Kunstmatige intelligentie
Zero123++: Een enkel beeld naar consistente multi-view diffusiebasismodel

De afgelopen jaren hebben een snelle vooruitgang gezien in de prestaties, efficiëntie en generatieve mogelijkheden van opkomende nieuwe AI-generatieve modellen die gebruikmaken van uitgebreide datasets en 2D-diffusiegeneratiepraktijken. Vandaag de dag zijn generatieve AI-modellen extreem capabel om verschillende vormen van 2D- en tot op zekere hoogte 3D-mediacontent te genereren, waaronder tekst, afbeeldingen, video’s, GIF’s en meer.
In dit artikel zullen we het hebben over het Zero123++-framework, een beeld-geconditioneerd diffusiegeneratief AI-model met als doel 3D-consistente multi-view-afbeeldingen te genereren met behulp van één enkel beeld als invoer. Om het voordeel te maximaliseren dat wordt behaald met behulp van eerder getrainde generatieve modellen, implementeert het Zero123++-framework verschillende trainings- en conditioneringsschema’s om de hoeveelheid inspanning te minimaliseren die nodig is om de afstemming van standaard diffusiebeeldmodellen te fine-tunen. We zullen een diepere duik nemen in de architectuur, de werking en de resultaten van het Zero123++-framework en analyseren of het in staat is om consistente multi-view-afbeeldingen van hoge kwaliteit te genereren vanuit één enkel beeld. Laten we dus beginnen.
Zero123 en Zero123++: Een Inleiding
Het Zero123++-framework is een beeld-geconditioneerd diffusiegeneratief AI-model dat 3D-consistente multi-view-afbeeldingen wil genereren met behulp van één enkel beeld als invoer. Het Zero123++-framework is een voortzetting van het Zero123- of Zero-1-to-3-framework dat gebruikmaakt van zero-shot novel view image synthesis-techniek om open-source single-image-to-3D-conversies te pionieren. Hoewel het Zero123++-framework veelbelovende prestaties levert, hebben de door het framework gegenereerde afbeeldingen zichtbare geometrische inconsistenties, en dat is de belangrijkste reden waarom de kloof tussen 3D-scènes en multi-view-afbeeldingen nog steeds bestaat.
Het Zero-1-to-3-framework dient als basis voor verschillende andere frameworks, waaronder SyncDreamer, One-2-3-45, Consistent123 en meer, die extra lagen toevoegen aan het Zero123-framework om consistentere resultaten te behalen bij het genereren van 3D-afbeeldingen. Andere frameworks, zoals ProlificDreamer, DreamFusion, DreamGaussian en meer, volgen een op optimalisatie gebaseerde aanpak om 3D-afbeeldingen te verkrijgen door een 3D-afbeelding te destilleren uit verschillende inconsistentie-modellen. Hoewel deze technieken effectief zijn en ze bevredigende 3D-afbeeldingen genereren, zouden de resultaten verbeterd kunnen worden met de implementatie van een basisdiffusiemodel dat in staat is om multi-view-afbeeldingen consistent te genereren. Daarom neemt het Zero123++-framework het Zero-1-to-3- en fine-tuned een nieuw multi-view-basisdiffusiemodel vanuit Stable Diffusion.
In het Zero-1-to-3-framework wordt elke nieuwe weergave onafhankelijk gegenereerd, en deze aanpak leidt tot inconsistenties tussen de gegenereerde weergaven, omdat diffusiemodellen een steekproefkarakter hebben. Om dit probleem aan te pakken, past het Zero123++-framework een tiling-layoutaanpak toe, waarbij het object wordt omgeven door zes weergaven in één afbeelding, en zorgt ervoor dat de juiste modellering plaatsvindt voor de gezamenlijke verdeling van een object multi-view-afbeeldingen.
Een andere grote uitdaging waarmee ontwikkelaars die werken aan het Zero-1-to-3-framework worden geconfronteerd, is dat het de mogelijkheden die worden aangeboden door Stable Diffusion onvoldoende benut, wat leidt tot inefficiëntie en extra kosten. Er zijn twee belangrijke redenen waarom het Zero-1-to-3-framework de mogelijkheden van Stable Diffusion niet ten volle kan benutten
- Wanneer het wordt getraind met beeldvoorwaarden, neemt het Zero-1-to-3-framework de lokale of globale conditioneringmechanismen die worden aangeboden door Stable Diffusion niet effectief op.
- Tijdens de training gebruikt het Zero-1-to-3-framework een verlaagde resolutie, een aanpak waarbij de uitvoeresolutie wordt verlaagd tot onder de trainingsresolutie, wat de kwaliteit van beeldgeneratie voor Stable Diffusion-modellen kan verminderen.
Om deze problemen aan te pakken, implementeert het Zero123++-framework een reeks conditioneringstechnieken die de benutting van resources die worden aangeboden door Stable Diffusion maximaliseren en de kwaliteit van beeldgeneratie voor Stable Diffusion-modellen behouden.
Verbetering van Conditionering en Consistentie
In een poging om beeldconditionering en multi-view-afbeeldingsconsistentie te verbeteren, heeft het Zero123++-framework verschillende technieken geïmplementeerd, met als primair doel het hergebruiken van eerder toegepaste technieken uit het voorgetrainde Stable Diffusion-model.
Multi-View Generatie
De onmisbare kwaliteit van het genereren van consistente multi-view-afbeeldingen ligt in het correct modelleren van de gezamenlijke verdeling van meerdere afbeeldingen. In het Zero-1-to-3-framework wordt de correlatie tussen multi-view-afbeeldingen genegeerd, omdat voor elke afbeelding het framework de conditionele marginale verdeling onafhankelijk en afzonderlijk modelleert. Echter, in het Zero123++-framework hebben ontwikkelaars gekozen voor een tiling-layoutaanpak die zes afbeeldingen in één kader/afbeelding tegelt voor consistente multi-view-generatie, en het proces wordt gedemonstreerd in de volgende afbeelding.
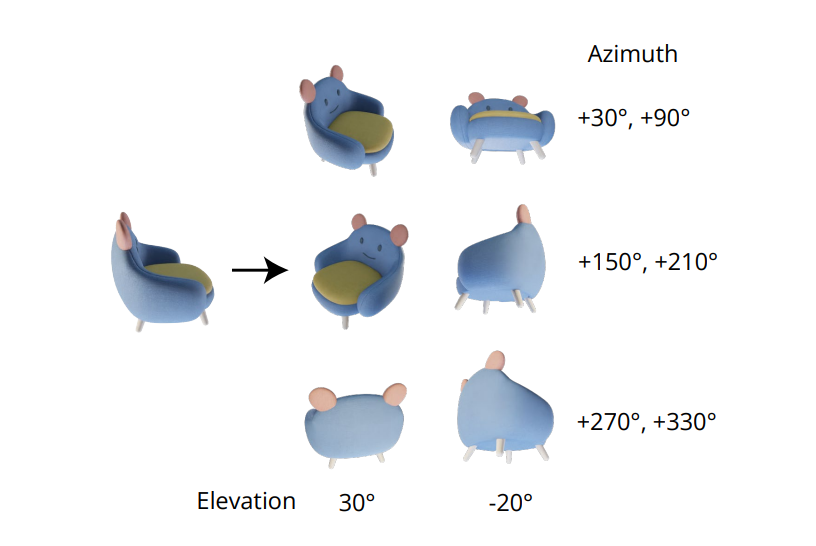

Bovendien is het opgemerkt dat objectoriëntaties de neiging hebben om te worden gedesambigueerd wanneer het model wordt getraind op cameraposities, en om deze desambiguïsatie te voorkomen, traint het Zero-1-to-3-framework op cameraposities met elevatiehoeken en relatieve azimut ten opzichte van de invoer. Om deze elevatiehoek te kennen, voegen frameworks vaak een elevatie-schattingmodule toe, en deze aanpak komt vaak ten koste van extra fouten in de pijplijn.
Ruis Schema
Geschaalde lineaire schema, het oorspronkelijke ruis-schema voor Stable Diffusion, richt zich voornamelijk op lokale details, maar zoals te zien is in de volgende afbeelding, heeft het heel weinig stappen met een lage SNR of signaal-ruisverhouding.


Deze stappen met een lage signaal-ruisverhouding treden op vroeg in de denoisingfase, een fase die cruciaal is voor het bepalen van de globale laagfrequente structuur. Het verminderen van het aantal stappen tijdens de denoisingfase, hetzij tijdens interferentie of training, resulteert vaak in een grotere structurele variatie. Hoewel deze instelling ideaal is voor single-imagegeneratie, beperkt het de mogelijkheid van het framework om globale consistentie tussen verschillende weergaven te garanderen. Om deze hindernis te overwinnen, fine-tuned het Zero123++-framework een LoRA-model op het Stable Diffusion 2-v-predictieframework om een speeltaak uit te voeren, en de resultaten worden hieronder gedemonstreerd.

Met het geschaalde lineaire ruis-schema overpast het LoRA-model niet, maar wit het de afbeelding alleen licht. Anderszijds, wanneer het werkt met het lineaire ruis-schema, genereert het LoRA-framework een lege afbeelding met succes, ongeacht de invoerprompt, wat aangeeft dat de invloed van het ruis-schema op de mogelijkheid van het framework om zich aan te passen aan nieuwe globale vereisten.
Geschaalde Referentie Aandacht voor Lokale Voorwaarden
De enkele beeldinvoer of de conditioneringafbeeldingen in het Zero-1-to-3-framework worden samengevoegd met de lawaaierige invoer in de functiedimensie om te worden geluid voor beeldconditionering.
Deze samenvoeging leidt tot een onjuiste pixel-voor-pixel-spatiale overeenstemming tussen de doelafbeelding en de invoer. Om een juiste lokale conditioneringinvoer te bieden, maakt het Zero123++-framework gebruik van een geschaalde Referentie Aandacht, een aanpak waarbij een denoising UNet-model wordt uitgevoerd op een extra referentieafbeelding, gevolgd door de toevoeging van waarde-matrices en zelf-aandachtssleutel van de referentieafbeelding aan de respectieve aandachtlagen wanneer de modelinvoer wordt gedenoised, en het wordt gedemonstreerd in de volgende figuur.

De Referentie Aandacht-aanpak is in staat om de diffusiemodel te leiden om afbeeldingen te genereren die overeenkomen met de textuur van de referentieafbeelding en semantische inhoud zonder enige fine-tuning. Met fine-tuning levert de Referentie Aandacht-aanpak superieure resultaten met het latentie-geschaald.

Globale Conditionering: FlexDiffuse
In de oorspronkelijke Stable Diffusion-aanpak zijn de tekst-embeddings de enige bron voor globale embeddings, en de aanpak maakt gebruik van het CLIP-framework als tekst-encoder om cross-examinaties uit te voeren tussen de tekst-embeddings en de model-latentie. Als gevolg daarvan zijn ontwikkelaars vrij om de alignering tussen de tekst-ruimten en de resulterende CLIP-afbeeldingen te gebruiken voor globale beeldconditionering.
Het Zero123++-framework stelt voor om een trainbare variant van de lineaire geleidingsmechanisme te gebruiken om de globale beeldconditionering in het framework op te nemen met minimale fine-tuning nodig, en de resultaten worden hieronder gedemonstreerd. Zoals te zien is, zonder de aanwezigheid van een globale beeldconditionering, is de kwaliteit van de gegenereerde inhoud van het framework voldoende voor zichtbare gebieden die overeenkomen met de invoerbeeld. Echter, de kwaliteit van de door het framework gegenereerde afbeelding voor onzichtbare gebieden vertoont een aanzienlijke achteruitgang, wat voornamelijk te wijten is aan de onmogelijkheid van het model om de globale semantiek van het object af te leiden.

Model Architectuur
Het Zero123++-framework is getraind met het Stable Diffusion 2v-model als basis met behulp van de verschillende benaderingen en technieken die in het artikel worden genoemd. Het Zero123++-framework is voorgetraind op de Objaverse-dataset die is gerenderd met willekeurige HDRI-verlichting. Het framework neemt ook de gefaseerde trainingsplanningaanpak van het Stable Diffusion Image Variations-framework over om de hoeveelheid fine-tuning die nodig is verder te minimaliseren en zoveel mogelijk van de voorafgaande Stable Diffusion te behouden.
De werking of architectuur van het Zero123++-framework kan verder worden onderverdeeld in opeenvolgende stappen of fasen. De eerste fase ziet het framework fine-tunen van de KV-matrices van cross-aandachtlagen en de zelf-aandachtlagen van Stable Diffusion met AdamW als optimizer, 1000 warm-up-stappen en de cosinusleercurve die maximaliseert bij 7×10-5. In de tweede fase gebruikt het framework een zeer conservatieve constante leersnelheid met 2000 warm-up-sets en gebruikt het de Min-SNR-aanpak om de efficiëntie tijdens de training te maximaliseren.
Zero123++: Resultaten en Prestatievergelijking
Kwalitatieve Prestatie
Om de prestaties van het Zero123++-framework te beoordelen op basis van de gegenereerde kwaliteit, wordt het vergeleken met SyncDreamer en Zero-1-to-3-XL, twee van de beste state-of-the-art-frameworks voor inhoudsgeneratie. De frameworks worden vergeleken met vier invoerbeelden met verschillende reikwijdte. Het eerste beeld is een elektrische speelgoedkat, rechtstreeks genomen uit de Objaverse-dataset, en het heeft een grote onzekerheid over het achterste deel van het object. Het tweede is het beeld van een brandblusser, en het derde is het beeld van een hond die op een raket zit, gegenereerd door het SDXL-model. Het laatste beeld is een anime-illustratie. De vereiste elevatie-stappen voor de frameworks worden behaald door de elevatie-schattingmethode van het One-2-3-4-5-framework te gebruiken, en achtergrondverwijdering wordt bereikt met behulp van het SAM-framework. Zoals te zien is, genereert het Zero123++-framework hoge kwaliteit multi-view-afbeeldingen consistent, en is het in staat om te generaliseren naar out-of-domain 2D-illustraties en AI-gegenereerde afbeeldingen even goed.


Kwantitatieve Analyse
Om het Zero123++-framework kwantitatief te vergelijken met de state-of-the-art Zero-1-to-3- en Zero-1-to-3-XL-frameworks, evalueren ontwikkelaars de Learned Perceptual Image Patch Similarity (LPIPS)-score van deze modellen op de validatiesplitsdata, een subset van de Objaverse-dataset. Om de prestaties van het model op multi-view-afbeeldingsgeneratie te evalueren, telen de ontwikkelaars de grondwaarheidsreferentiebeelden en 6 gegenereerde afbeeldingen respectievelijk, en berekenen ze vervolgens de Learned Perceptual Image Patch Similarity (LPIPS)-score. De resultaten worden hieronder gedemonstreerd en zoals duidelijk te zien is, bereikt het Zero123++-framework de beste prestatie op de validatiesplitsset.

Tekst naar Multi-View Evaluatie
Om de mogelijkheid van het Zero123++-framework te evalueren om tekst-naar-multi-view-inhoud te genereren, gebruiken ontwikkelaars eerst het SDXL-framework met tekstprompts om een afbeelding te genereren, en vervolgens het Zero123++-framework op de gegenereerde afbeelding. De resultaten worden hieronder gedemonstreerd en zoals te zien is, in vergelijking met het Zero-1-to-3-framework dat geen consistente multi-view-generatie kan garanderen, keert het Zero123++-framework consistente, realistische en zeer gedetailleerde multi-view-afbeeldingen terug door de tekst-naar-afbeelding-naar-multi-view-aanpak of -pijplijn te implementeren.

Zero123++ Diepte ControlNet
Naast het basis-Zero123++-framework hebben ontwikkelaars ook de Depth ControlNet Zero123++ uitgebracht, een diepte-gestuurde versie van het oorspronkelijke framework gebouwd met behulp van de ControlNet-architectuur. De genormaliseerde lineaire afbeeldingen worden gerenderd in verband met de daaropvolgende RGB-afbeeldingen, en een ControlNet-framework wordt getraind om de geometrie van het Zero123++-framework te controleren met behulp van dieptewaarneming.


Conclusie
In dit artikel hebben we het gehad over Zero123++, een beeld-geconditioneerd diffusiegeneratief AI-model met als doel 3D-consistente multi-view-afbeeldingen te genereren met behulp van één enkel beeld als invoer. Om het voordeel te maximaliseren dat wordt behaald met behulp van eerder getrainde generatieve modellen, implementeert het Zero123++-framework verschillende trainings- en conditioneringsschema’s om de hoeveelheid inspanning te minimaliseren die nodig is om de afstemming van standaard diffusiebeeldmodellen te fine-tunen. We hebben ook de verschillende benaderingen en verbeteringen besproken die door het Zero123++-framework zijn geïmplementeerd om resultaten te behalen die vergelijkbaar zijn met, en zelfs overtreffen die van de huidige state-of-the-art-frameworks.
Echter, ondanks zijn efficiëntie en vermogen om hoge kwaliteit multi-view-afbeeldingen consistent te genereren, heeft het Zero123++-framework nog steeds enige ruimte voor verbetering, met potentiële onderzoeksgebieden zoals een
- Twee-Stappen-Refiner-Model dat de onmogelijkheid van Zero123++ om te voldoen aan globale vereisten voor consistentie zou kunnen oplossen.
- Extra Schaalvergrotingen om de mogelijkheid van Zero123++ om afbeeldingen van nog hogere kwaliteit te genereren verder te verbeteren.












