluzând lucrările comerciale derivate.
Autorii au concluzionat:
„Seturile de date disponibile public sunt utilizate pe scară largă pentru a construi software comercial AI. Se poate face acest lucru dacă [și] numai dacă licența asociată cu setul de date disponibil public oferă dreptul de a face acest lucru. Cu toate acestea, nu este ușor să verificați drepturile și obligațiile prevăzute în licența asociată cu seturile de date disponibile publicului. Pentru că, uneori, licența este fie neclară, fie potențial invalidă.
O altă lucrare nouă, intitulată Construirea de seturi de date juridice, publicat pe 2 noiembrie de la Centrul de Drept Computațional de la Universitatea de Management din Singapore, subliniază, de asemenea, nevoia ca oamenii de știință de date să recunoască faptul că era „vestul sălbatic” a culegerii de date ad-hoc se apropie de sfârșit și reflectă recomandările Huawei. document să adopte obiceiuri și metodologii mai stricte pentru a se asigura că utilizarea setului de date nu expune un proiect la ramificații legale, pe măsură ce cultura se schimbă în timp și pe măsură ce activitatea academică globală actuală din sectorul învățării automate caută o rentabilitate comercială a investiției pe ani. . Autorul observă*:
„[Corpusul] de legislație care afectează seturile de date ML este pe cale să crească, pe fondul preocupărilor pe care legile actuale oferă insuficient garanții. Proiectul AIA [Legea UE privind inteligența artificială], dacă și atunci când este adoptat, ar modifica în mod semnificativ peisajul AI și al guvernării datelor; alte jurisdicții pot urma exemplul cu propriile acte. '
* Conversia mea a citărilor inline în hyperlinkuri















