
Best Of
10 beste machine learning-algoritmen
Hoewel we een tijd beleven van buitengewone innovatie op het gebied van GPU-versneld machinaal leren, bevatten de nieuwste onderzoeksrapporten vaak (en prominent) algoritmen die tientallen jaren oud zijn, in sommige gevallen 70 jaar oud.
Sommigen zouden kunnen beweren dat veel van deze oudere methoden in het kamp van 'statistische analyse' vallen in plaats van machinaal leren, en geven er de voorkeur aan de komst van de sector terug te dateren tot in 1957, met de uitvinding van de Perceptron.
Gezien de mate waarin deze oudere algoritmen de nieuwste trends en baanbrekende ontwikkelingen op het gebied van machine learning ondersteunen en daarin verstrikt zijn geraakt, is het een betwistbaar standpunt. Laten we dus eens kijken naar enkele van de 'klassieke' bouwstenen die ten grondslag liggen aan de nieuwste innovaties, evenals enkele nieuwere inzendingen die een vroeg bod uitbrengen op de AI-hall of fame.
1: Transformatoren
In 2017 leidde Google Research een onderzoekssamenwerking die resulteerde in de papier Aandacht is alles wat je nodig hebt. Het werk schetste een nieuwe architectuur die gepromoot werd aandacht mechanismen van 'piping' in encoder/decoder en terugkerende netwerkmodellen tot een op zichzelf staande centrale transformationele technologie.
De aanpak werd nagesynchroniseerd Transformator, en is sindsdien uitgegroeid tot een revolutionaire methodologie in Natural Language Processing (NLP), die onder meer het autoregressieve taalmodel en AI-poster-kind GPT-3 aanstuurt.
![]()
Transformers losten op elegante wijze het probleem op van sequentie transductie, ook wel 'transformatie' genoemd, die zich bezighoudt met de verwerking van invoerreeksen in uitvoerreeksen. Een transformator ontvangt en beheert gegevens ook op een continue manier, in plaats van in opeenvolgende batches, waardoor een 'persistentie van het geheugen' mogelijk wordt gemaakt waarvoor RNN-architecturen niet zijn ontworpen. Voor een uitgebreider overzicht van transformatoren, kijk op ons referentieartikel.
In tegenstelling tot de Recurrent Neural Networks (RNNs) die in het CUDA-tijdperk het ML-onderzoek begonnen te domineren, kon de Transformer-architectuur ook gemakkelijk worden aangepast. parallel geschakeld, wat de weg vrijmaakte om op een productieve manier een veel groter corpus aan gegevens aan te pakken dan RNN's.
Populair gebruik
Transformers spraken in 2020 tot de publieke verbeelding met de release van OpenAI's GPT-3, met een toenmalig recordbrekend 175 miljard parameters. Deze ogenschijnlijk duizelingwekkende prestatie werd uiteindelijk overschaduwd door latere projecten, zoals de 2021 los van Microsoft's Megatron-Turing NLG 530B, die (zoals de naam al doet vermoeden) meer dan 530 miljard parameters bevat.

Een tijdlijn van hyperscale Transformer NLP-projecten. Bron: Microsoft
Transformer-architectuur is ook overgestapt van NLP naar computervisie, waardoor een nieuwe generatie van frameworks voor beeldsynthese, zoals OpenAI's CLIP en DALL-E, die tekst>afbeeldingsdomeintoewijzing gebruiken om onvolledige afbeeldingen te voltooien en nieuwe afbeeldingen van getrainde domeinen te synthetiseren, naast een groeiend aantal gerelateerde toepassingen.

DALL-E probeert een gedeeltelijk beeld van een buste van Plato te voltooien. Bron: https://openai.com/blog/dall-e/
2: Generatieve vijandige netwerken (GAN's)
Hoewel transformatoren buitengewone media-aandacht hebben gekregen door de release en acceptatie van GPT-3, de Generative Adversarial Network (GAN) is een op zichzelf staand herkenbaar merk geworden en kan zich uiteindelijk aansluiten deepfake als een werkwoord.
Eerst voorgesteld in 2014 en voornamelijk gebruikt voor beeldsynthese, een Generative Adversarial Network architectuur is samengesteld uit een Generator en discriminator. De generator bladert door duizenden afbeeldingen in een dataset en probeert ze iteratief te reconstrueren. Voor elke poging beoordeelt de Discriminator het werk van de Generator en stuurt de Generator terug om het beter te doen, maar zonder enig inzicht in de manier waarop de vorige reconstructie fout was.

Bron: https://developers.google.com/machine-learning/gan/gan_structure
Dit dwingt de generator om een veelheid aan wegen te verkennen, in plaats van de mogelijke doodlopende wegen te volgen die zouden zijn ontstaan als de discriminator hem had verteld waar het fout ging (zie #8 hieronder). Tegen de tijd dat de training voorbij is, heeft de Generator een gedetailleerde en uitgebreide kaart van relaties tussen punten in de dataset.

Van het papier GAN-evenwicht verbeteren door ruimtelijk bewustzijn te vergroten: een nieuw raamwerk fietst door de soms mysterieuze latente ruimte van een GAN en biedt responsieve instrumenten voor een architectuur voor beeldsynthese. Bron: https://genforce.github.io/eqgan/
Naar analogie is dit het verschil tussen het leren van een enkele alledaagse reis naar het centrum van Londen, of het nauwgezet verwerven De kennis.
Het resultaat is een verzameling functies op hoog niveau in de latente ruimte van het getrainde model. De semantische indicator voor een kenmerk op hoog niveau kan 'persoon' zijn, terwijl een afdaling door specificiteit gerelateerd aan het kenmerk andere aangeleerde kenmerken kan blootleggen, zoals 'mannelijk' en 'vrouwelijk'. Op lagere niveaus kunnen de subkenmerken uiteenvallen in 'blond', 'Kaukasisch', et al.
Verstrengeling is een opmerkelijke kwestie in de latente ruimte van GAN's en encoder/decoder-frameworks: is de glimlach op een door GAN gegenereerd vrouwelijk gezicht een verstrengeld kenmerk van haar 'identiteit' in de latente ruimte, of is het een parallelle vertakking?

GAN-gegenereerde gezichten van deze persoon bestaan niet. Bron: https://deze-persoon-niet-bestaat.com/en
De afgelopen paar jaar hebben in dit opzicht een groeiend aantal nieuwe onderzoeksinitiatieven voortgebracht, die misschien de weg hebben geëffend voor bewerken op functieniveau in Photoshop-stijl voor de latente ruimte van een GAN, maar op dit moment zijn veel transformaties effectief ' alles of niets' pakketten. Met name de EditGAN-release van NVIDIA van eind 2021 behaalt een hoge mate van interpreteerbaarheid in de latente ruimte door semantische segmentatiemaskers te gebruiken.
Populair gebruik
Naast hun (eigenlijk vrij beperkte) betrokkenheid bij populaire deepfake-video's, hebben GAN's die op afbeeldingen/video's zijn gericht, zich de afgelopen vier jaar verspreid, wat zowel onderzoekers als het publiek in de ban houdt. Het bijhouden van de duizelingwekkende snelheid en frequentie van nieuwe releases is een uitdaging, hoewel de GitHub-repository Geweldige GAN-applicaties streeft naar een uitgebreide lijst.
Generatieve Adversarial Networks kunnen in theorie kenmerken ontlenen aan elk goed ingekaderd domein, inclusief tekst.
3: SVM
Voortgekomen in 1963, Ondersteuning van Vector Machine (SVM) is een kernalgoritme dat regelmatig opduikt in nieuw onderzoek. Onder SVM brengen vectoren de relatieve plaatsing van datapunten in een dataset in kaart, terwijl ondersteuning vectoren schetsen de grenzen tussen verschillende groepen, kenmerken of eigenschappen.
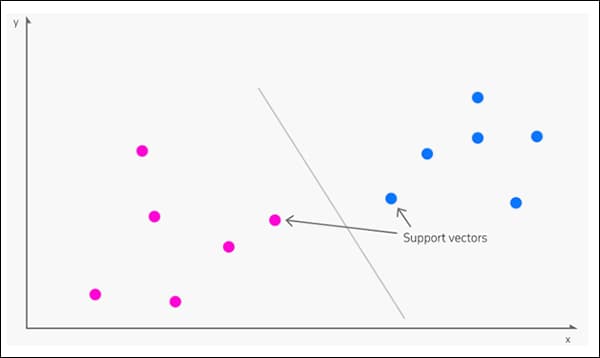
Ondersteuningsvectoren definiëren de grenzen tussen groepen. Bron: https://www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html
De afgeleide grens heet a hypervlak.
Op lage functieniveaus is de SVM dat wel tweedimensionaal (afbeelding hierboven), maar waar er een groter aantal groepen of typen wordt herkend, wordt het driedimensionaal.

Een diepere reeks punten en groepen vereist een driedimensionale SVM. Bron: https://cml.rhul.ac.uk/svm.html
Populair gebruik
Omdat ondersteunende vectormachines op effectieve en agnostische wijze allerlei soorten hoogdimensionale gegevens kunnen verwerken, duiken ze op grote schaal op in een verscheidenheid aan machine learning-sectoren, waaronder deepfake detectie, afbeelding classificatie, classificatie van haatspraak, DNA-analyse en voorspelling van de bevolkingsstructuur, Onder vele anderen.
4: K-betekent clustering
Clustering in het algemeen is een zonder toezicht leren benadering die datapunten probeert te categoriseren dichtheid schatting, een kaart maken van de verspreiding van de gegevens die worden bestudeerd.

K-Means clustert goddelijke segmenten, groepen en gemeenschappen in gegevens. Bron: https://aws.amazon.com/blogs/machine-learning/k-means-clustering-with-amazon-sagemaker/
K-Middelen Clustering is de meest populaire implementatie van deze benadering geworden, waarbij gegevenspunten worden ondergebracht in onderscheidende 'K-groepen', die demografische sectoren, online gemeenschappen of andere mogelijke geheime aggregaties kunnen aangeven die wachten om ontdekt te worden in ruwe statistische gegevens.

Clusters worden gevormd in K-Means-analyse. Bron: https://www.geeksforgeeks.org/ml-determine-the-optimal-value-of-k-in-k-means-clustering/
De K-waarde zelf is de bepalende factor in het nut van het proces en bij het vaststellen van een optimale waarde voor een cluster. Aanvankelijk wordt de K-waarde willekeurig toegewezen en worden de kenmerken en vectorkenmerken vergeleken met de buren. De buren die het meest lijken op het gegevenspunt met de willekeurig toegewezen waarde, worden iteratief aan het cluster toegewezen totdat de gegevens alle groeperingen hebben opgeleverd die het proces toestaat.
De plot voor de gekwadrateerde fout, of 'kosten' van verschillende waarden tussen de clusters, zal een onthullen elleboog punt voor de gegevens:

Het 'elleboogpunt' in een clustergrafiek. Bron: https://www.scikit-yb.org/en/latest/api/cluster/elbow.html
Het elleboogpunt is qua concept vergelijkbaar met de manier waarop verlies afvlakt tot afnemende opbrengsten aan het einde van een trainingssessie voor een dataset. Het vertegenwoordigt het punt waarop geen onderscheid meer tussen groepen zichtbaar zal worden, en geeft het moment aan om door te gaan naar de volgende fasen in de datapijplijn, of anders om bevindingen te rapporteren.
Populair gebruik
K-Means Clustering is, om voor de hand liggende redenen, een primaire technologie in klantanalyse, omdat het een duidelijke en verklaarbare methodologie biedt om grote hoeveelheden commerciële documenten te vertalen naar demografische inzichten en 'leads'.
Buiten deze applicatie wordt ook K-Means Clustering ingezet voorspelling van aardverschuivingen, medische beeldsegmentatie, beeldsynthese met GAN's, documentclassificatie en stadsplanning, naast vele andere mogelijke en daadwerkelijke toepassingen.
5: Willekeurig bos
Willekeurig Bos is een ensemble leren methode die het resultaat berekent van een reeks van Beslissingsbomen om een algemene voorspelling voor de uitkomst vast te stellen.

Bron: https://www.tutorialandexample.com/wp-content/uploads/2019/10/Decision-Trees-Root-Node.png
Als je het zelfs maar hebt onderzocht, kijk dan naar de Terug naar de toekomst trilogie is een beslisboom zelf vrij eenvoudig te conceptualiseren: er liggen een aantal paden voor je, en elk pad vertakt zich naar een nieuwe uitkomst die op zijn beurt verdere mogelijke paden bevat.
In versterking van leren, kunt u zich terugtrekken van een pad en opnieuw beginnen vanuit een eerder standpunt, terwijl beslissingsbomen zich vastleggen op hun reis.
Het Random Forest-algoritme is dus in wezen gespreid gokken voor beslissingen. Het algoritme wordt 'willekeurig' genoemd omdat het maakt ad hoc selecties en observaties om de mediaan som van de resultaten van de beslissingsboomarray.
Aangezien het rekening houdt met een veelheid aan factoren, kan een Random Forest-benadering moeilijker zijn om te zetten in zinvolle grafieken dan een beslissingsboom, maar is waarschijnlijk aanzienlijk productiever.
Beslissingsbomen zijn onderhevig aan overfitting, waarbij de verkregen resultaten gegevensspecifiek zijn en niet waarschijnlijk zullen generaliseren. De willekeurige selectie van datapunten door Random Forest bestrijdt deze neiging door door te boren naar zinvolle en bruikbare representatieve trends in de data.

Beslissingsboom regressie. Bron: https://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html
Populair gebruik
Zoals met veel van de algoritmen in deze lijst, werkt Random Forest doorgaans als een 'vroege' sorteerder en filter van gegevens, en duikt als zodanig consequent op in nieuwe onderzoeksdocumenten. Enkele voorbeelden van het gebruik van Random Forest zijn: Magnetische resonantie beeldsynthese, Prijsvoorspelling van Bitcoin, telling segmentatie, tekstclassificatie en detectie van creditcardfraude.
Aangezien Random Forest een low-level algoritme is in machine learning-architecturen, kan het ook bijdragen aan de prestaties van andere low-level methoden, evenals visualisatie-algoritmen, waaronder Inductieve clustering, Kenmerk transformaties, classificatie van tekstdocumenten schaarse functies gebruiken en Pijpleidingen weergeven.
6: Naïeve Bayes
In combinatie met dichtheidsschatting (zie 4, Boven een naïeve Bayes classifier is een krachtig maar relatief lichtgewicht algoritme dat kansen kan schatten op basis van de berekende kenmerken van gegevens.

Feature-relaties in een naïeve Bayes-classificatie. Bron: https://www.sciencedirect.com/topics/computer-science/naive-bayes-model
De term 'naïef' verwijst naar de veronderstelling in De stelling van Bayes dat functies niet gerelateerd zijn, bekend als voorwaardelijke onafhankelijkheid. Als je dit standpunt inneemt, is lopen en praten als een eend niet voldoende om vast te stellen dat we met een eend te maken hebben en worden er geen 'voor de hand liggende' aannames voortijdig aangenomen.
Dit niveau van academische en onderzoeksdiscipline zou overdreven zijn waar 'gezond verstand' beschikbaar is, maar het is een waardevolle standaard bij het doorzoeken van de vele dubbelzinnigheden en mogelijk niet-gerelateerde correlaties die kunnen bestaan in een dataset voor machine learning.
In een origineel Bayesiaans netwerk zijn functies onderhevig aan scorende functies, inclusief minimale beschrijvingslengte en Bayesiaanse score, wat beperkingen kan opleggen aan de gegevens in termen van de geschatte verbindingen die tussen de gegevenspunten worden gevonden en de richting waarin deze verbindingen stromen.
Een naïeve Bayes-classificator werkt daarentegen door aan te nemen dat de kenmerken van een bepaald object onafhankelijk zijn, en vervolgens de stelling van Bayes te gebruiken om de waarschijnlijkheid van een bepaald object te berekenen op basis van zijn kenmerken.
Populair gebruik
Naive Bayes-filters zijn goed vertegenwoordigd in ziektevoorspelling en documentcategorisering, spam filtering, sentiment classificatie, aanbevelingssystemen en fraude detectie, onder andere toepassingen.
7: K- Dichtstbijzijnde buren (KNN)
Voor het eerst voorgesteld door de US Air Force School of Aviation Medicine in 1951, en zich moeten aanpassen aan de state-of-the-art computerhardware uit het midden van de 20e eeuw, K-dichtstbijzijnde buren (KNN) is een gestroomlijnd algoritme dat nog steeds een prominente plaats inneemt in academische papers en onderzoeksinitiatieven op het gebied van machine learning in de particuliere sector.
KNN wordt wel 'de luie leerling' genoemd, omdat het een dataset uitputtend scant om de relaties tussen datapunten te evalueren, in plaats van de training van een volwaardig machine learning-model te vereisen.

Een KNN-groepering. Bron: https://scikit-learn.org/stable/modules/neighbors.html
Hoewel KNN architectonisch slank is, stelt de systematische aanpak ervan veel eisen aan lees-/schrijfbewerkingen, en het gebruik ervan in zeer grote datasets kan problematisch zijn zonder aanvullende technologieën zoals Principal Component Analysis (PCA), die complexe en grote datasets kan transformeren. naar binnen representatieve groeperingen die KNN met minder inspanning kan doorlopen.
A recente studie evalueerde de effectiviteit en zuinigheid van een aantal algoritmen die moesten voorspellen of een werknemer een bedrijf zal verlaten, en ontdekte dat de zeventigjarige KNN superieur bleef aan modernere kanshebbers in termen van nauwkeurigheid en voorspellende effectiviteit.
Populair gebruik
Ondanks al zijn populaire eenvoud van concept en uitvoering, is KNN niet blijven hangen in de jaren 1950 - het is aangepast in een meer op DNN gerichte aanpak in een voorstel uit 2018 van de Pennsylvania State University, en blijft een centraal proces in een vroeg stadium (of analytisch hulpmiddel na verwerking) in veel veel complexere machine learning-frameworks.
In verschillende configuraties is KNN gebruikt of voor online handtekeningverificatie, afbeelding classificatie, tekstmining, gewas voorspelling en gezichtsherkenning, naast andere toepassingen en integraties.

Een op KNN gebaseerd gezichtsherkenningssysteem in opleiding. Source: https://pdfs.semanticscholar.org/6f3d/d4c5ffeb3ce74bf57342861686944490f513.pdf
8: Markov-beslissingsproces (MDP)
Een wiskundig raamwerk geïntroduceerd door de Amerikaanse wiskundige Richard Bellman in 1957, Het Markov-beslissingsproces (MDP) is een van de meest elementaire blokken van versterking van leren architecturen. Een conceptueel algoritme op zich, het is aangepast in een groot aantal andere algoritmen en komt regelmatig terug in de huidige oogst van AI/ML-onderzoek.
MDP verkent een gegevensomgeving door de evaluatie van de huidige toestand (dwz 'waar' het zich in de gegevens bevindt) te gebruiken om te beslissen welk knooppunt van de gegevens vervolgens moet worden onderzocht.

Bron: https://www.sciencedirect.com/science/article/abs/pii/S0888613X18304420
Een standaard Markov-beslissingsproces zal prioriteit geven aan kortetermijnvoordelen boven meer wenselijke langetermijndoelstellingen. Om deze reden is het meestal ingebed in de context van een meer omvattende beleidsarchitectuur in versterkend leren, en is het vaak onderhevig aan beperkende factoren zoals verdisconteerde beloningen andere wijzigende omgevingsvariabelen die voorkomen dat het zich naar een onmiddellijk doel haast zonder rekening te houden met het bredere gewenste resultaat.
Populair gebruik
Het low-level concept van MDP is wijdverspreid in zowel onderzoek als actieve implementaties van machine learning. Er is voor voorgesteld IoT-beveiligingssystemen, vissen oogsten en marktvoorspelling.
Naast zijn duidelijke toepasbaarheid voor schaken en andere strikt sequentiële spellen, is MDP ook een natuurlijke kanshebber voor de procedurele training van robotsystemen, zoals we kunnen zien in de onderstaande video.

9: Term Frequentie-inverse documentfrequentie
Termijn Frequentie (TF) deelt het aantal keren dat een woord in een document voorkomt door het totale aantal woorden in dat document. Aldus het woord verzegelen die eenmaal in een artikel van duizend woorden voorkomt, heeft een termfrequentie van 0.001. Op zichzelf is TF grotendeels nutteloos als indicator van het belang van een term, vanwege het feit dat zinloze artikelen (zoals a, en, de en it) overheersen.
Om een zinvolle waarde voor een term te verkrijgen, berekent Inverse Document Frequency (IDF) de TF van een woord over meerdere documenten in een dataset, waarbij een lage beoordeling wordt toegekend aan een zeer hoge frequentie stopwoorden, zoals artikelen. De resulterende kenmerkvectoren worden genormaliseerd tot hele waarden, waarbij aan elk woord een passend gewicht wordt toegekend.

TF-IDF weegt de relevantie van termen op basis van frequentie in een aantal documenten, waarbij zeldzamer voorkomen een indicator van opvallendheid is. Bron: https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
Hoewel deze benadering voorkomt dat semantisch belangrijke woorden verloren gaan als uitschietersbetekent het omkeren van het frequentiegewicht niet automatisch dat het een laagfrequente term is niet een uitbijter, want sommige dingen zijn zeldzaam en waardeloos. Daarom zal een laagfrequente term zijn waarde moeten bewijzen in de bredere architectuurcontext door (zelfs met een lage frequentie per document) op te treden in een aantal documenten in de dataset.
Ondanks zijn leeftijd, TF-IDF is een krachtige en populaire methode voor initiële filterpassages in Natural Language Processing-frameworks.
Populair gebruik
Omdat TF-IDF op zijn minst een rol heeft gespeeld in de ontwikkeling van het grotendeels occulte PageRank-algoritme van Google in de afgelopen twintig jaar, is het uitgegroeid tot zeer breed aangenomen als een manipulatieve SEO-tactiek, ondanks John Mueller's 2019 ontkenning van het belang ervan voor de zoekresultaten.
Vanwege de geheimhouding rond PageRank is er geen duidelijk bewijs dat TF-IDF dat is niet momenteel een effectieve tactiek om hoger in de ranglijst van Google te komen. Brandgevaarlijk discussie onder IT-professionals wijst de laatste tijd op een algemeen begrip, correct of niet, dat termmisbruik nog steeds kan resulteren in verbeterde SEO-plaatsing (hoewel extra beschuldigingen van monopoliemisbruik en overmatige reclame vervagen de grenzen van deze theorie).
10: Stochastische gradiëntdaling
Stochastische gradiëntafdaling (SGD) is een steeds populairdere methode om de training van machine learning-modellen te optimaliseren.
Gradient Descent zelf is een methode om de verbetering die een model maakt tijdens de training te optimaliseren en vervolgens te kwantificeren.
In die zin geeft 'gradiënt' een helling naar beneden aan (in plaats van een op kleur gebaseerde gradatie, zie onderstaande afbeelding), waarbij het hoogste punt van de 'heuvel', aan de linkerkant, het begin van het trainingsproces vertegenwoordigt. In dit stadium heeft het model nog niet één keer alle gegevens gezien en heeft het nog niet genoeg geleerd over relaties tussen de gegevens om effectieve transformaties te produceren.

Een gradiëntafdaling tijdens een FaceSwap-trainingssessie. We kunnen zien dat de training in de tweede helft enige tijd op een plateau is gebleven, maar zich uiteindelijk heeft hersteld in de richting van een acceptabele convergentie.
Het laagste punt, aan de rechterkant, vertegenwoordigt convergentie (het punt waarop het model zo effectief mogelijk is onder de opgelegde beperkingen en instellingen).
De gradiënt fungeert als een record en voorspeller voor de ongelijkheid tussen het foutenpercentage (hoe nauwkeurig het model momenteel de gegevensrelaties in kaart heeft gebracht) en de gewichten (de instellingen die van invloed zijn op de manier waarop het model leert).
Deze voortgangsregistratie kan worden gebruikt om a leertempo schema, een automatisch proces dat de architectuur vertelt om gedetailleerder en nauwkeuriger te worden naarmate de vroege vage details transformeren in duidelijke relaties en mappings. Gradiëntverlies biedt in feite een just-in-time kaart van waar de training vervolgens heen moet gaan en hoe deze moet verlopen.
De innovatie van Stochastic Gradient Descent is dat het de parameters van het model bij elk trainingsvoorbeeld per iteratie bijwerkt, wat over het algemeen de reis naar convergentie versnelt. Door de komst van hyperscale datasets in de afgelopen jaren is SGD de laatste tijd steeds populairder geworden als een mogelijke methode om de daaruit voortvloeiende logistieke problemen aan te pakken.
Aan de andere kant heeft SGD negatieve implicaties voor functieschaling, en er zijn mogelijk meer iteraties nodig om hetzelfde resultaat te bereiken, wat extra planning en aanvullende parameters vereist, in vergelijking met reguliere Gradient Descent.
Populair gebruik
Vanwege de configureerbaarheid en ondanks de tekortkomingen is SGD het meest populaire optimalisatie-algoritme geworden voor het aanpassen van neurale netwerken. Een configuratie van SGD die dominant aan het worden is in nieuwe AI/ML research papers is de keuze van de Adaptive Moment Estimation (ADAM, geïntroduceerd in 2015) optimalisatie.
ADAM past het leertempo voor elke parameter dynamisch aan ('adaptief leertempo'), en neemt ook resultaten van eerdere updates op in de volgende configuratie ('momentum'). Bovendien kan het worden geconfigureerd om latere innovaties te gebruiken, zoals Nesterov-momentum.
Sommigen beweren echter dat het gebruik van momentum ADAM (en soortgelijke algoritmen) ook kan versnellen naar een suboptimale conclusie. Zoals met de meeste van de nieuwste ontwikkelingen in de onderzoekssector op het gebied van machine learning, is SGD een work in progress.
Voor het eerst gepubliceerd op 10 februari 2022. Gewijzigd op 10 februari 20.05 EET – opmaak.















