Inteligență artificială
Inteligența artificială ajută vorbitorii nervoși să ‘citească sala’ în timpul videoconferințelor

În 2013, un sondaj privind fobiile comune a determinat că perspectiva de a vorbi în public a fost mai rea decât perspectiva de a muri pentru majoritatea respondenților. Sindromul este cunoscut sub numele de glossophobia.
Migrația determinată de COVID de la întâlnirile “față în față” la conferințele online Zoom pe platforme precum Zoom și Google Spaces a surprins, nu a îmbunătățit situația. În cazul în care întâlnirea conține un număr mare de participanți, capacitățile noastre naturale de evaluare a amenințărilor sunt afectate de rândurile și iconele cu rezoluție scăzută ale participanților și de dificultatea de a citi semnalele vizuale subtile ale expresiilor faciale și limbajului corporal. De exemplu, s-a constatat că Skype este o platformă slabă pentru transmiterea de indicii non-verbali.
Efectele asupra performanței de vorbire publică a interesului și răspunsului perceput sunt bine documentate și, în mod intuitiv, evidente pentru majoritatea dintre noi. Răspunsul opac al audienței poate face ca vorbitorii să ezite și să se retragă la discursul de umplere, fără să știe dacă argumentele lor sunt întâmpinate cu acord, dispreț sau indiferență, făcând adesea o experiență incomodă atât pentru vorbitor, cât și pentru ascultători.
Sub presiunea schimbării neașteptate către videoconferințele online inspirate de restricțiile și precauțiile COVID, problema este, în mod evident, înrăutățită, iar o serie de scheme de feedback de audiență ameliorative au fost sugerate în comunitățile de cercetare a viziunii calculate și a afectului în ultimii doi ani.
Soluții axate pe hardware
Majoritatea acestora, însă, implică echipamente suplimentare sau software complex care pot ridica probleme de confidențialitate sau logistice – stiluri de abordare relativ costisitoare sau altfel limitate de resurse, care preced pandemia. În 2001, MIT a propus Galvactivatorul, un dispozitiv purtat pe mână care inferă starea emoțională a participantului la audiență, testat în timpul unui simpozion de o zi.

Din 2001, Galvactivatorul MIT, care a măsurat răspunsul de conductivitate a pielii în încercarea de a înțelege sentimentul și implicarea audienței. Sursă: https://dam-prod.media.mit.edu/x/files/pub/tech-reports/TR-542.pdf
O cantitate considerabilă de energie academică a fost dedicată și posibilei implementării “apăsătoarelor” ca sistem de răspuns al audienței (ARS), o măsură pentru a crește participarea activă a audienței (care crește automat implicarea, deoarece forțează vizionarul în rolul unui nod de feedback activ), dar care a fost imaginat și ca un mijloc de încurajare a vorbitorului.
Alte încercări de “conectare” a vorbitorului și a audienței au inclus monitorizarea ritmului cardiac, utilizarea unor echipamente complexe purtate pe corp pentru a valorifica electroencefalografia, “măsurători de aplauze”, recunoașterea computerizată a emoțiilor pentru lucrătorii de birou și utilizarea emoticonurilor trimise de audiență în timpul oratoriei vorbitorului.

Din 2017, EngageMeter, un proiect de cercetare comun al LMU Munich și al Universității din Stuttgart. Sursă: http://www.mariamhassib.net/pubs/hassib2017CHI_3/hassib2017CHI_3.pdf
Ca o sub-urmărire a zonei lucrative a analizei audienței, sectorul privat a manifestat un interes deosebit pentru estimarea și urmărirea privirii – sisteme în care fiecare membru al audienței (care, la rândul său, va trebui să vorbească), este supus urmăririi oculare ca indice al implicării și aprobării.
Toate aceste metode sunt destul de “înfricoșătoare”. Multe dintre ele necesită echipamente personalizate, medii de laborator, cadre software specializate și abonamente la API-uri comerciale scumpe – sau orice combinație a acestor factori restrictivi.
Prin urmare, dezvoltarea unor sisteme minimaliste bazate pe unelte comune pentru videoconferințe a devenit de interes în ultimele 18 luni.
Raportarea aprobării audienței în mod discret
În acest scop, o nouă colaborare de cercetare între Universitatea din Tokyo și Universitatea Carnegie Mellon oferă un sistem nou care poate fi conectat la unelte standard de videoconferință (cum ar fi Zoom) utilizând doar un site web cu webcam activat, pe care rulează software ușor de estimare a privirii și a poziției. În acest fel, chiar și nevoia de plugin-uri de browser locale este evitată.
Nodurile și atenția estimată a utilizatorului sunt traduse în date reprezentative care sunt vizualizate înapoi către vorbitor, permițând un “test de acid” în timp real al gradului în care conținutul implică audiența – și, de asemenea, cel puțin un indicator vag al perioadelor de discurs în care vorbitorul poate pierde interesul audienței.
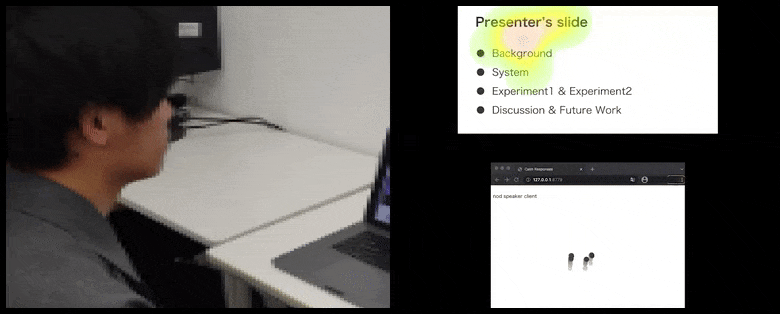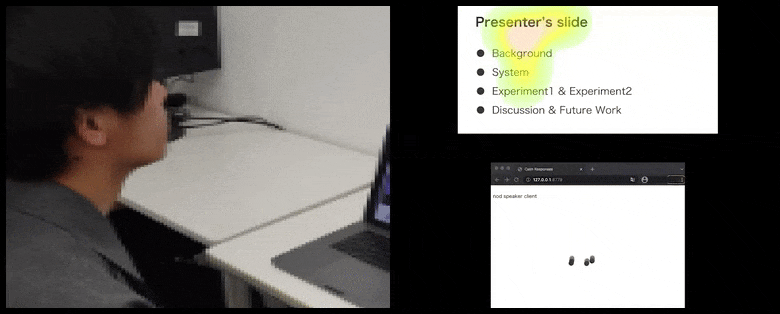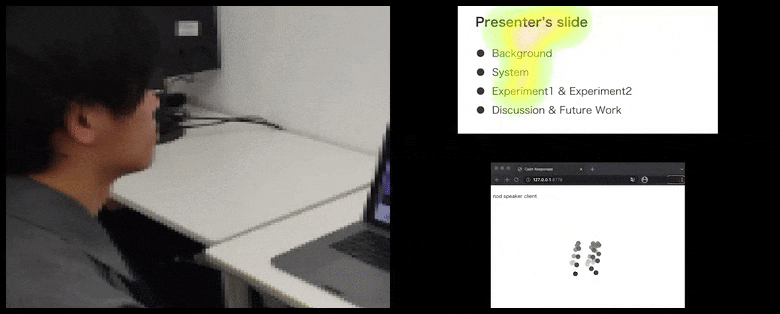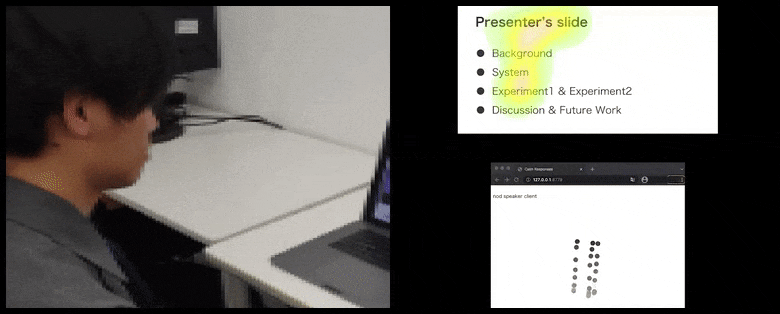
Cu CalmResponses, atenția și nodul utilizatorului sunt adăugate la un grup de feedback al audienței și traduse într-o reprezentare vizuală care poate beneficia vorbitorul. Vezi videoul încorporat la sfârșitul articolului pentru mai multe detalii și exemple. Sursă: https://www.youtube.com/watch?v=J_PhB4FCzk0
În multe situații academice, cum ar fi prelegerile online, studenții pot fi complet invizibili pentru vorbitor, deoarece nu și-au activat camerele web din cauza conștientizării fundalului sau a aspectului lor actual. CalmResponses poate aborda această piedică, altfel spinosă, a feedback-ului vorbitorului, raportând ceea ce știe despre modul în care vorbitorul se uită la conținut și dacă este nodul, fără nicio necesitate ca vizionarul să-și activeze camera.
Articolul științific se intitulează CalmResponses: Displaying Collective Audience Reactions in Remote Communication și este o lucrare comună între doi cercetători de la UoT și unul de la Carnegie Mellon.
Autorii oferă o demonstrație live pe web și au lansat codul sursă pe GitHub.
Cadru CalmResponses
Interesul CalmResponses pentru noduri, în contrast cu alte dispoziții posibile ale capului, se bazează pe cercetări (unele dintre ele datând din epoca lui Darwin) care indică faptul că mai mult de 80% din toate mișcările capului ascultătorilor sunt alcătuite din noduri (chiar și atunci când exprimă dezacord). În același timp, mișcările privirii au fost demonstrate pe numeroase studii a fi un indice fiabil al interesului sau implicării.
CalmResponses este implementat cu HTML, CSS și JavaScript și cuprinde trei subsisteme: un client de audiență, un client de vorbitor și un server. Clientul de audiență transmite datele privirii ochilor sau mișcării capului de la webcam-ul utilizatorului prin WebSockets peste platforma de aplicații cloud Heroku.

Nodurile audienței vizualizate pe partea dreaptă într-o mișcare animată sub CalmResponses. În acest caz, vizualizarea mișcării este disponibilă nu numai pentru vorbitor, ci și pentru întreaga audiență. Sursă: https://arxiv.org/pdf/2204.02308.pdf
Pentru secțiunea de urmărire a privirii din proiect, cercetătorii au utilizat WebGazer, un cadru de urmărire a privirii ușor, bazat pe JavaScript, care poate rula cu latență scăzută direct de pe un site web (vezi linkul de mai sus pentru implementarea web proprie a cercetătorilor).
Deoarece nevoia de implementare simplă și recunoaștere a răspunsului agregat depășește nevoia de acuratețe ridicată în estimarea privirii și poziției, datele de intrare ale poziției sunt netezite în funcție de valorile medii înainte de a fi luate în considerare pentru estimarea răspunsului general.
Acțiunea de nodare este evaluată prin biblioteca JavaScript clmtrackr, care ajustează modele faciale la fețele detectate în imagini sau videoclipuri prin deplasarea medie a reperelor regulate. În scopul economiei și al latenței scăzute, doar reperele detectate pentru nas sunt monitorizate activ în implementarea autorilor, deoarece acest lucru este suficient pentru a urmări acțiunile de nodare.
Mișcarea vârfului nasului utilizatorului creează un traseu care contribuie la grupul de răspuns al audienței legat de noduri, vizualizat în mod agregat pentru toți participanții.
Hartă de căldură
În timp ce activitatea de nodare este reprezentată prin puncte dinamice în mișcare (vezi imagini mai sus și videoul de la sfârșit), atenția vizuală este raportată în termeni de hartă de căldură care arată vorbitorului și audienței unde se concentrează locusul general al atenției pe ecranul de prezentare sau mediu de videoconferință partajat.

Toți participanții pot vedea unde se concentrează atenția generală a utilizatorului. Articolul nu menționează dacă această funcționalitate este disponibilă atunci când utilizatorul poate vedea o ‘galerie’ de alți participanți, ceea ce ar putea dezvălui o focalizare specioasă pe un anumit participant, din diverse motive.
Teste
Două medii de test au fost formulate pentru CalmResponses sub forma unui studiu de ablație tacit, utilizând trei seturi variate de circumstanțe: în ‘Condiția B’ (bază), autorii au replicat o prelegere online tipică pentru studenți, în care majoritatea studenților țin camerele web închise, iar vorbitorul nu are posibilitatea de a vedea fețele audienței; în ‘Condiția CR-E’, vorbitorul putea vedea feedback-ul privirii (hărți de căldură); în ‘Condiția CR-N’, vorbitorul putea vedea atât activitatea de nodare, cât și cea de privire a audienței.
Primul scenariu experimental a cuprins condiția B și condiția CR-E; al doilea a cuprins condiția B și condiția CR-N. Feedback-ul a fost obținut atât de la vorbitori, cât și de la audiență.
În fiecare experiment, trei factori au fost evaluați: evaluarea obiectivă și subiectivă a prezentării (inclusiv un chestionar auto-raportat de la vorbitor cu privire la sentimentele sale despre modul în care a decurs prezentarea); numărul de evenimente de “discurs de umplere”, care indică nesiguranță și prevaricație momentană; și comentarii calitative. Aceste criterii sunt comune estimatori ai calității discursului și anxietății vorbitorului.
Baza de test a constat din 38 de persoane cu vârste cuprinse între 19 și 44 de ani, alcătuită din 29 de bărbați și nouă femei, cu o vârstă medie de 24,7 ani, toți japonezi sau chinezi și toți vorbitori de japoneză. Ei au fost împărțiți aleatoriu în cinci grupuri de 6-7 participanți și niciunul dintre subiecți nu se cunoșteau personal.
Testele au fost efectuate pe Zoom, cu cinci vorbitori care au prezentat prelegeri în primul experiment și șase în al doilea.

Condiții de umplere marcate cu cutii portocalii. În general, conținutul de umplere a scăzut într-o proporție rezonabilă cu feedback-ul crescut al audienței de la sistem.
Cercetătorii notează că unul dintre vorbitori a avut o reducere notabilă a filler-elor și că, în ‘Condiția CR-N’, vorbitorul a rareori a rostit fraze de umplere. Vezi articolul pentru rezultatele foarte detaliate și granulare raportate; cu toate acestea, cele mai marcante rezultate au fost în evaluarea subiectivă a vorbitorilor și participanților la audiență.
Comentariile audienței au inclus:
‘M-am simțit implicat în prezentări” [AN2], “Nu eram sigur că discursurile vorbitorilor au fost îmbunătățite, dar am simțit un sentiment de unitate din cauza vizualizării mișcărilor capului altor persoane.’ [AN6]
‘Nu eram sigur că discursurile vorbitorilor au fost îmbunătățite, dar am simțit un sentiment de unitate din cauza vizualizării mișcărilor capului altor persoane.’
Cercetătorii notează că sistemul introduce un nou tip de pauză artificială în prezentarea vorbitorului, deoarece vorbitorul este înclinat să se refere la sistemul vizual pentru a evalua feedback-ul audienței înainte de a continua.
Ei notează, de asemenea, un fel de “efect de halat alb”, dificil de evitat în circumstanțele experimentale, în care unii participanți s-au simțit constrânși de implicațiile de securitate posibile ale monitorizării datelor biometrice.
Concluzie
Un avantaj notabil într-un sistem precum acesta este că toate tehnologiile auxiliare nestandard necesare pentru o astfel de abordare dispar complet după utilizare. Nu există plugin-uri de browser reziduale de dezinstalat sau care să ridice îndoieli în mintea participanților cu privire la faptul că ar trebui să rămână pe sistemele respective; și nu există nevoia de a ghida utilizatorii prin procesul de instalare (deși cadru web-based necesită un minut sau două de calibrare inițială de la utilizator), sau de a naviga posibilitatea ca utilizatorii să nu aibă permisiuni adecvate pentru a instala software local, inclusiv suplimente și extensii de browser.
Deși mișcările faciale și oculare evaluate nu sunt la fel de precise cum ar fi în circumstanțe în care cadrele de învățare automată dedicate (cum ar fi seria YOLO) ar fi utilizate, această abordare aproape fără frecare a evaluării audienței oferă o acuratețe suficientă pentru analiză generală a sentimentului și a atitudinii în scenarii tipice de videoconferință. Mai presus de toate, este foarte ieftin.
Vezi videoul proiectului asociat de mai jos pentru detalii și exemple suplimentare.
Publicat pentru prima dată pe 11 aprilie 2022.












