Kunstig intelligens
Mot menneskelige AI-er med Neural Lumigraph Rendering i sanntid

Til tross for den nåværende bølgen av interesse for Neural Radiance Fields (NeRF), en teknologi som kan lage AI-genererte 3D-miljøer og objekter, krever denne nye tilnærmingen til bilde-synteseteknologi fortsatt en stor mengde treningstid, og mangler en implementering som muliggjør sanntids-, høyresponsive grensesnitt.
Imidlertid tilbyr et samarbeid mellom noen imponerende navn i industri og akademia en ny tilnærming til denne utfordringen (generisk kjent som Novel View Synthesis, eller NVS).
Forskningspaperet paper, med tittelen Neural Lumigraph Rendering, hevder en forbedring på state-of-the-art på omtrent to størrelsesordener, og representerer flere skritt mot sanntids-CG-rendering via maskinlæringsrørledninger.

Neural Lumigraph Rendering (høyre) tilbyr bedre oppløsning av blandingsspor, og forbedret håndtering av okklusjon enn tidligere metoder. Source.
Til tross for at kreditter for paperet bare nevner Stanford University og holografisk display-teknologiselskap Raxium (nåværende opererer i stealth-modus), inkluderer bidragsyterne en hovedmaskinlæringsarkitekt hos Google, en datavitenskapsmann hos Adobe, og CTO hos StoryFile (som nylig lagde overskrifter med en AI-versjon av William Shatner).
I forhold til den nylige Shatner-publisitetsblitz, ser det ut til at StoryFile anvender NLR i sin nye prosess for å lage interaktive, AI-genererte enheter basert på karakteristika og narrativer til enkeltpersoner.
StoryFile forestiller bruken av denne teknologien i museum-utstillinger, online-interaktive narrativer, holografiske skjermer, augmented reality (AR) og kulturarv-dokumentasjon – og ser også ut til å vurdere potensielle nye anvendelser av NLR i rekrutteringsintervjuer og virtuelle dating-applikasjoner:

Forslag til anvendelser fra en online-video av StoryFile. Source: https://www.youtube.com/watch?v=2K9J6q5DqRc
Volumetrisk fangst for Novel View Synthesis-grensesnitt og video
Prinsippet om volumetrisk fangst, over hele rekken av papirer som samler seg på emnet, er ideen om å ta stillbilder eller videoer av et subjekt, og bruke maskinlæring til å “fylle ut” de utsiktene som ikke ble dekket av den opprinnelige rekken av kameraer.

Source: https://research.fb.com/wp-content/uploads/2019/06/Neural-Volumes-Learning-Dynamic-Renderable-Volumes-from-Images.pdf
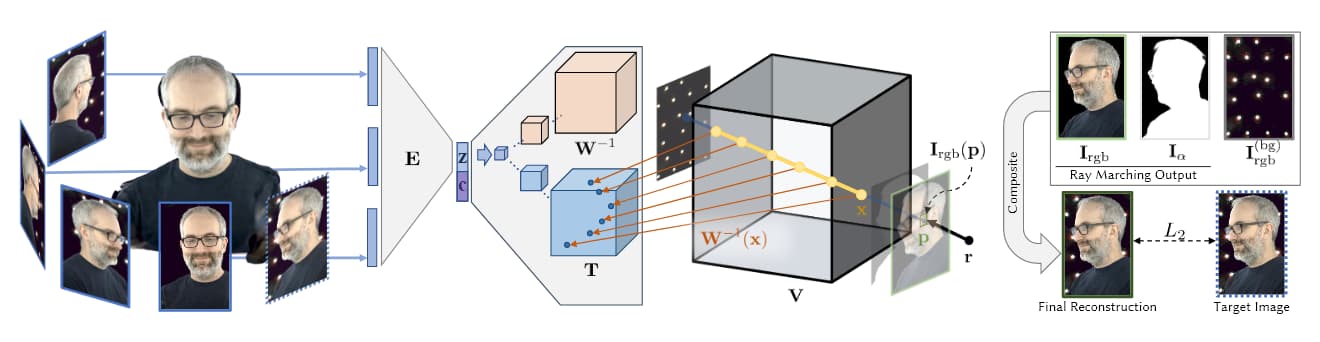
I bildet over, tatt fra Facebooks AI-forskning i 2019 (se under), ser vi de fire stadiene av volumetrisk fangst: flere kameraer får bilder/filmmateriale; encoder/decoder-arkitektur (eller andre arkitekturer) beregner og kobler sammen relativiteten av utsiktene; ray-marching-algoritmer beregner voxelene (eller andre XYZ-geometriske enheter) for hvert punkt i det volumetriske rommet; og (i de fleste nyere papirer) trening skjer for å syntetisere en fullstendig enhet som kan manipuleres i sanntid.
Det er denne ofte omfattende og data-tyngde treningfasen som har, til nå, holdt Novel View Synthesis utenfor sanntids- eller høyresponsivt område.
Det faktum at Novel View Synthesis lager en fullstendig 3D-kart over et volumetrisk rom, betyr at det er relativt enkelt å sy sammen disse punktene til en tradisjonell datagenerert mesh, og effektivt fange og artikulere en CGI-menneske (eller andre relativt begrensede objekter) på fly.
Tilnærmingene som bruker NeRF, baserer seg på punktskyer og dybdekart for å generere interpolasjonene mellom de sparsomme utsiktene til fangst-enhetene:

NeRF kan generere volumetrisk dybde gjennom beregning av dybdekart, snarere enn generering av CG-mesh. Source: https://www.youtube.com/watch?v=JuH79E8rdKc
Til tross for at NeRF er i stand til å beregne mesh, bruker de fleste implementeringer ikke dette for å generere volumetriske scener.
I motsetning til dette, henger Implicit Differentiable Renderer (IDR)-tilnærmingen, publisert av Weizmann Institute of Science i oktober 2020, på å utnytte 3D-mesh-informasjon som genereres automatisk fra fangst-arrays:

Eksempler på IDR-fangster som er omdannet til interaktive CGI-mesh. Source: https://www.youtube.com/watch?v=C55y7RhJ1fE
Mens NeRF mangler IDRs evne til form-analyse, kan IDR ikke matche NeRFs bildekvalitet, og begge krever omfattende ressurser for å trene og samle (selv om nyere innovasjoner i NeRF begynner å adresse dette).

NLRs egendefinerte kamera-rig med 16 GoPro HERO7 og 6 sentrale Back-Bone H7PRO-kameraer. For ‘sanntids’-rendering, opererer disse med en minimumsfrekvens på 60fps. Source: https://arxiv.org/pdf/2103.11571.pdf
I stedet, bruker Neural Lumigraph Rendering SIREN (Sinusoidal Representation Networks) for å inkorporere styrkene til hver tilnærming i sin egen ramme, som er ment å generere utgang som er direkte brukbar i eksisterende sanntids-grafikk-rørledninger.
SIREN har blitt brukt i lignende implementasjoner over det siste året, og representerer nå en populær API-kall for hobbyist-Colabs i bilde-syntese-samfunn; imidlertid er NLRs innovasjon å anvende SIRENer på todimensjonal fler-utsikts-bilde-tilsyn, som er problematisk på grunn av hvor mye SIREN produserer over-tilpasset snarere enn generalisert utgang.
Etter at CG-meshen er ekstrahert fra array-bildene, rasteriseres meshen via OpenGL, og vertex-posisjonene til meshen kartlegges til de aktuelle pikslene, etterfulgt av at blandingen av de ulike bidragende kartene beregnes.
Den resulterende meshen er mer generalisert og representativ enn NeRFs (se bildet under), krever mindre beregning, og anvender ikke eksessiv detalj til områder (slik som glatt ansikts-hud) som ikke kan dra nytte av det:

Source: https://arxiv.org/pdf/2103.11571.pdf
På negativ side, har NLR ennå ingen kapasitet for dynamisk lys eller relighting, og utgangen er begrenset til skygge-kart og andre lys-hensyn som er oppnådd ved tidspunktet for fangst. Forskerne har til hensikt å adresse dette i fremtidig arbeid.
I tillegg, innrømmer paperet at formene som genereres av NLR, ikke er like nøyaktige som noen alternative tilnærminger, som Pixelwise View Selection for Unstructured Multi-View Stereo, eller Weizmann Institute-forskningen nevnt tidligere.
Oppgangen av volumetrisk bilde-syntese
Idéen om å lage 3D-enheter fra en begrenset rekke bilder med neurale nettverk, forutsetter NeRF, med visjonære papirer som går tilbake til 2007 eller tidligere. I 2019 produserte Facebooks AI-forskningsavdeling en semineral forskningspaper, Neural Volumes: Learning Dynamic Renderable Volumes from Images, som først muliggjorde responsive grensesnitt for syntetiske mennesker generert av maskinlærings-basert volumetrisk fangst.

Facebooks 2019-forskning muliggjorde opprettelsen av et responsivt brukergrensesnitt for en volumetrisk person. Source: https://research.fb.com/publications/neural-volumes-learning-dynamic-renderable-volumes-from-images/













{kind=link}