
Inteligenta Artificiala
LipSync3D de la Google oferă o sincronizare îmbunătățită a mișcării gurii „deepfaked”

A colaborare între cercetătorii Google AI și Institutul Indian de Tehnologie Kharagpur oferă un nou cadru pentru a sintetiza capete vorbitoare din conținutul audio. Proiectul își propune să producă modalități optimizate și dotate cu resurse rezonabile de a crea conținut video cu „cap vorbitor” din audio, în scopul sincronizării mișcărilor buzelor cu audio dublat sau tradus automat și pentru utilizare în avatare, în aplicații interactive și în alte medii în timp real.

Sursa: https://www.youtube.com/watch?v=L1StbX9OznY
Modelele de învățare automată instruite în acest proces – numite LipSync3D – necesită doar un singur videoclip cu identitatea feței țintă ca date de intrare. Conducta de pregătire a datelor separă extragerea geometriei faciale de evaluarea luminii și a altor fațete ale unui videoclip de intrare, permițând un antrenament mai economic și mai concentrat.
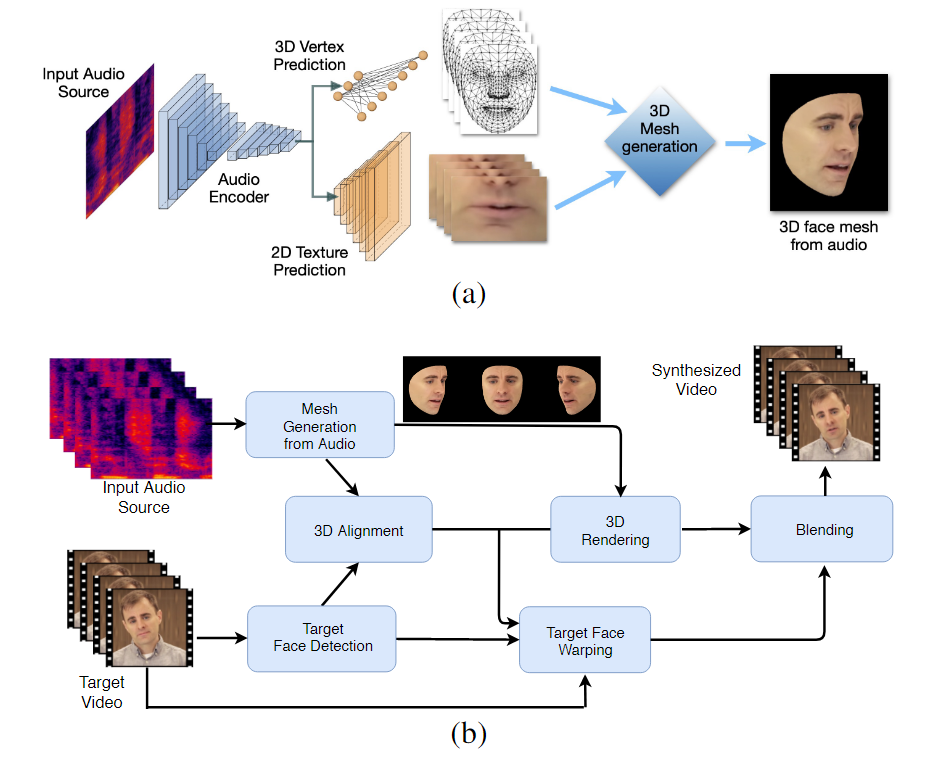
Fluxul de lucru în două etape al LipSync3D. Mai sus, generarea unei fețe 3D texturate dinamic din sunetul „țintă”; mai jos, inserarea rețelei generate într-un videoclip țintă.
De fapt, cea mai notabilă contribuție a lui LipSync3D la efortul de cercetare în acest domeniu poate fi algoritmul său de normalizare a luminii, care decuplă antrenamentul și iluminarea prin inferență.

Decuplarea datelor de iluminare de geometria generală ajută LipSync3D să producă o mișcare mai realistă a buzelor în condiții dificile. Alte abordări din ultimii ani s-au limitat la condiții de iluminare „fixe” care nu vor dezvălui capacitatea lor mai limitată în acest sens.
În timpul preprocesării cadrelor de date de intrare, sistemul trebuie să identifice și să elimine punctele speculare, deoarece acestea sunt specifice condițiilor de iluminare în care a fost realizat videoclipul și, în caz contrar, vor interfera cu procesul de reiluminare.

LipSync3D, așa cum sugerează și numele, nu efectuează o simplă analiză a pixelilor pe fețele pe care le evaluează, ci utilizează în mod activ repere faciale identificate pentru a genera rețele mobile în stil CGI, împreună cu texturile „desfăcute” care sunt înfășurate în jurul lor într-un CGI tradițional. conductă.

Normalizarea poziției în LipSync3D. În stânga sunt cadrele de intrare și caracteristicile detectate; la mijloc, vârfurile normalizate ale evaluării rețelei generate; iar în dreapta, atlasul texturii corespunzător, care oferă adevărul de bază pentru predicția texturii. Sursă: https://arxiv.org/pdf/2106.04185.pdf
Pe lângă noua metodă de reiluminare, cercetătorii susțin că LipSync3D oferă trei inovații principale cu privire la lucrările anterioare: separarea geometriei, luminii, poziției și texturii în fluxuri de date discrete într-un spațiu normalizat; un model auto-regresiv de predicție a texturii ușor de antrenat, care produce o sinteză video consistentă în timp; și un realism sporit, așa cum este evaluat de evaluările umane și metricile obiective.

Împărțirea diferitelor fațete ale imaginilor faciale video permite un control mai mare în sinteza video.
LipSync3D poate obține mișcarea corespunzătoare a geometriei buzelor direct din audio, analizând foneme și alte fațete ale vorbirii și transpunându-le în pozițiile musculare corespunzătoare cunoscute în jurul zonei gurii.

Acest proces folosește o conductă de predicție comună, în care geometria și textura deduse au codificatoare dedicate într-o configurație de autoencoder, dar partajează un encoder audio cu vorbirea care se intenționează să fie impusă modelului:

Sinteza labilă a mișcării LipSync3D este, de asemenea, menită să alimenteze avatarurile CGI stilizate, care de fapt sunt doar același tip de informații de plasă și textură ca și imaginile din lumea reală:
Un avatar 3D stilizat are mișcările buzelor alimentate în timp real de un video difuzor sursă. Într-un astfel de scenariu, cele mai bune rezultate ar fi obținute prin pre-training personalizat.
Cercetătorii anticipează, de asemenea, utilizarea avatarurilor cu o senzație ceva mai realistă:
![]()
Exemple de timpi de antrenament pentru videoclipuri variază de la 3-5 ore pentru un videoclip de 2-5 minute, într-un pipeline care utilizează TensorFlow, Python și C++ pe o GeForce GTX 1080. Sesiunile de antrenament au folosit o dimensiune a lotului de 128 de cadre peste 500-1000. epoci, fiecare epocă reprezentând o evaluare completă a videoclipului.

Spre resincronizarea dinamică a mișcării buzelor
Domeniul resincronizării buzelor pentru a găzdui o nouă pistă audio a primit o mare atenție în cercetarea vederii computerizate în ultimii câțiva ani (a se vedea mai jos), nu în ultimul rând deoarece este un produs secundar al controversatelor tehnologie deepfake.
În 2017, Universitatea din Washington cercetarea prezentată capabil să învețe sincronizarea buzelor din audio, folosindu-l pentru a schimba mișcările buzelor președintelui de atunci Obama. În 2018; Institutul de Informatică Max Planck a condus o altă inițiativă de cercetare pentru a activa transferul video identitate>identitate, cu sincronizare buzelor a produs secundar al procesului; iar în mai 2021, startup-ul AI FlawlessAI a dezvăluit tehnologia proprie de sincronizare a buzelor TrueSync, pe scară largă primit în presă ca un factor de sprijin al tehnologiilor de dublare îmbunătățite pentru lansări majore de filme în diferite limbi.
Și, desigur, dezvoltarea continuă a depozitelor open source deepfake oferă o altă ramură a cercetării active contribuite de utilizatori în această sferă a sintezei imaginilor faciale.















