Andersons hoek
Waarom Adversarial Image Aanvallen Geen Grapje Zijn
Het aanvallen van beeldherkenningsystemen met zorgvuldig ontworpen adversarial beelden is de afgelopen vijf jaar beschouwd als een amusant maar triviaal bewijs van concept. Echter, nieuw onderzoek uit Australië suggereert dat het nonchalante gebruik van zeer populaire beeld datasets voor commerciële AI-projecten een duurzaam nieuw beveiligingsprobleem kan creëren.
Al een paar jaar proberen een groep academici aan de University of Adelaide iets belangrijks uit te leggen over de toekomst van AI-gebaseerde beeldherkenningsystemen.
Het is iets dat moeilijk (en zeer duur) zou zijn om nu te repareren, en dat onaanvaardbaar duur zou zijn om te verhelpen zodra de huidige trends in beeldherkenningsonderzoek volledig zijn ontwikkeld tot geïndustrialiseerde en commerciële inzet in 5-10 jaar.
Voordat we hier dieper op ingaan, laten we eerst naar een bloem kijken die wordt geclassificeerd als president Barack Obama, van een van de zes video’s die het team heeft gepubliceerd op de projectpagina:
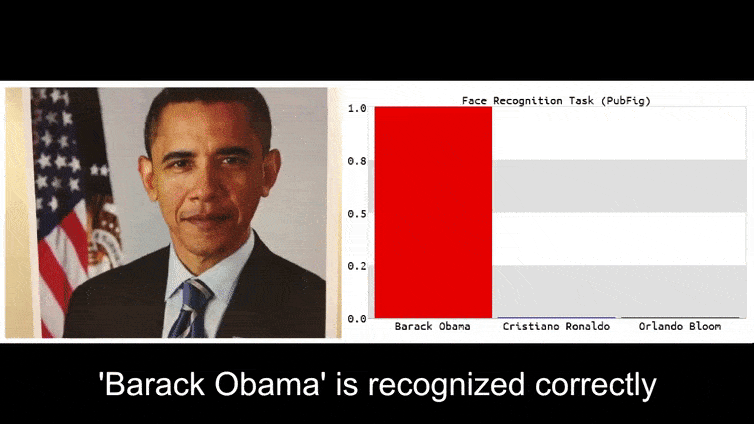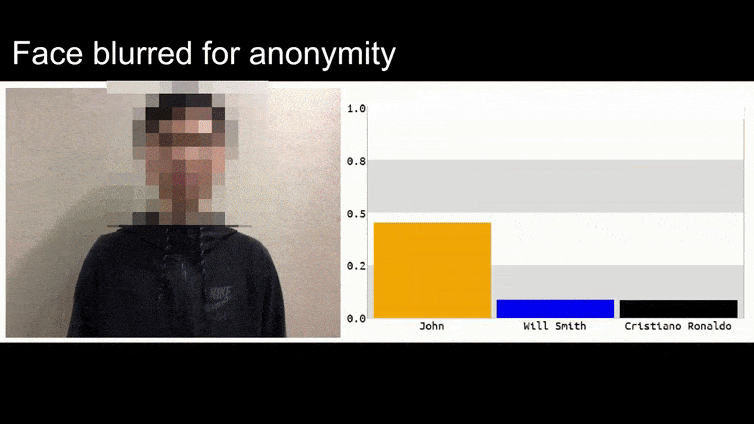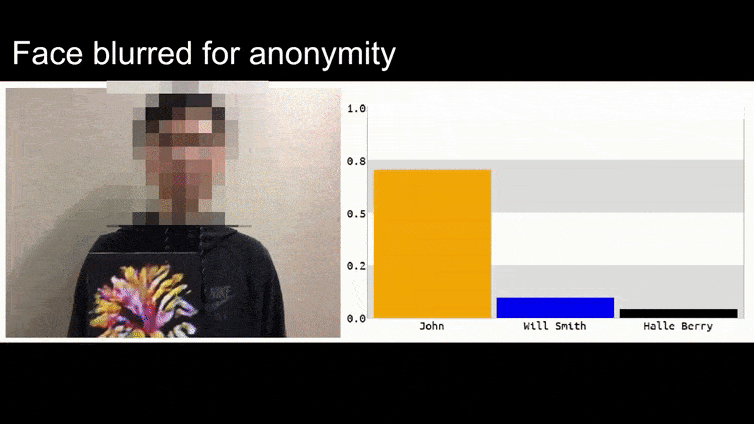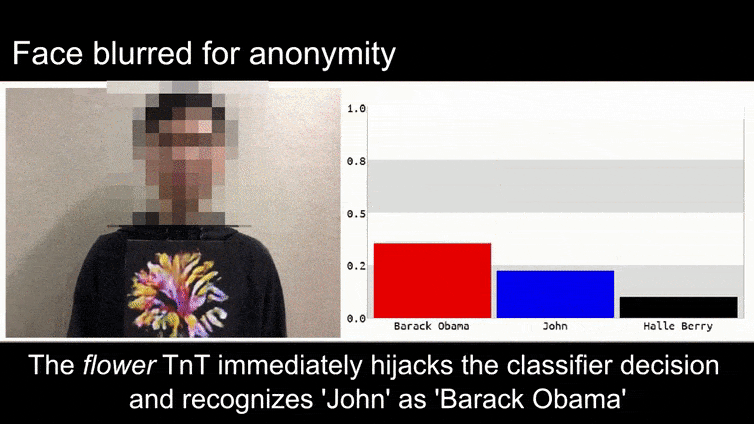
Bron: https://www.youtube.com/watch?v=Klepca1Ny3c
In bovenstaand beeld wordt een gezichtsherkenningssysteem dat duidelijk weet hoe het Barack Obama moet herkennen, misleid door 80% zekerheid dat een anonieme man met een gegenereerd, geprint adversarial beeld van een bloem ook Barack Obama is. Het systeem maakt zich niet druk over het feit dat het ‘valse gezicht’ op de borst van het onderwerp zit, in plaats van op zijn schouders.
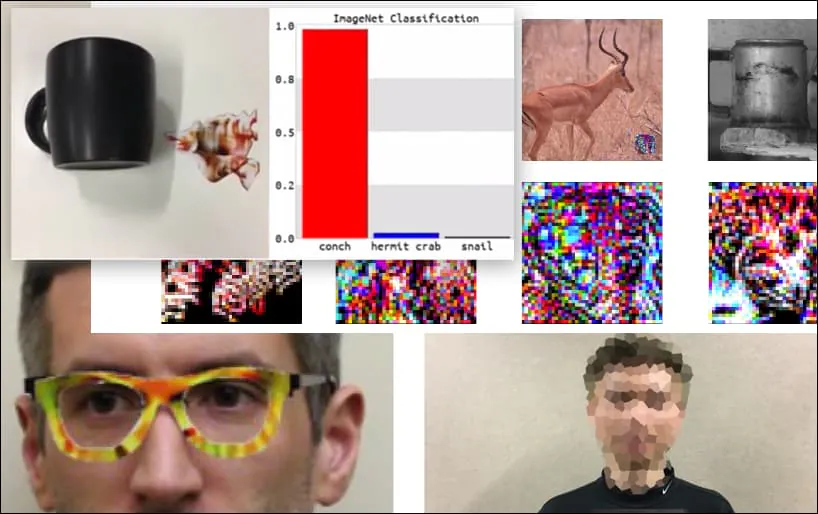
Hoewel het indrukwekkend is dat de onderzoekers in staat zijn gebleken om deze soort identiteitsverwerving te bereiken door een coherent beeld (een bloem) te genereren in plaats van alleen maar willekeurig ruis, lijkt het dat dergelijke grappige exploits vrij regelmatig opduiken in beveiligingsonderzoek naar computerzicht. Bijvoorbeeld, die vreemd gepatrouilleerde bril die in staat was om gezichtsherkenning in 2016 te misleiden, of speciaal gegenereerde adversarial beelden die proberen verkeersborden te herschrijven.
Als je geïnteresseerd bent, is het Convolutional Neural Network (CNN)-model dat in het bovenstaande voorbeeld wordt aangevallen VGGFace (VGG-16), getraind op de PubFig-dataset van Columbia University. Andere aanvalsvoorbeelden die door de onderzoekers zijn ontwikkeld, gebruikten verschillende bronnen in verschillende combinaties.

Een toetsenbord wordt opnieuw geclassificeerd als een schelp, in een WideResNet50-model op ImageNet. De onderzoekers hebben ervoor gezorgd dat het model geen voorkeur heeft voor schelpen. Bekijk de volledige video voor uitgebreide en aanvullende demonstraties op https://www.youtube.com/watch?v=dhTTjjrxIcU
Beeldherkenning als een Nieuw Aanvalsvector
De vele indrukwekkende aanvallen die de onderzoekers schetsen en illustreren, zijn geen kritiek op individuele datasets of specifieke machine learning-architecturen die deze gebruiken. Zij kunnen evenmin eenvoudig worden verdedigd door van dataset of model te wisselen, modellen opnieuw te trainen of een van de andere ‘eenvoudige’ remedies die ML-praktijkmensen doen snuiven naar sporadische demonstraties van dit soort trucage.
Het team van Adelaide’s exploit illustreert eerder een centrale zwakte in de hele huidige architectuur van AI-gebaseerde beeldherkenningsontwikkeling; een zwakte die veel toekomstige beeldherkenningsystemen kan blootstellen aan gemakkelijke manipulatie door aanvallers en kan zorgen voor defensieve maatregelen die op de achtergrond worden gezet.
Stel je voor dat de laatste adversarial aanvalsbeelden (zoals de bloem hierboven) worden toegevoegd als ‘zero-day exploits’ aan beveiligingssystemen van de toekomst, net zoals huidige anti-malware- en antivirusframeworks hun virusdefinities elke dag bijwerken.
Het potentieel voor nieuwe adversarial beeldaanvallen zou eindeloos zijn, omdat de fundamenten van de systeemarchitectuur geen downstream-problemen hebben voorzien, zoals het geval was met het internet, de Millennium Bug en de scheve toren van Pisa.
Op welke manier zetten we dan de scène voor dit?
Het Verkrijgen van Data voor een Aanval
Adversarial beelden zoals het ‘bloem’-voorbeeld hierboven worden gegenereerd door toegang te hebben tot de beeld datasets die de computermodellen hebben getraind. Je hebt geen ‘geprivilegieerde’ toegang tot trainingsdata (of modelarchitectuur) nodig, omdat de meest populaire datasets (en veel getrainde modellen) breed beschikbaar zijn in een robuust en constant bijgewerkt torrent-scene.
Als voorbeeld is de vermaarde reus van Computer Vision-datasets, ImageNet, beschikbaar via Torrent in alle zijn vele iteraties, waardoor het de gebruikelijke beperkingen omzeilt en cruciale secundaire elementen beschikbaar maakt, zoals validatiesets.

Bron: https://academictorrents.com
Als je de data hebt, kun je (zoals de onderzoekers van Adelaide opmerken) effectief ‘reverse-engineeren’ elke populaire dataset, zoals CityScapes, of CIFAR.
In het geval van PubFig, de dataset die het ‘Obama-bloem’-voorbeeld in het eerder genoemde voorbeeld mogelijk maakte, heeft Columbia University een groeiende trend in auteursrechtskwesties rondom beeld dataset-herdistributie aangepakt door onderzoekers te instrueren hoe ze de dataset kunnen reproduceren via gecureerde links, in plaats van de compilatie direct beschikbaar te stellen, waarbij wordt opgemerkt ‘Dit lijkt de manier te zijn waarop andere grote web-gebaseerde databases evolueren’.
Meestal is dat niet nodig: Kaggle schat dat de tien meest populaire beeld datasets in computerzicht zijn: CIFAR-10 en CIFAR-100 (beide direct te downloaden); CALTECH-101 en 256 (beide beschikbaar en beide momenteel beschikbaar als torrents); MNIST (officieel beschikbaar, ook op torrents); ImageNet (zie hierboven); Pascal VOC (beschikbaar, ook op torrents); MS COCO (beschikbaar, en op torrents); Sports-1M (beschikbaar); en YouTube-8M (beschikbaar).
Deze beschikbaarheid is ook representatief voor het bredere bereik van beschikbare computerzicht-beeld datasets, aangezien obscuriteit de dood is in een ‘publiceer of verdwijn’ open source-ontwikkelingscultuur.
In elk geval verergeren de schaarste aan beheersbare nieuwe datasets, de hoge kosten van beeldset-ontwikkeling, de afhankelijkheid van ‘oude favorieten’ en de neiging om oude datasets eenvoudig aan te passen het probleem dat in het nieuwe Adelaide-papier wordt geschetst.
Typische Kritiek op Adversarial Beeldaanval Methoden
De meest frequente en persistente kritiek van machine learning-engineers tegen de effectiviteit van de laatste adversarial beeldaanvaltechniek is dat de aanval specifiek is voor een bepaalde dataset, een bepaald model of beide; dat het niet ‘generaliseerbaar’ is naar andere systemen; en, gevolglijk, slechts een triviaal gevaar vertegenwoordigt.
De tweede meest voorkomende klacht is dat de adversarial beeldaanval ‘white box’ is, wat betekent dat je directe toegang tot de trainingsomgeving of data nodig hebt. Dit is inderdaad een onwaarschijnlijke scenario in de meeste gevallen – bijvoorbeeld, als je de trainingsprocessen voor de gezichtsherkenningssystemen van de Metropolitan Police van Londen wilde exploiteren, zou je moeten inbreken bij NEC, hetzij met een console of een bijl.
Het Langetermijn-‘DNA’ van Populaire Computerzicht Datasets
Met betrekking tot de eerste kritiek, zouden we moeten overwegen dat niet alleen een handvol computerzicht datasets de industrie jaarlijks domineert (d.w.z. ImageNet voor meerdere soorten objecten, CityScapes voor rijscènes en FFHQ voor gezichtsherkenning); maar ook dat, als eenvoudig geannoteerde beeldgegevens, ze ‘platform-agnostisch’ en zeer overdraagbaar zijn.
Afhankelijk van zijn mogelijkheden, zal elk computerzicht trainingsarchitectuur enkele kenmerken van objecten en klassen in de ImageNet-dataset vinden. Sommige architectuur kan meer kenmerken vinden dan andere, of meer nuttige verbindingen maken dan andere, maar alle zullen minstens de hoogste niveaukenmerken vinden:

ImageNet-gegevens, met het minimum aantal correcte identificaties – ‘hoog niveau’-kenmerken.
Het zijn die ‘hoog niveau’-kenmerken die een dataset onderscheiden en ‘fingerprinten’, en die de betrouwbare ‘haakjes’ zijn waarop een langetermijn-adversarial beeldaanvalmethodologie kan worden gebaseerd die verschillende systemen kan overspannen en kan groeien in tandem met de ‘oude’ dataset terwijl deze wordt voortgezet in nieuwe onderzoeken en producten.
Een meer geavanceerde architectuur zal meer accurate en gedetailleerde identificaties, kenmerken en klassen produceren:

Hoewel de meer een adversarial aanvalsgenerator afhankelijk is van deze lagere kenmerken (d.w.z. ‘Jonge blanke man’ in plaats van ‘Gezicht’), des te minder effectief zal het zijn in cross-over of latere architectuur die andere versies van de oorspronkelijke dataset gebruikt – zoals een subset of gefilterde set, waarin veel van de oorspronkelijke beelden uit de volledige dataset niet aanwezig zijn:

Adversarial Aanvallen op ‘Zeroed’, Pre-getrainde Modellen
Wat als je gewoon een pre-getraind model downloadt dat oorspronkelijk is getraind op een zeer populaire dataset, en je geeft het compleet nieuwe data?
Het model is al getraind op (bijvoorbeeld) ImageNet, en alles wat overblijft zijn de gewichten, die weken of maanden kunnen hebben geduurd om te trainen, en zijn nu klaar om je te helpen soortgelijke objecten te identificeren als die welke in de oorspronkelijke (nu afwezige) data bestonden.

Met de oorspronkelijke data verwijderd uit de trainingsarchitectuur, is wat overblijft de ‘voorkeur’ van het model om objecten te classificeren op de manier waarop het oorspronkelijk leerde te doen, wat essentieel zal zorgen dat veel van de oorspronkelijke ‘handtekeningen’ zich opnieuw vormen en opnieuw kwetsbaar worden voor dezelfde oude Adversarial Beeldaanvalmethoden.
Die gewichten zijn waardevol. Zonder de data of de gewichten, heb je eigenlijk een lege architectuur met geen data. Je zult het moeten trainen van scratch, met grote kosten van tijd en rekenbronnen, net zoals de oorspronkelijke auteurs deden (waarschijnlijk op krachtigere hardware en met een hoger budget dan je beschikbaar hebt).
Het probleem is dat de gewichten al behoorlijk goed gevormd en robuust zijn. Hoewel ze enigszins zullen aanpassen tijdens de training, zullen ze op je nieuwe data net zo gedragen als ze deden op de oorspronkelijke data, waardoor kenmerken ontstaan die een adversarial aanvalssysteem kan gebruiken.
In de langetermijn behoudt dit ook het ‘DNA’ van computerzicht datasets die twaalf of meer jaar oud zijn, en die mogelijk een opvallende evolutie hebben doorgemaakt van open source-inspanningen tot commerciële inzet – zelfs waar de oorspronkelijke trainingsdata volledig werd verwijderd aan het begin van het project. Sommige van deze commerciële inzetten kunnen pas over een aantal jaar plaatsvinden.
Geen Witte Doos Nodig
Met betrekking tot de tweede meest voorkomende kritiek op adversarial beeldaanvalsystemen, hebben de auteurs van het nieuwe papier ontdekt dat hun vermogen om herkenningssystemen te misleiden met gegenereerde beelden van bloemen zeer overdraagbaar is naar een aantal architectuur.
Terwijl ze opmerken dat hun ‘Universal NaTuralistic Adversarial Patches’ (TnT)-methode de eerste is die herkenbare beelden (in plaats van willekeurige perturbatieruis) gebruikt om beeldherkenningsystemen te misleiden, verklaren de auteurs ook:
‘[TnTs] zijn effectief tegen meerdere state-of-the-art classificatoren, variërend van de veelgebruikte WideResNet50 in de Large-Scale Visual Recognition-taak van ImageNet-dataset tot VGG-face-modellen in de gezichtsherkenningstaak van PubFig-dataset in zowel gerichte als ongerichte aanvallen.
‘TnTs kunnen bezitten: i) de naturaliteit die haalbaar is [met] triggers die worden gebruikt in Trojan-aanvalmethoden; en ii) de generaliseerbaarheid en overdraagbaarheid van adversarial voorbeelden naar andere netwerken.
‘Dit roept veiligheids- en beveiligingszorgen op met betrekking tot reeds geïmplementeerde DNN’s, evenals toekomstige DNN-implimentaties waar aanvallers onopvallende, natuurlijk lijkende objectpatches kunnen gebruiken om neurale netwerksystemen te misleiden zonder de modellen aan te passen en ontdekking te riskeren.’
De auteurs suggereren dat conventionele tegenmaatregelen, zoals het degraderen van de Clean Acc. van een netwerk, theoretsch kunnen voorzien in enige verdediging tegen TnT-patches, maar dat ‘TnTs nog steeds succesvol kunnen omzeilen deze SOTA-bewezen verdedigingsmethoden met de meeste van de verdedigende systemen die 0% Robuustheid bereiken’.
Mogelijke andere oplossingen zijn gedecentraliseerd leren, waarbij de herkomst van de bijdragende beelden wordt beschermd, en nieuwe benaderingen die data rechtstreeks kunnen ‘versleutelen’ tijdens de trainingsfase, zoals onlangs voorgesteld door de Nanjing University of Aeronautics and Astronautics.
Zelfs in die gevallen zou het belangrijk zijn om te trainen op echt nieuwe beeldgegevens – nu de beelden en bijbehorende annotaties in de kleine groep meest populaire CV-datasets zo diep verankerd zijn in ontwikkelingscycli over de hele wereld dat ze meer op software lijken dan op data; software die vaak niet noemenswaard is bijgewerkt in jaren.
Conclusie
Adversarial beeldaanvallen worden mogelijk gemaakt niet alleen door open source machine learning-praktijken, maar ook door een corporate AI-ontwikkelingscultuur die gemotiveerd is om bestaande computerzicht datasets opnieuw te gebruiken vanwege verschillende redenen: ze hebben al hun effectiviteit bewezen; ze zijn veel goedkoper dan ‘van scratch beginnen’; en ze worden onderhouden en bijgewerkt door toonaangevende geesten en organisaties in de academische en industriële wereld, op niveaus van financiering en personeel die moeilijk zijn na te bootsen door een enkel bedrijf.
Bovendien, in veel gevallen waar de data niet origineel is (in tegenstelling tot CityScapes), werden de beelden verzameld vóór recente controverse rondom privacy en dataverzameling, waardoor deze oude datasets in een soort semi-wettelijke limbo terechtkomen die eruitziet als een ‘veilige haven’ vanuit het oogpunt van een bedrijf.
TnT Aanvallen! Universele Naturalistische Adversarial Patches Tegen Diepe Neuronale Netwerk Systemen is mede geschreven door Bao Gia Doan, Minhui Xue, Ehsan Abbasnejad, Damith C. Ranasinghe van de University of Adelaide, samen met Shiqing Ma van de afdeling Computer Science van de Rutgers University.
Bijgewerkt op 1st december 2021, 7:06am GMT+2 – corrected typo.












