
Artificial Intelligence
RigNeRF: een nieuwe deepfakes-methode die gebruikmaakt van neurale stralingsvelden

Nieuw onderzoek ontwikkeld bij Adobe biedt de eerste levensvatbare en effectieve deepfakes-methode op basis van Neurale stralingsvelden (NeRF) – misschien wel de eerste echte innovatie in architectuur of aanpak in de vijf jaar sinds de opkomst van deepfakes in 2017.
De methode, getiteld RigNeRF, toepassingen 3D morphable gezichtsmodellen (3DMM's) als een interstitiële laag van instrumentaliteit tussen de gewenste invoer (dwz de identiteit die moet worden opgelegd in de NeRF-weergave) en de neurale ruimte, een methode die is ontwikkeld de laatste jaren breed gedragen door Generative Adversarial Network (GAN) gezichtssynthesebenaderingen, die nog geen enkele functionele en bruikbare kaders voor gezichtsvervanging voor video hebben opgeleverd.

In tegenstelling tot traditionele deepfake-video's is absoluut geen van de hier afgebeelde bewegende inhoud 'echt', maar eerder een verkenbare neurale ruimte die is getraind op korte beelden. Aan de rechterkant zien we het 3D morphable face model (3DMM) dat fungeert als een interface tussen de gewenste manipulaties ('glimlach', 'kijk naar links', 'kijk omhoog', etc.) en de doorgaans hardnekkige parameters van een neuraal stralingsveld visualisatie. Voor een hoge resolutie versie van deze clip, samen met andere voorbeelden, zie de project pagina, of de ingesloten video's aan het einde van dit artikel. Bron: https://shahrukhathar.github.io/2022/06/06/RigNeRF.html
3DMM's zijn in feite CGI-modellen van gezichten, waarvan de parameters kunnen worden aangepast aan meer abstracte beeldsynthesesystemen, zoals NeRF en GAN, die anders moeilijk te controleren zijn.
Wat je ziet in de afbeelding hierboven (middelste afbeelding, man in blauw shirt), evenals de afbeelding er direct onder (linkerafbeelding, man in blauw shirt), is geen 'echte' video waarin een klein stukje ' nep'-gezicht is over elkaar gelegd, maar een volledig gesynthetiseerde scène die uitsluitend bestaat als een volumetrische neurale weergave - inclusief het lichaam en de achtergrond:

In het voorbeeld direct hierboven wordt de real-life video aan de rechterkant (vrouw in rode jurk) gebruikt om de vastgelegde identiteit (man in blauw shirt) aan de linkerkant te 'poppen' via RigNeRF, wat (volgens de auteurs) de eerste is NeRF-gebaseerd systeem om de scheiding van pose en expressie te bereiken en tegelijkertijd nieuwe weergavesyntheses uit te voeren.
De mannelijke figuur links in de bovenstaande afbeelding is 'vastgelegd' op een smartphonevideo van 70 seconden en de invoergegevens (inclusief de volledige scène-informatie) zijn vervolgens getraind over 4 V100 GPU's om de scène te verkrijgen.
Aangezien parametrische rigs in 3DMM-stijl ook verkrijgbaar zijn als parametrische CGI-proxy's voor het hele lichaam (in plaats van alleen face-rigs), opent RigNeRF mogelijk de mogelijkheid van full-body deepfakes waarbij echte menselijke bewegingen, textuur en expressie worden doorgegeven aan de CGI-gebaseerde parametrische laag, die vervolgens actie en expressie zou vertalen in gerenderde NeRF-omgevingen en video's .
Wat betreft RigNeRF: komt het in aanmerking als een deepfake-methode in de huidige zin dat de krantenkoppen de term begrijpen? Of is het gewoon weer een semi-hobbled die ook naar DeepFaceLab en andere arbeidsintensieve deepfake-systemen uit het 2017-tijdperk met auto-encoder liep?
De onderzoekers van het nieuwe artikel zijn op dit punt ondubbelzinnig:
'Omdat het een methode is die gezichten kan reanimeren, is RigNeRF vatbaar voor misbruik door slechte acteurs om deep-fakes te genereren.'
De nieuwe papier is getiteld RigNeRF: volledig bestuurbare neurale 3D-portretten, en komt van ShahRukh Atha van Stonybrook University, een stagiair bij Adobe tijdens de ontwikkeling van RigNeRF, en vier andere auteurs van Adobe Research.
Voorbij op auto-encoder gebaseerde deepfakes
De meeste virale deepfakes die de afgelopen jaren de krantenkoppen hebben gehaald, zijn geproduceerd door auto-encoder-gebaseerde systemen, afgeleid van de code die werd gepubliceerd op de prompt verboden subreddit r/deepfakes in 2017 – maar niet voordat gekopieerd naar GitHub, waar het momenteel is gevorkt meer dan duizend keer, niet in de laatste plaats in de populaire (if controversieel) DeepFaceLab distributie, en ook de gezicht wisselen project.
Naast GAN en NeRF hebben autoencoder-frameworks ook geëxperimenteerd met 3DMM's als 'richtlijnen' voor verbeterde frameworks voor gezichtssynthese. Een voorbeeld hiervan is de HifiFace-project vanaf juli 2021. Tot op heden lijken er vanuit deze aanpak echter geen bruikbare of populaire initiatieven te zijn ontstaan.
Gegevens voor RigNeRF-scènes worden verkregen door korte smartphonevideo's vast te leggen. Voor het project gebruikten de onderzoekers van RigNeRF een iPhone XR of een iPhone 12 voor alle experimenten. Tijdens de eerste helft van de opname wordt het onderwerp gevraagd een breed scala aan gezichtsuitdrukkingen en spraak uit te voeren terwijl het hoofd stil blijft terwijl de camera om hem heen beweegt.
Voor de tweede helft van de opname behoudt de camera een vaste positie terwijl het onderwerp zijn hoofd moet bewegen terwijl hij een breed scala aan uitdrukkingen vertoont. De resulterende 40-70 seconden aan beeldmateriaal (ongeveer 1200-2100 frames) vertegenwoordigen de volledige dataset die zal worden gebruikt om het model te trainen.
Minder gegevens verzamelen
Autoencoder-systemen zoals DeepFaceLab daarentegen vereisen de relatief moeizame verzameling en curatie van duizenden verschillende foto's, vaak afkomstig van YouTube-video's en andere socialemediakanalen, evenals uit films (in het geval van deepfakes van beroemdheden).
De resulterende getrainde autoencoder-modellen zijn vaak bedoeld om in verschillende situaties te worden gebruikt. De meest kieskeurige 'celebrity'-deepfakers kunnen echter hele modellen vanaf het begin trainen voor een enkele video, ondanks het feit dat de training een week of langer kan duren.
Ondanks de waarschuwing van de onderzoekers van het nieuwe artikel, lijkt het onwaarschijnlijk dat de 'lappendeken' en breed samengestelde datasets die AI-porno aandrijven, evenals populaire YouTube/TikTok 'deepfake-herschikkingen' acceptabele en consistente resultaten opleveren in een deepfake-systeem zoals RigNeRF, die een scènespecifieke methodologie heeft. Gezien de beperkingen op het vastleggen van gegevens die in het nieuwe werk worden geschetst, zou dit tot op zekere hoogte een extra bescherming kunnen zijn tegen toevallige verduistering van identiteit door kwaadwillende deepfakers.
NeRF aanpassen aan Deepfake Video
NeRF is een op fotogrammetrie gebaseerde methode waarbij een klein aantal bronfoto's, genomen vanuit verschillende standpunten, worden samengevoegd tot een verkenbare 3D neurale ruimte. Deze aanpak kwam eerder dit jaar op de voorgrond toen NVIDIA haar onthulde Onmiddellijke NeRF systeem, in staat om de exorbitante trainingstijden voor NeRF terug te brengen tot minuten of zelfs seconden:

Onmiddellijke NeRF. Bron: https://www.youtube.com/watch?v=DJ2hcC1orc4
De resulterende Neural Radiance Field-scène is in wezen een statische omgeving die kan worden verkend, maar die dat ook is moeilijk te bewerken. De onderzoekers merken op dat twee eerdere op NeRF gebaseerde initiatieven - HyperNeRF + E/P en NerFACE – hebben een poging gedaan tot videosynthese van het gezicht en (blijkbaar voor de volledigheid en toewijding) hebben RigNeRF in een testronde tegen deze twee kaders geplaatst:


Een kwalitatieve vergelijking tussen RigNeRF, HyperNeRF en NerFACE. Zie de gekoppelde bronvideo's en pdf voor versies van hogere kwaliteit. Statische afbeeldingsbron: https://arxiv.org/pdf/2012.03065.pdf
In dit geval zijn de resultaten, die in het voordeel zijn van RigNeRF, echter nogal abnormaal, en wel om twee redenen: ten eerste merken de auteurs op dat 'er geen bestaand werk is voor een vergelijking van appel met appel'; ten tweede heeft dit de beperking van de mogelijkheden van RigNeRF noodzakelijk gemaakt om ten minste gedeeltelijk overeen te komen met de meer beperkte functionaliteit van de eerdere systemen.
Aangezien de resultaten geen incrementele verbetering zijn ten opzichte van eerder werk, maar eerder een 'doorbraak' vertegenwoordigen in de bewerkbaarheid en bruikbaarheid van NeRF, laten we de testronde buiten beschouwing en kijken we in plaats daarvan wat RigNeRF anders doet dan zijn voorgangers.
Gecombineerde sterke punten
De primaire beperking van NerFACE, dat pose-/expressiecontrole in een NeRF-omgeving kan creëren, is dat ervan wordt uitgegaan dat bronmateriaal wordt vastgelegd met een statische camera. Dit betekent in feite dat het geen nieuwe weergaven kan produceren die verder reiken dan de opnamebeperkingen. Dit levert een systeem op dat 'bewegende portretten' kan maken, maar dat niet geschikt is voor video in deepfake-stijl.
HyperNeRF, aan de andere kant, kan weliswaar nieuwe en hyperrealistische weergaven genereren, maar heeft geen instrument waarmee het hoofdhoudingen of gezichtsuitdrukkingen kan veranderen, wat opnieuw niet resulteert in enige vorm van concurrent voor op auto-encoder gebaseerde deepfakes.
RigNeRF kan deze twee geïsoleerde functionaliteiten combineren door een 'canonieke ruimte' te creëren, een standaard basislijn van waaruit afwijkingen en vervormingen kunnen worden ingevoerd via input van de 3DMM-module.
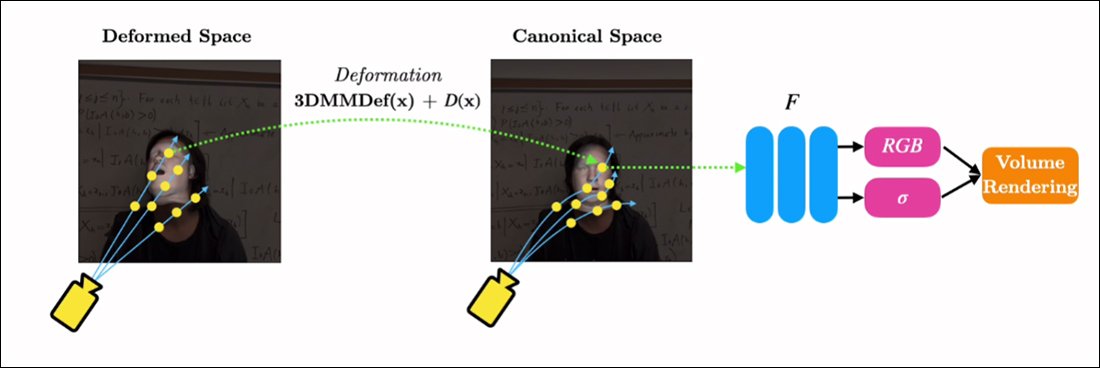
Het creëren van een 'canonieke ruimte' (geen pose, geen expressie), waarop de vervormingen (dwz poses en expressies) geproduceerd via de 3DMM kunnen inwerken.
Aangezien het 3DMM-systeem niet exact zal worden afgestemd op het vastgelegde onderwerp, is het belangrijk om dit tijdens het proces te compenseren. RigNeRF bereikt dit met een voorafgaand vervormingsveld dat wordt berekend op basis van a Meerlagige Perceptron (MLP) afgeleid van de bronbeelden.

De cameraparameters die nodig zijn om vervormingen te berekenen, worden verkregen via COLMAP, terwijl de expressie- en vormparameters voor elk frame worden verkregen uit VAN DIE.
De positionering wordt verder geoptimaliseerd door mijlpaal montage en de cameraparameters van COLMAP, en vanwege beperkingen op het gebied van computerbronnen wordt de video-uitvoer gedownsampled naar een resolutie van 256 × 256 voor training (een door hardware beperkt krimpproces dat ook de deepfaking-scène van de autoencoder teistert).
Hierna wordt het vervormingsnetwerk getraind op de vier V100's – formidabele hardware die waarschijnlijk niet binnen het bereik van gewone enthousiastelingen zal liggen (maar als het om machine learning-training gaat, is het vaak mogelijk om gewicht in te ruilen voor tijd en dat model eenvoudigweg te accepteren training zal een kwestie van dagen of zelfs weken zijn).
Concluderend stellen de onderzoekers:
'In tegenstelling tot andere methoden is RigNeRF, dankzij het gebruik van een 3DMM-geleide vervormingsmodule, in staat om hoofdhouding, gezichtsuitdrukkingen en de volledige 3D-portretscène met hoge getrouwheid te modelleren, waardoor betere reconstructies met scherpe details worden verkregen.'
Zie de ingesloten video's hieronder voor meer details en beeldmateriaal van de resultaten.


Voor het eerst gepubliceerd op 15 juni 2022.















